笔记|生成模型(十四):Stable Diffusion 3 架构解析 (MMDiT)
本文为系列第十四篇。在介绍了 Flow Matching 之后,我们来看看它是如何在现代大模型中落地的。Stable Diffusion 3 (SD3) 是 Stability AI 推出的新一代图像生成模型,它不仅采用了 Flow Matching 作为训练目标,还在架构上进行了重大革新,提出了 MMDiT (Multimodal Diffusion Transformer)。本文将深入解析 SD3 的核心架构。
从 U-Net 到 DiT 的演进
在 SD 1.5 和 SDXL 时代,扩散模型的主力骨干网络一直是 U-Net。U-Net 通过下采样和上采样结合跳跃连接,在图像特征提取上表现出色。然而,随着模型规模的扩大,U-Net 的扩展性(Scaling Law)遇到了瓶颈。
与此同时,Transformer 在自然语言处理(NLP)领域大放异彩。Peebles 和 Xie 提出的 DiT (Diffusion Transformer) 证明了 Transformer 同样可以作为扩散模型的骨干网络,并且具有更好的扩展性。
SD3 彻底抛弃了 U-Net,全面拥抱 Transformer 架构。但 SD3 并没有直接使用原始的 DiT,而是针对文本-图像的多模态对齐问题,设计了全新的 MMDiT (Multimodal Diffusion Transformer)。
MMDiT 架构详解
在文本到图像生成中,模型需要同时处理两种截然不同的模态:
- 文本(Text):由 Prompt 经过文本编码器(如 CLIP, T5)提取的特征序列。
- 图像(Image):由 VAE 编码器提取的图像潜变量(Latent),加上噪声后展平为序列。
以往的模型(如 SDXL)通常使用交叉注意力机制(Cross-Attention),将文本特征作为 Key 和 Value 注入到图像特征的查询(Query)中。这种方式虽然有效,但文本和图像的特征表示被强制映射到了同一个空间,限制了模型对两种模态的深度理解。
独立的权重机制 (Separate Weights)
MMDiT 的核心创新在于:为文本和图像分别保留独立的权重,但在注意力计算时将它们拼接在一起进行信息交互。
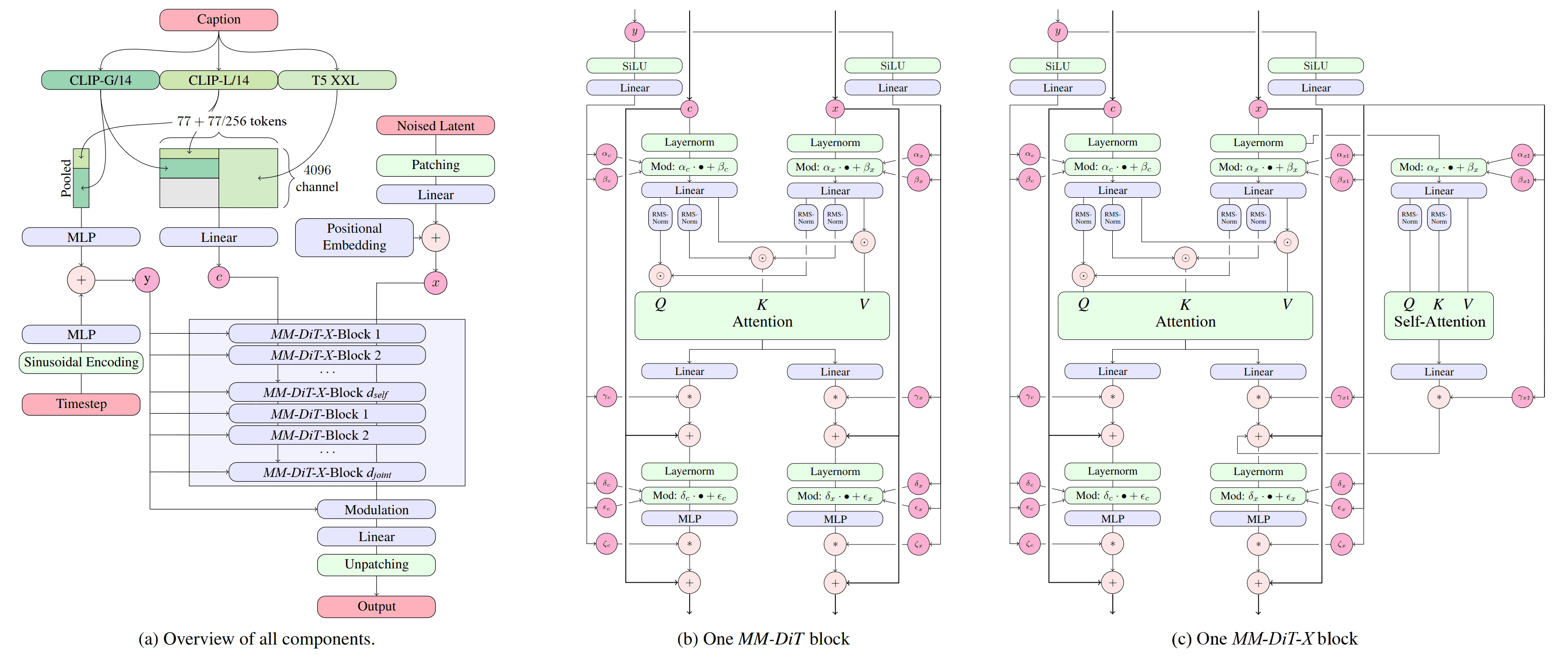
如上图所示,MMDiT 的一个 Block 包含以下步骤:
独立的全连接层(Linear/MLP):文本序列和图像序列分别通过各自的线性层,生成各自的 Q, K, V。
- 文本:\(Q_t, K_t, V_t\)
- 图像:\(Q_i, K_i, V_i\)
序列拼接(Concatenation):将文本和图像的 Q, K, V 在序列长度维度上拼接起来。
- \(Q = [Q_t, Q_i]\)
- \(K = [K_t, K_i]\)
- \(V = [V_t, V_i]\)
联合自注意力(Joint Self-Attention):对拼接后的序列进行标准的自注意力计算。这样,图像不仅可以关注图像自身,还可以关注文本;文本也可以关注图像。
- \(\text{Output} = \text{Attention}(Q, K, V)\)
序列拆分(Split):将注意力输出的序列重新拆分为文本部分和图像部分。
独立的 MLP 层:拆分后的文本和图像分别通过各自的 MLP 层进行非线性变换。
MMDiT 的优势与代码实现
这种设计的巧妙之处在于:
- 保留模态特性:文本和图像有各自的投影矩阵(Linear)和 MLP,这意味着它们可以在各自的特征空间中保持独特的表示,而不需要被强行压缩到同一个维度。
- 深度的双向交互:在联合自注意力中,不仅图像特征被文本条件化(Image conditioned on Text),文本特征也在被图像条件化(Text conditioned on Image)。这种深度的双向信息流动,极大地提升了模型对复杂 Prompt(特别是包含多个实体和空间关系的 Prompt)的理解能力。
开源代码参考: 目前,SD3 的 MMDiT 架构已经在 Hugging
Face 的 diffusers 库中得到了官方支持。你可以通过查看
diffusers/models/transformers/transformer_sd3.py 中的
JointTransformerBlock
来理解其代码实现。其核心逻辑如下(伪代码):
1 | class JointTransformerBlock(nn.Module): |
文本编码器与 Flow Matching
除了 MMDiT 架构,SD3 的强大还归功于以下两点:
- 强大的文本编码器组合:SD3 同时使用了三个文本编码器:CLIP L/14、OpenCLIP bigG/14 和 T5-v1.1-XXL。特别是 T5 的引入,使得 SD3 在文字拼写(Typography)和复杂指令遵循上取得了质的飞跃。
- Flow Matching 训练目标:正如我们在上一篇文章中所讲,SD3 放弃了传统的 DDPM 噪声预测,转而预测从噪声到数据的连续向量场(Velocity Field)。结合 Rectified Flow,SD3 实现了更平滑的生成轨迹和更少的采样步数。
总结
Stable Diffusion 3 通过 MMDiT 架构实现了文本和图像特征的深度双向融合,结合 Flow Matching 和强大的文本编码器,将开源图像生成模型推向了一个新的高度。
在下一篇文章中,我们将解析另一个基于 Flow Matching 和 DiT 的明星模型——Flux,看看它在架构上与 SD3 有何异同。