笔记|生成模型(十二):Normalizing Flow理论与实现
Normalizing flow(标准化流)是一类对概率分布进行建模的工具,它能完成简单的概率分布(例如高斯分布)和任意复杂分布之间的相互转换,经常被用于 data generation、density estimation、inpainting 等任务中,例如 Stability AI 提出的 Stable Diffusion 3 中用到的 rectified flow 就是 normalizing flow 的变体之一。
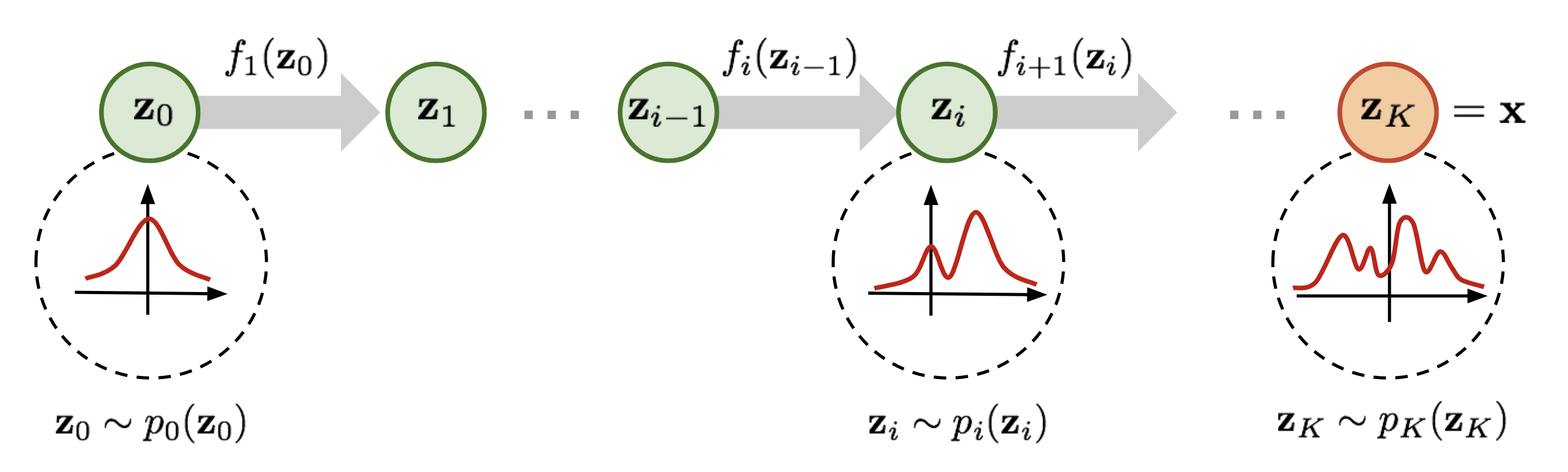
为了便于理解,在正式开始介绍之前先简要说明一下 normalizing flow 的做法。如上图所示,为了将一个高斯分布 \(z_0\) 转换为一个复杂的分布 \(z_K\),normalizing flow 会对初始的分布 \(z_0\) 进行多次可逆的变换,将其逐渐转换为 \(z_K\)。由于每一次变换都是可逆的,从 \(z_K\) 出发也能得到高斯分布 \(z_0\)。这样,我们就实现了复杂分布与高斯分布之间的互相转换,从而能从简单的高斯分布建立任意复杂分布。
对 diffusion models 比较熟悉的读者可能已经发现了,这个过程和 diffusion 的做法非常相似。在 diffusion model 中,对于一个从高斯分布中采样出的样本,模型也是通过一系列去噪过程,从而获得目标样本;同样也可以通过其逆过程从一个确定的样本通过加噪得到高斯噪声。这两者的确有一些相似之处,可以放到一起来了解。
概率密度映射的推导
因为 normalizing flow 构建复杂分布主要依靠概率分布的可逆映射,因此需要首先推导在映射的过程中,概率密度会发生怎样的变化。为了导出最终的结论,一个需要了解的概念是 Jacobian 矩阵,对于一个将 \(n\) 维向量变化为一个 \(m\) 维向量的变换 \(\mathbf{f}:\mathbb{R}^n\rightarrow\mathbb{R}^m\),其全部一阶偏导数构成的矩阵即为 Jacobian 矩阵 \(\mathbf{J}\): \[ \mathbf{J}=\begin{pmatrix} \frac{\partial f_1}{\partial x_1} & \cdots & \frac{\partial f_1}{\partial x_n} \\\\ \vdots & \ddots & \vdots \\\\ \frac{\partial f_m}{\partial x_1} & \cdots & \frac{\partial f_m}{\partial x_n} \end{pmatrix}. \]
对于给定的随机变量 \(z\) 以及其概率密度函数 \(z\sim\pi(z)\),构造一个双射 \(x=f(z)\),则同时也有 \(z=f^{-1}(x)\),下面我们来计算 \(x\) 的概率密度函数 \(p(x)\)。根据概率密度函数的定义,有: \[ \int p(x)\mathrm{d}x=\int\pi(z)\mathrm{d}z=1, \]
由于 \(x\) 和 \(z\) 满足双射,则任意 \(\mathrm{d}z\) 体积内包含的概率与其映射到的 \(\mathrm{d}x\) 内包含的概率是相等的,且概率密度处处大于 0,据此可以根据变量替换定理推导: \[ p(x)=\pi(z)\left|\frac{\mathrm{d}z}{\mathrm{d}x}\right|=\pi(f^{-1}(x))\left|\frac{\mathrm{d}f^{-1}}{\mathrm{d}x}\right|=\pi(f^{-1}(x))\left|(f^{-1})'(x)\right|. \]
对于高维随机变量 \(\mathbf{z}\sim\pi(\mathbf{z}),\ \mathbf{z}\in\mathbb{R}^n\) 以及多元函数 \(\mathbf{f}:\mathbb{R}^n\rightarrow\mathbb{R}^n\),也可以推导出类似的结论: \[ p(\mathbf{x})=\pi(\mathbf{z})\left|\mathrm{det}\ \frac{\mathrm{d}\mathbf{z}}{\mathrm{d}\mathbf{x}}\right|=\pi(\mathbf{f}^{-1}(\mathbf{x}))\left|\mathrm{det}\ \mathbf{J}(\mathbf{f}^{-1}(\mathbf{x}))\right|. \]
可以发现,对于已知的概率分布与双射,我们可以用一个带有 Jacobian 矩阵的式子来表示映射后的概率分布。我们可以从下面这个直观的例子来理解 Jacobian 矩阵在这里表示的含义:\(X_0\) 和 \(X_1\) 是两个随机变量,且满足 \(X_1=2X_0+2\),由于 \(X_0\) 的概率密度在 \((0,1)\) 间均匀分布,根据概率密度的性质,可知其概率密度处处为 1。对于 \(X_1\) 来说,其定义域是将 \(X_0\) 的定义域均匀扩大 2 倍得到的,那么其概率密度也应当减半。
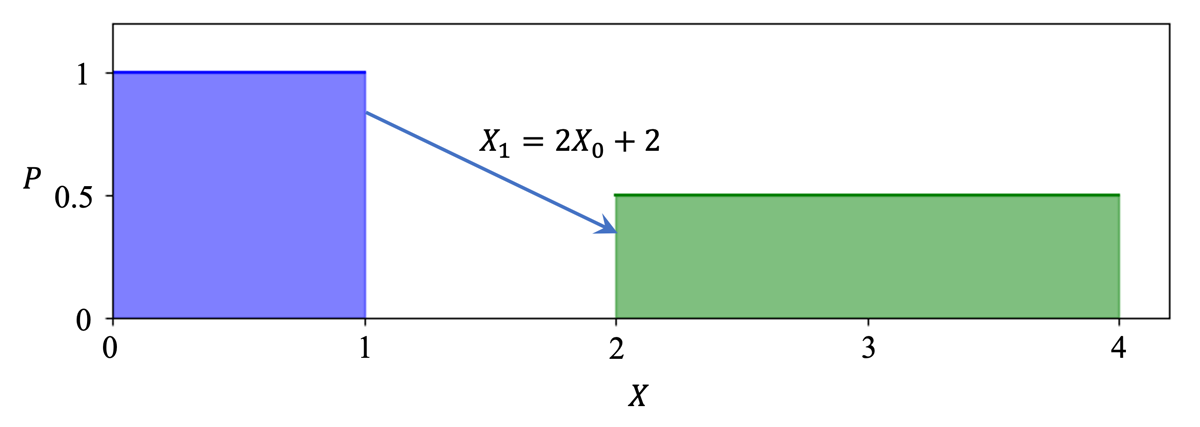
通过这个例子,可以对简单地理解 \(p(x)=\pi(f^{-1}(x))\left|(f^{-1})'(x)\right|\) 这一公式中 \(\left|(f^{-1})'(x)\right|\) 一项的含义:对于一个概率分布,其「单位体积」内所包含的概率是一定的,如果映射后「单位体积」的大小发生了变化,那么其概率密度也要相应地作出变化,来保证所含的概率不变。而且值得注意的是,在这个过程中我们只关心变化率的大小,而不关心变化率的方向(也就是导数的正负),因此这一项需要取绝对值。
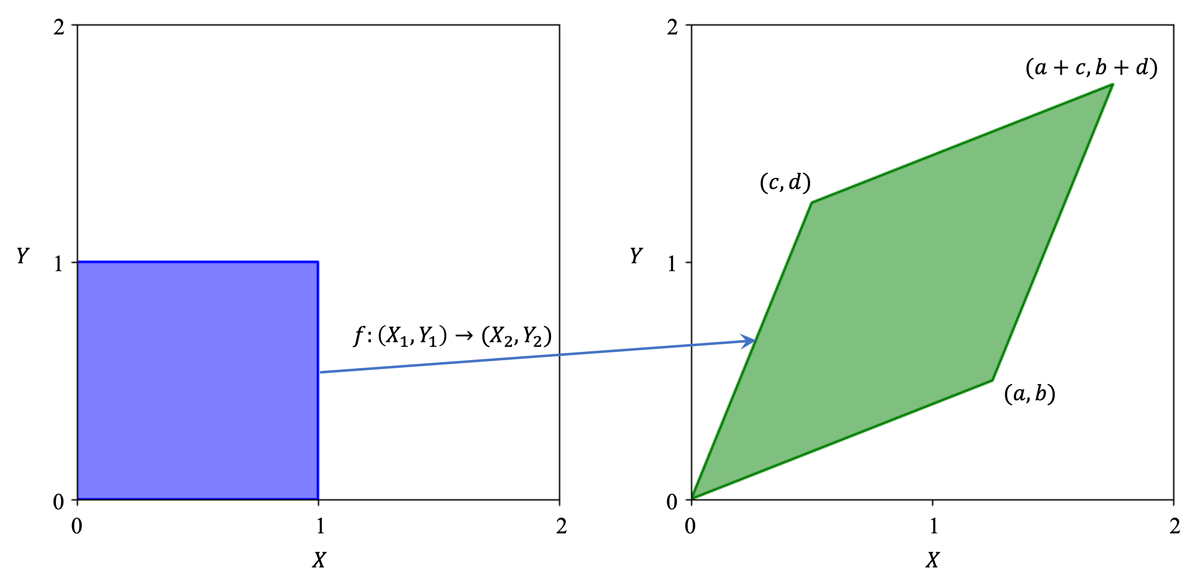
再举一个稍微复杂一点的例子:下图中蓝色的是在二维空间中均匀分布的二维随机变量 \((X_1, Y_1)\),可逆映射 \(f\) 将其映射到 \((X_2, Y_2)\)。我们不难得知代表 \(f\) 的变换矩阵就是 \(T=[[a,b];[c,d]]\),通过左乘 \(T\) 可以将任意 \((X_1,Y_1)\) 转换为对应的 \((X_2,Y_2)\)。与上一个例子同理,\((X_1,Y_1)\) 的概率密度处处为 1,而 \((X_2,Y_2)\) 的概率密度则需要用 1 除以绿色平行四边形的面积,即 \(ad-bc\)。这个值同时也是变换矩阵 \(T\) 的行列式的值,由此我们可以发现,Jacobian 矩阵的行列式的绝对值就是概率密度的变化率。
回到 Normalizing Flow
现在我们已经推导出概率密度的映射关系,那么 normalizing flow 的做法就已经呼之欲出了。回到文章最开始的示意图,对于一个高斯分布 \(z_0\),我们可以通过一系列双射 \(f_1,...,f_K\) 对其进行变换,得到任意分布 \(z_K\),在这个分布里采样得到样本,就完成了生成的过程。在这一过程中,由概率密度变换公式两边取对数,可以得到:
\[ \begin{align*} p_i(\mathbf{z}_i)&=p_{i-1}(\mathbf{z}_{i-1}) \left| \mathrm{det} \frac{\mathrm{d}f_i}{\mathrm{d}\mathbf{z}_{i-1}} \right|^{-1} \\ \log p_i(\mathbf{z}_i)&=\log p_{i-1}(\mathbf{z}_{i-1}) - \log \left| \mathrm{det} \frac{\mathrm{d}f_i}{\mathrm{d}\mathbf{z}_{i-1}} \right| \end{align*} \]
将一系列这样的映射耦合起来,有 \(\mathbf{x}=\mathbf{z}_K=f_K\circ f_{K-1}\circ\cdots\circ f_1(\mathbf{z}_0)\),那么 \(p(\mathbf{x})\) 可以由下式求得:
\[ \log p(\mathbf{x})=\log \pi_0(\mathbf{z}_0)-\sum_{i=1}^K\log\left|\mathrm{det}\ \frac{\mathrm{d}f_i}{\mathrm{d}\mathbf{z}_{i-1}}\right| \]
这样一系列变换耦合的过程就是 flow,由于最终得到的是标准正态分布,所以是 normalizing flow。同时,基于上述描述,我们也可以得知变换 \(f\) 应该有以下两个性质:
- 其逆变换应当容易求得
- 其 Jacobian 矩阵的行列式应当容易求得
常见的Normalizing Flow模型
Coupling Layers
Coupling Layers是Normalizing Flow中最常用的构建块之一,它将输入向量分为两部分,只对其中一部分进行变换,这样可以保证变换的可逆性。
对于输入向量 \(\mathbf{x} = [\mathbf{x}_1, \mathbf{x}_2]\),coupling layer的变换定义为: \[ \begin{aligned} \mathbf{y}_1 &= \mathbf{x}_1 \\ \mathbf{y}_2 &= \mathbf{x}_2 \odot \exp(s(\mathbf{x}_1)) + t(\mathbf{x}_1) \end{aligned} \]
其中 \(s(\cdot)\) 和 \(t(\cdot)\) 是神经网络,\(\odot\) 表示逐元素乘法。
优点:
- 变换的可逆性容易保证
- Jacobian矩阵的行列式计算简单:\(\det J = \exp(\sum_i s_i(\mathbf{x}_1))\)
Autoregressive Flows
自回归流通过自回归的方式对每个维度进行变换: \[ y_i = x_i \cdot \exp(s_i(x_{1:i-1})) + t_i(x_{1:i-1}) \]
其中 \(s_i\) 和 \(t_i\) 是只依赖于前 \(i-1\) 个维度的函数。
特点:
- Jacobian矩阵是下三角矩阵,行列式计算高效
- 表达能力强,但采样需要顺序进行
Continuous Normalizing Flows (CNF)
连续标准化流使用神经常微分方程(Neural ODE)来定义连续的变换: \[ \frac{d\mathbf{z}}{dt} = f(\mathbf{z}(t), t; \theta) \]
其中 \(f\) 是神经网络参数化的向量场。
训练Normalizing Flow
最大似然估计
Normalizing Flow的训练目标是最大化数据的对数似然: \[ \mathcal{L} = \mathbb{E}_{\mathbf{x} \sim p_{data}}[\log p(\mathbf{x})] \]
根据变量变换公式: \[ \log p(\mathbf{x}) = \log \pi(\mathbf{z}) + \sum_{i=1}^K \log \left|\det \frac{\partial f_i}{\partial \mathbf{z}_{i-1}}\right| \]
其中 \(\mathbf{z} = f^{-1}(\mathbf{x})\),\(\pi(\mathbf{z})\) 是基础分布(通常是标准高斯分布)。
训练算法
1 | def train_normalizing_flow(model, data_loader, optimizer, epochs): |
代码这里假设基础分布log_prob_z是 标准正态分布 \(\mathcal{N}(0, I)\):
\[ p(z) = \frac{1}{(2\pi)^{d/2}} \exp\left(-\frac{1}{2}\|z\|^2\right) \]
取对数得到: \[ \log p(z) = -\frac{1}{2} \|z\|^2 - \frac{d}{2}\log(2\pi) \]
其中 \(d\) 是数据维度,对应代码中的
z.shape[1]。
代码实现: 1
log_prob_z = -0.5 * torch.sum(z**2, dim=1) - 0.5 * z.shape[1] * torch.log(2 * torch.pi)
代码与公式的对应关系:
torch.sum(z**2, dim=1)↔︎ \(\|z\|^2\) (向量的平方和)-0.5 * z.shape[1] * torch.log(2 * torch.pi)↔︎ \(-\frac{d}{2}\log(2\pi)\) (归一化常数)
1 | # 计算总的对数似然 |
这行代码实现了变量替换公式(Change of Variables Formula):
\[ \log p(x) = \log p(z) + \log \left| \det \frac{\partial f}{\partial x} \right| \]
公式解释:
- \(\log p(x)\):目标分布 \(x\) 的对数概率密度
- \(\log p(z)\):基础分布 \(z\)
的对数概率密度(
log_prob_z) - \(\log \left| \det \frac{\partial
f}{\partial x}
\right|\):雅可比行列式的对数(
log_det_jacobian)
物理意义:
log_prob_z:衡量变换后的 \(z\) 在基础分布中的"合理性"log_det_jacobian:补偿变换过程中的"体积变化",确保概率密度的正确性
采样过程
从训练好的Normalizing Flow中采样非常直接:
- 从基础分布采样:\(\mathbf{z} \sim \pi(\mathbf{z})\)
- 通过逆变换得到样本:\(\mathbf{x} = f(\mathbf{z})\)
1 | def sample_from_flow(model, num_samples): |
这里不同的流模型对应不同的inverse方法: ### 1. Affine Coupling Layer (RealNVP/MAF 常用)
公式 给定输入 \(\mathbf{x} = (x_a, x_b)\),用神经网络预测变换参数:
\[ y_a = x_a, \quad y_b = x_b \cdot \exp(s(x_a)) + t(x_a) \]
其中:
- \(s(\cdot)\):scale 网络
- \(t(\cdot)\):translation 网络
逆变换:
\[ x_a = y_a, \quad x_b = (y_b - t(y_a)) \cdot \exp(-s(y_a)) \]
1 | class AffineCoupling(Flow): |
2. Planar Flow
公式
\[ f(z) = z + u \cdot h(w^\top z + b) \]
- \(h\):激活函数(如 \(\tanh\))
逆变换: Planar Flow 通常 不是解析可逆,只能通过数值方法(比如 Newton-Raphson)求解 \(x\)。 因此这种 flow 采样效率差。
3. Invertible Linear Layer (Glow)
公式
\[ y = Wx \]
其中 \(W\) 是可逆矩阵(通常用 LU 分解保证可逆)。
逆变换:
\[ x = W^{-1} y \]
代码:
1 | class InvertibleLinear(nn.Module): |
你可以多个flow组合使用,如果你有多个 flow block 组成的模型(比如 RealNVP/Glow)
训练时:
1 | z, log_det = x, 0 |
采样时:
1 | x = z |
与扩散模型的关系
Normalizing Flow和扩散模型在某些方面有相似性:
| 特性 | Normalizing Flow | 扩散模型 |
|---|---|---|
| 变换方式 | 可逆的确定性变换 | 随机的加噪/去噪过程 |
| 训练目标 | 最大似然估计 | 变分下界优化 |
| 采样速度 | 快(一次前向传播) | 慢(多步迭代) |
| 表达能力 | 受限于可逆性约束 | 更强的表达能力 |
近年来,研究者们开始探索将两者结合的方法,如Rectified Flow和Flow Matching,这些方法试图结合两者的优点。
实际应用
图像生成
Normalizing Flow在图像生成中的应用包括:
- Glow:使用多尺度架构和可逆1x1卷积
- Flow++:改进的coupling layers和自回归结构
变分推断
在变分推断中,Normalizing Flow可以用来构造更复杂的变分分布: \[ q_\phi(\mathbf{z}|\mathbf{x}) = q_0(\mathbf{z}_0) \prod_{i=1}^K \left|\det \frac{\partial f_i}{\partial \mathbf{z}_{i-1}}\right|^{-1} \]
密度估计
Normalizing Flow可以直接计算数据的概率密度,这在异常检测等任务中很有用。
优缺点分析
优点
- 精确的似然计算:可以直接计算数据的概率密度
- 快速采样:采样只需要一次前向传播
- 理论基础扎实:基于严格的数学理论
缺点
- 架构限制:必须保证变换的可逆性
- 表达能力受限:相比于其他生成模型,表达能力可能不足
- 训练困难:需要仔细设计网络架构以保证数值稳定性
总结
Normalizing Flow作为一类重要的生成模型,通过可逆变换实现了简单分布到复杂分布的映射。虽然在表达能力上可能不如扩散模型,但其精确的似然计算和快速采样的特性使其在特定应用场景中仍有重要价值。随着Flow Matching等新方法的出现,Normalizing Flow的思想正在与其他生成模型相结合,展现出新的发展前景。
参考资料: