笔记|生成模型(十五):Flux 架构解析
本文为系列第十六篇。继 Stable Diffusion 3 之后,Black Forest Labs(由原 Stable Diffusion 核心团队创立)推出了 Flux 系列模型。Flux 同样采用了 Flow Matching 和 DiT 架构,但在细节设计上有着独特的创新,使其在图像质量和指令遵循上达到了目前的顶尖水平。本文将深入解析 Flux 的核心架构。
Flux 整体架构概览
Flux 模型的参数量达到了惊人的 12B(120亿),是目前最大的开源图像生成模型之一。它的整体流程与 SD3 类似,但在 Transformer Block 的设计上采用了混合架构。
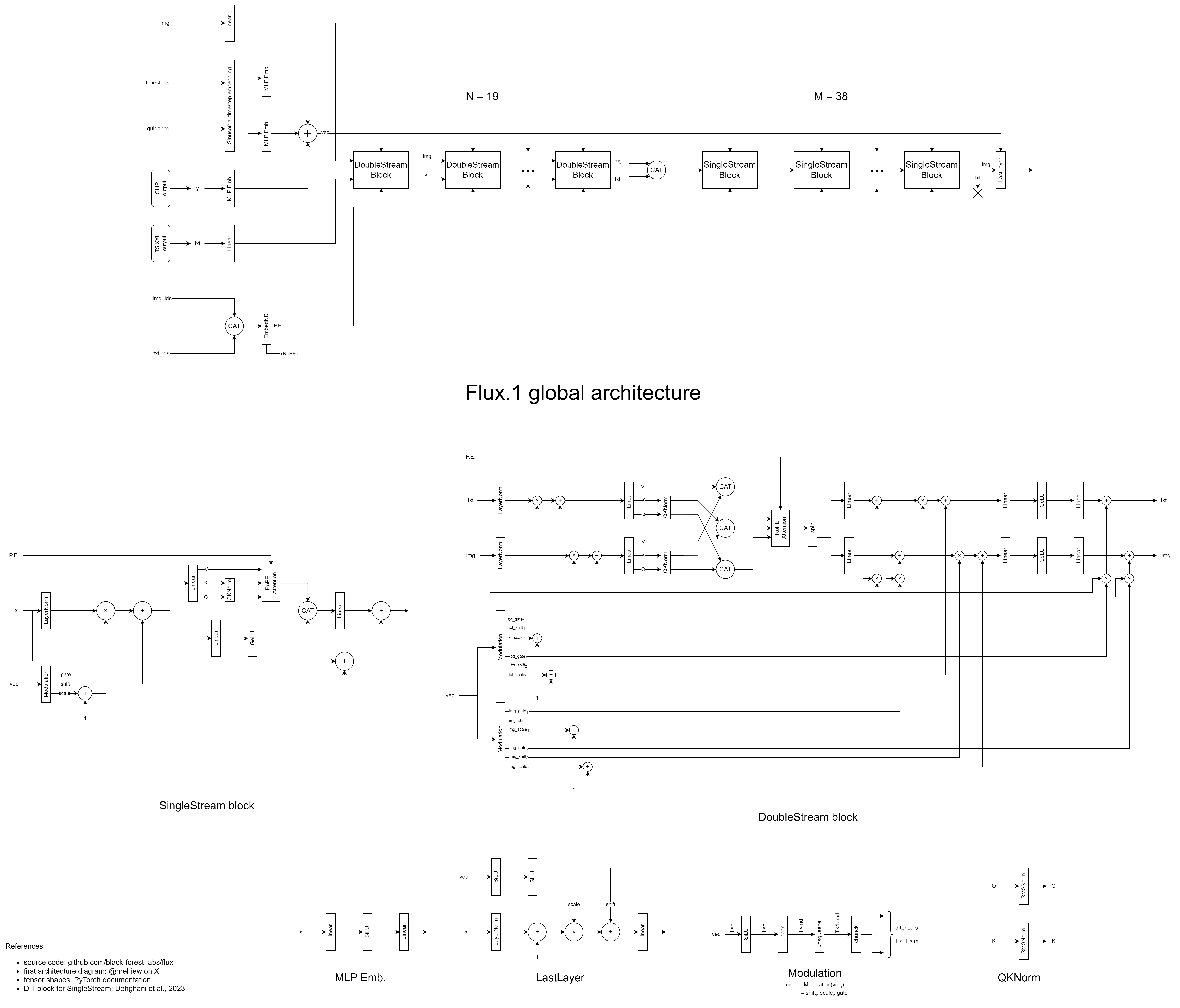
Flux 的核心骨干网络由两部分组成:
- Double Stream Blocks (双流块):类似于 SD3 的 MMDiT,文本和图像序列分别处理,但在注意力层进行交互。
- Single Stream Blocks (单流块):文本和图像序列被完全拼接在一起,作为一个统一的序列通过相同的 MLP 和注意力层。
Double Stream 与 Single Stream 的混合设计
Double Stream Blocks
在模型的前半部分(共 19 层),Flux 采用了 Double Stream Blocks。这与 SD3 的 MMDiT 非常相似:
- 文本和图像有各自独立的 LayerNorm、QKV 投影矩阵和 MLP。
- 在计算 Self-Attention 时,将文本和图像的 QKV 拼接起来进行联合注意力计算。
- 计算完成后再拆分开,分别进入各自的 MLP。
这种设计的目的是在特征提取的早期阶段,允许文本和图像在各自的模态空间中保留独特性,同时进行深度的双向信息交换。
Single Stream Blocks
在模型的后半部分(共 38 层),Flux 切换到了 Single Stream Blocks。
- 在进入 Single Stream 之前,文本和图像特征被完全拼接成一个长序列。
- 在这些 Block 中,不再区分文本和图像,它们共享同一个 LayerNorm、QKV 投影矩阵和 MLP。
为什么采用混合架构? 研究表明,在网络的前期,文本和图像的语义差异较大,需要独立的权重来分别处理(Double Stream);而在网络的后期,多模态信息已经高度融合,此时将它们视为一个统一的序列(Single Stream)不仅能减少参数量,还能进一步促进特征的深度交融。
开源代码参考: Flux 的官方实现位于
black-forest-labs/flux 仓库,同时 Hugging Face
diffusers 也已全面支持。在
diffusers/models/transformers/transformer_flux.py
中,你可以清晰地看到这两种 Block 的定义:
1 | # 前 19 层:Double Stream (对应 FluxTransformerBlock) |
核心创新点
除了混合 Block 设计,Flux 还有几个非常关键的创新:
1. RoPE (Rotary Positional Embedding) 的引入
在传统的 DiT 或 SD3 中,通常使用绝对位置编码(如 2D Sinusoidal Positional Encoding)来表示图像 Patch 的空间位置。
Flux 创新性地在图像生成中引入了自然语言处理中广泛使用的 RoPE (旋转位置编码)。
- 对于一维的文本序列,使用标准的 1D RoPE。
- 对于二维的图像 Patch 序列,Flux 采用了 2D RoPE。它将每个 Patch 的行坐标和列坐标分别进行旋转编码,然后组合在一起。
RoPE 的引入极大地增强了模型对空间关系的感知能力,使得 Flux 在处理复杂构图、多实体相对位置以及生成不同长宽比的图像时游刃有余。
2. 强大的文本编码器
与 SD3 类似,Flux 也使用了多个文本编码器来提取 Prompt 特征:
- CLIP L/14:提取全局的语义特征(Pooled output)。
- T5-v1.1-XXL:提取细粒度的 Token 级别特征序列。
T5 的强大语言理解能力是 Flux 能够精准遵循长指令和正确拼写文字的关键。
3. Flow Matching 与 QK-Norm
Flux 同样采用了 Flow Matching 作为训练目标,预测向量场。 此外,为了稳定 12B 参数大模型的训练,Flux 在 Self-Attention 中引入了 QK-Norm(对 Query 和 Key 进行 LayerNorm),这有效防止了注意力分数的数值溢出,保证了训练的稳定性。
总结
Flux 通过 Double Stream 和 Single Stream 的混合架构,结合 2D RoPE 和 Flow Matching,将 DiT 架构的潜力发挥到了极致。它不仅在图像质量上令人惊艳,更为后续的微调(如我们即将介绍的 Flow-GRPO)提供了极其强大的基础模型。
随着 SD3 和 Flux 的解析完成,我们补齐了现代大模型架构的拼图。接下来,我们将正式进入本系列的最高潮:大模型对齐与强化学习(RLHF)。