笔记|生成模型(四):变分自编码器理论
⬅️ 上一篇:笔记|生成模型(三):生成对抗理论
➡️ 下一篇:杂谈|写作的目的
自编码器(Autoencoder, AE) VS 变分自编码器(Variational Autoencoder,VAE)
自编码器
如下图所示,自编码器分为编码器和解码器组成。编码器通过映射将原始高维空间的数据映射成一个特征向量(之前说过某种数据一般都是高维空间低维流形的形式存在,那存储和运算其实仅需要在低维流形上即可。关键在于如何表示出低维流形),即寻找输入数据的低维特征来压缩数据。而解码器通过映射将低维特征解码回我们能够看得懂的高纬数据。
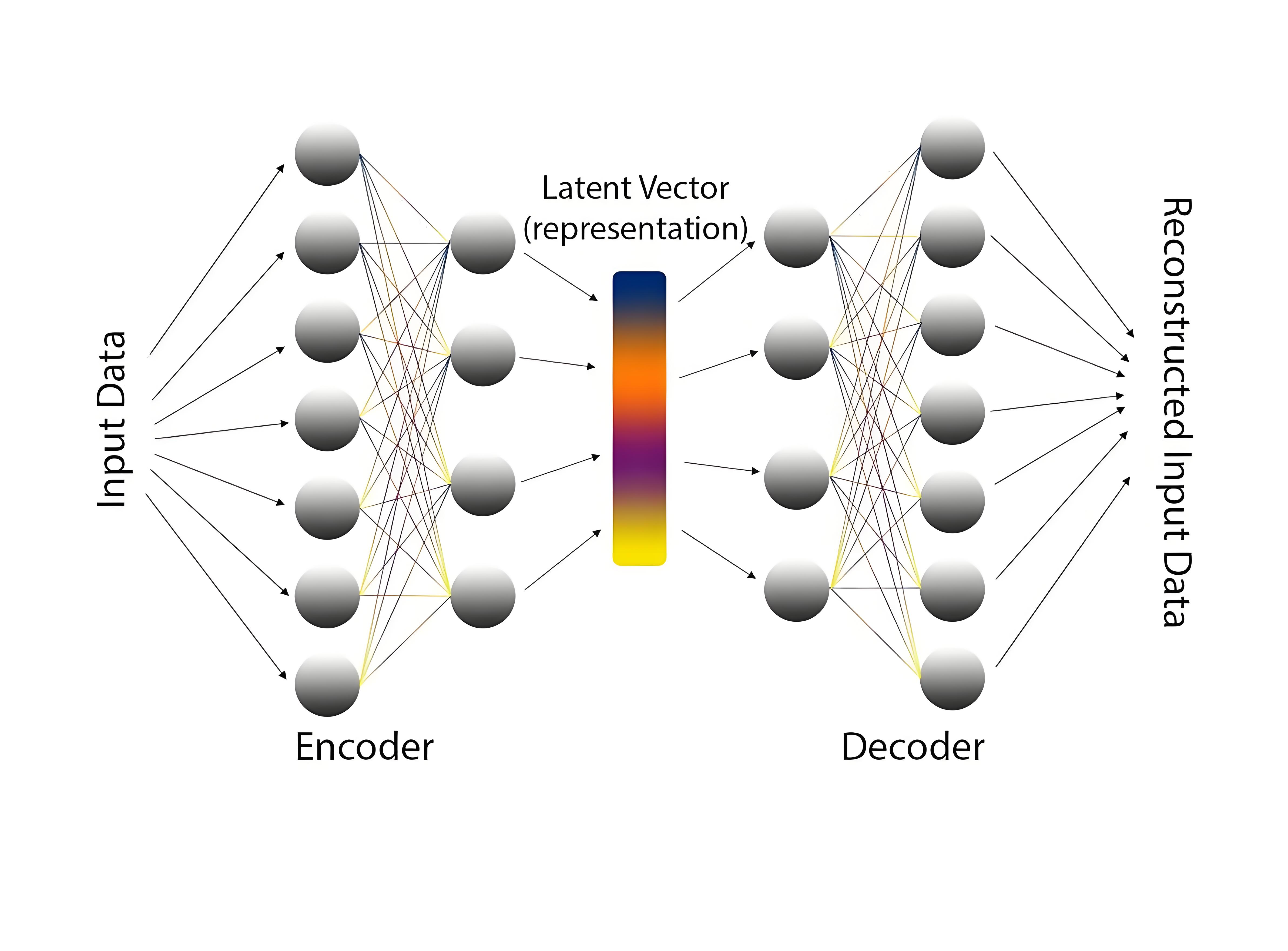
用数学的定义表示为:
给定数据集 \(\mathcal{D} = \{x^{(i)}\}_{i=1}^N\),编码器 \(f_\theta: \mathcal{X} \to \mathcal{Z}\) 和解码器 \(g_\phi: \mathcal{Z} \to \mathcal{X}\)。这两个函数学习一个确定性映射,使得重构结果 \(\hat{x}\) 尽可能接近原始输入 \(x\):
\[ z = f_\theta(x), \quad \hat{x} = g_\phi(z) \] 其中 \(x\) 是输入数据,z是低维特征(或中间变量),\(\hat{x}\) 是解码特征。
优化目标为最小化重构误差:
\[ \min_{\theta, \phi} \ \mathcal{L}_{AE}(\theta, \phi) = \frac{1}{N} \sum_{i=1}^N \ell\left( x^{(i)}, g_\phi\left(f_\theta\left(x^{(i)}\right)\right) \right) \]
其中常用均方误差(MSE)作为损失函数:
\[ \ell(x, \hat{x}) = \|x - \hat{x}\|_2^2 \]
缺点:
潜在空间无规律性:自编码器训练时只关注重构误差,并不保证潜在空间 \(z\) 的连续性和规律性。这意味着:
- 相似的输入可能被映射到潜在空间中相距很远的位置
- 潜在空间中相邻的点解码后可能产生完全不同的输出
- 无法通过在潜在空间中插值来生成有意义的新样本
无法进行生成:虽然解码器 \(g_\phi\) 可以将潜在编码解码回数据,但我们无法知道如何采样合理的潜在编码 \(z\) 来生成新的数据。因为训练过程中没有约束潜在空间的分布。
过拟合风险:自编码器可能简单地学会记忆训练数据,而不是学习数据的内在表示。这导致模型在新数据上泛化能力差。
缺乏概率解释:传统自编码器是确定性的,没有概率框架,无法量化不确定性,也无法进行贝叶斯推断。
变分自编码器
核心思想
为了解决上述问题,我们需要对传统自编码器进行根本性的改进。核心思想是引入概率框架,将确定性的编码-解码过程转换为概率生成模型。具体而言:
概率化建模:
- 编码器:\(q_\phi(z|x)\) - 将输入数据映射为潜在变量的概率分布
- 解码器:\(p_\theta(x|z)\) -
从潜在变量生成数据的概率分布
- 先验分布:\(p(z)\) - 对潜在空间结构的约束
理论基础:基于变分推断框架,通过最大化数据对数似然的下界来训练模型
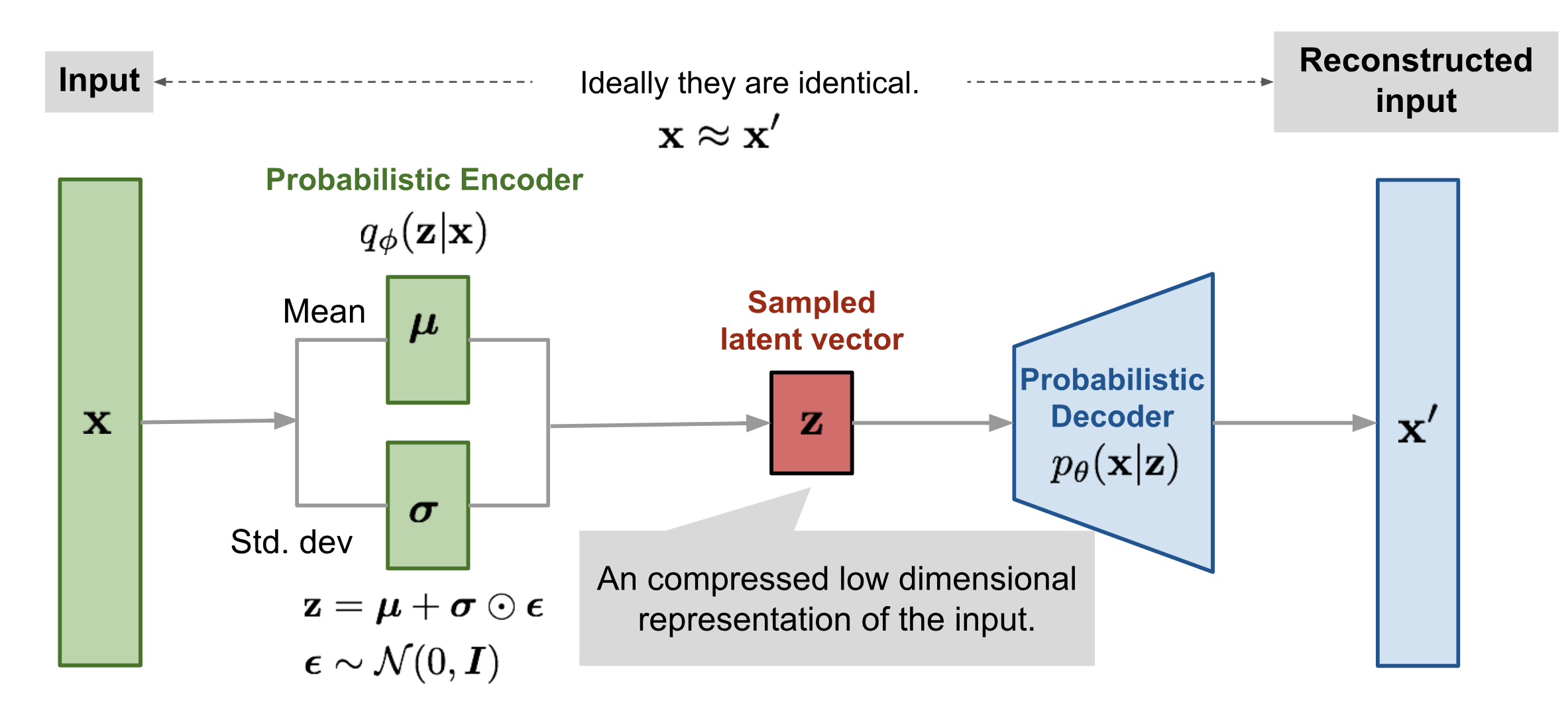
VAE架构如图所示,其网络流程可概述如下: \[x \xrightarrow{\text{Encoder}} q_\phi(z|x) \xrightarrow{\text{Sample}} z \xrightarrow{\text{Decoder}} p_\theta(x|z)\] 编码器根据输入图像预测对应先验分布的均值和协方差,经过重采样得到隐变量\(z\),隐变量通过解码器得到原始的数据分布\(x\)。
编码器(Encoder/Recognition Network):
- 输入:观测数据 \(x\)
- 输出:隐变量后验分布的参数 \(\mu_\phi(x)\) 和 \(\sigma_\phi(x)\)
- 功能:学习近似后验分布 \(q_\phi(z|x) = \mathcal{N}(\mu_\phi(x), \sigma^2_\phi(x))\)
解码器(Decoder/Generative Network):
- 输入:隐变量 \(z\)
- 输出:重构数据的条件分布 \(p_\theta(x|z)\)
- 功能:学习从隐变量空间到数据空间的映射,生成与原始数据相似的样本
损失函数:
VAE的损失函数推导
VAE使用一个encoder将高维数据\(x\)编码为低维隐变量\(z\),再用一个decoder将\(z\)还原回\(p(x|z)\):
\[Loss = \mathbb{E}_{z \sim q(z|x)}[-\log p_\theta(x|z)] + \text{KL}(q_\phi(z|x) \| p(z))\]
- 第一项是基于encoder得到的\(z\)经过decoder后的重建损失(类似于正则项)
- 第二项是encoder预测分布与先验分布之间的KL散度
分布假设与公式详解
为了使VAE的损失函数具有解析形式,我们需要对各个分布做出合理假设:
先验分布 \(p(z)\):假设为标准正态分布 \(\mathcal{N}(0, I)\)
编码器输出 \(q(z|x)\):输出为正态分布 \(\mathcal{N}(\mu_\phi(x), \Sigma_\phi(x))\),并简化假设各维度独立,即 \(\Sigma_\phi(x) = \text{diag}(\sigma^2_\phi(x))\),最终形式为 \(\mathcal{N}(\mu_\phi(x), \sigma_\phi(x))\)
解码器输出 \(p(x|z)\):同样假设为正态分布 \(\mathcal{N}(\mu_\theta(z), \Sigma_\theta(z))\),并简化假设各维度独立且方差为常数,即 \(\Sigma_\theta(x) = \text{diag}(\sigma^2_\theta(x)) = \sigma^2 I\)
损失函数的具体形式
基于上述假设,我们可以推导出损失函数的解析形式:
KL散度项:
两个高斯分布之间的KL散度有解析解。对于 \(q_\phi(z|x) = \mathcal{N}(\mu_\phi(x), \Sigma_\phi(x))\) 和 \(p(z) = \mathcal{N}(0, I)\):
\[\begin{align*} \text{KL}(q_\phi(z|x) \| p(z)) &= \int q_\phi(z|x) \log \frac{q_\phi(z|x)}{p(z)} dz \\ &= \mathbb{E}_{z \sim q_\phi(z|x)}\left[\log q_\phi(z|x) - \log p(z)\right] \end{align*}\]
对于两个多维高斯分布 \(\mathcal{N}(\mu_1, \Sigma_1)\) 和 \(\mathcal{N}(\mu_2, \Sigma_2)\),KL散度的通用公式为:
\[\text{KL}(\mathcal{N}(\mu_1, \Sigma_1) \| \mathcal{N}(\mu_2, \Sigma_2)) = \frac{1}{2}\left[\text{tr}(\Sigma_2^{-1}\Sigma_1) + (\mu_2-\mu_1)^T\Sigma_2^{-1}(\mu_2-\mu_1) - d + \log\frac{\det(\Sigma_2)}{\det(\Sigma_1)}\right]\]
在我们的情况下,\(\mu_1 = \mu_\phi(x)\),\(\Sigma_1 = \Sigma_\phi(x)\),\(\mu_2 = 0\),\(\Sigma_2 = I\),代入得:
\[\begin{align*} \text{KL}(q_\phi(z|x) \| p(z)) &= \frac{1}{2}\left[\text{tr}(I^{-1}\Sigma_\phi(x)) + (0-\mu_\phi(x))^T I^{-1}(0-\mu_\phi(x)) - d + \log\frac{\det(I)}{\det(\Sigma_\phi(x))}\right] \\ &= \frac{1}{2}\left[\text{tr}(\Sigma_\phi(x)) + \mu_\phi(x)^T\mu_\phi(x) - d + \log 1 - \log\det(\Sigma_\phi(x))\right] \\ &= \frac{1}{2}\left[\text{tr}(\Sigma_\phi(x)) + \mu_\phi(x)^T\mu_\phi(x) - d - \log\det(\Sigma_\phi(x))\right] \end{align*}\]
当假设各维度独立时,\(\Sigma_\phi(x) = \text{diag}(\sigma^2_\phi(x)_1, ..., \sigma^2_\phi(x)_d)\),则:
- \(\text{tr}(\Sigma_\phi(x)) = \sum_{i=1}^{d} \sigma^2_\phi(x)_i\)
- \(\mu_\phi(x)^T\mu_\phi(x) = \sum_{i=1}^{d} \mu^2_\phi(x)_i\)
- \(\log\det(\Sigma_\phi(x)) = \sum_{i=1}^{d} \log\sigma^2_\phi(x)_i\)
因此最终得到: \[\text{KL}(q_\phi(z|x) \| p(z)) = \frac{1}{2}\sum_{i=1}^{d}(\mu^2_\phi(x)_i + \sigma^2_\phi(x)_i - 1 - \log\sigma^2_\phi(x)_i)\]
为避免乘法麻烦,可让encoder直接预测 \(\log\sigma^2_\phi(x)\) 而非 \(\sigma^2_\phi(x)\),避免加激活函数: \[\sigma_\phi(x) = \exp(0.5 * (\log\sigma^2_\phi(x)))\]
重建损失项:
由于我们假设解码器输出 \(p_\theta(x|z) = \mathcal{N}(\mu_\theta(z), \Sigma_\theta(z))\),即给定隐变量\(z\)时,\(x\)服从均值为\(\mu_\theta(z)\)、协方差为\(\Sigma_\theta(z)\)的高斯分布。
对于D维高斯分布,其概率密度函数为: \[p_\theta(x|z) = \frac{1}{(2\pi)^{D/2}|\Sigma_\theta(z)|^{1/2}} \exp\left(-\frac{1}{2}(x-\mu_\theta(z))^T\Sigma_\theta^{-1}(z)(x-\mu_\theta(z))\right)\]
取负对数: \[-\log p_\theta(x|z) = -\log\left[\frac{1}{(2\pi)^{D/2}|\Sigma_\theta(z)|^{1/2}} \exp\left(-\frac{1}{2}(x-\mu_\theta(z))^T\Sigma_\theta^{-1}(z)(x-\mu_\theta(z))\right)\right]\]
利用对数性质 \(\log(ab) = \log a + \log b\) 和 \(\log(1/a) = -\log a\): \[= \log(2\pi)^{D/2} + \log|\Sigma_\theta(z)|^{1/2} + \frac{1}{2}(x-\mu_\theta(z))^T\Sigma_\theta^{-1}(z)(x-\mu_\theta(z))\]
进一步化简: \[= \frac{D}{2}\log(2\pi) + \frac{1}{2}\log|\Sigma_\theta(z)| + \frac{1}{2}(x-\mu_\theta(z))^T\Sigma_\theta^{-1}(z)(x-\mu_\theta(z))\]
因此得到: \[-\log p_\theta(x|z) = \frac{D}{2}\log(2\pi) + \frac{1}{2}\log\det(\Sigma_\theta(z)) + \frac{1}{2}(x - \mu_\theta(z))^T\Sigma_\theta^{-1}(z)(x - \mu_\theta(z))\]
其中:
- D 是数据的维度(例如,对于28×28的MNIST图像,D=784)
- 第一项 \(\frac{D}{2}\log(2\pi)\) 是归一化常数项
- 第二项是协方差矩阵行列式的对数
- 第三项是马氏距离(Mahalanobis distance)
在简化假设下(各维度独立且方差为常数),这等价于: \[= \frac{D}{2}\log(2\pi) + \frac{D}{2}\log\sigma^2 + \frac{1}{2\sigma^2}\|x - \mu_\theta(z)\|^2\]
进一步简化,重建损失可以表示为: \[\Rightarrow \frac{1}{2\sigma^2}\|x - \mu_\theta(z)\|^2 \quad \text{(MSE Loss!)}\]
注意事项:
- nn.MSELoss在计算均方误差时默认是对所有维度上取平均的,返回值是针对一个像素维度的平均值。也就是对每个样本的所有元素的平方差进行求和,然后除以元素总数,这意味着在每个样本的所有预测值和目标值之间的所有元素上都会计算平均值。
- 但是二项KL散度的结果是在latent维度上的和,两loss在量级上容易失衡
- 方法一:MSELoss在batch维度算平均;方法二:KL项前加系数缩小
最终,完整的损失函数为: \[Loss = \frac{1}{2\sigma^2}\|x - \mu_\theta(z)\|^2 + \frac{1}{2}\sum_{i=1}^{d}(\mu^2_\phi(x)_i + \sigma^2_\phi(x)_i - 1 - \log\sigma^2_\phi(x)_i), z \in \mathcal{N}(\mu_\phi(x), \text{diag}(\sigma_\phi(x)))\]
其中一般 \(\sigma^2 = 1\)
为什么VAE的逐像素优化不会产生均值灾难?
虽然VAE在实践中也使用逐像素的MSE或BCE损失,但它巧妙地避免了均值灾难问题。关键原因如下:
- 概率建模:VAE将解码器建模为条件概率分布 \(p_\theta(x|z)\),而不是确定性函数。每个隐变量 \(z\) 对应一个输出分布,而非单一图像
- 隐变量采样:通过从 \(q_\phi(z|x)\) 采样不同的 \(z\),同一输入可以产生多样化的重构结果,避免了输出单一"平均图像"
- 分布约束:KL散度项迫使编码器学习结构化的隐空间,使得相似的输入映射到相似的隐变量区域,但仍保持足够的变异性
- 变分框架:重构损失是对期望的优化:\(\mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x|z)]\),这意味着模型在多个采样的 \(z\) 上平均优化,而非对固定输出优化
- 本质上,VAE通过概率建模和隐变量的随机性,将"一对一的确定性重构"转化为"一对多的概率性生成",从而绕过了均值灾难的陷阱。
聪明的同学可能会注意到,估计均值和方差再随机采样的方式是不可导的,梯度如何反传到编码器上?这就不得不提重参数化技巧的重要性了。
重参数化技巧(Reparameterization Trick)
VAE训练中的一个关键挑战是:如何通过采样操作进行反向传播?因为采样是一个随机过程,梯度无法直接通过。
重参数化技巧巧妙地解决了这个问题。对于高斯分布 \(q_\phi(z|x) = \mathcal{N}(\mu_\phi(x), \sigma^2_\phi(x))\),我们可以将采样过程重写为:
\[z = \mu_\phi(x) + \sigma_\phi(x) \odot \epsilon\]
其中 \(\epsilon \sim \mathcal{N}(0, I)\) 是从标准高斯分布采样的噪声,\(\odot\) 表示逐元素乘积。
这样,随机性被转移到了与参数无关的 \(\epsilon\) 上,而 \(z\) 关于参数 \(\phi\) 是可微的,从而可以使用标准的反向传播算法。(先对标准正态分布采样再放大,而不是直接构造目标分布进行随机采样)
通过重参数化,将不可微的采样操作转化为可微的确定性变换,这种方法相比于其他梯度估计方法(如REINFORCE),提供了低方差的梯度估计,实现简单,计算效率高。
VAE和AE的异同对比:
| 对比维度 | 自编码器 (AE) | 变分自编码器 (VAE) |
|---|---|---|
| 学习范式 | 无监督学习,编码器-解码器架构 | 无监督学习,编码器-解码器架构 |
| 网络结构 | 对称的编码器-解码器结构 | 对称的编码器-解码器结构 |
| 隐空间性质 | 确定性映射,每个输入对应唯一隐编码 | 概率分布,从学习到的分布中采样 |
| 隐变量数学表示 | \(z = f_\theta(x)\) | \(z \sim q_\phi(z\|x)\) |
| 生成能力 | ❌ 隐空间不连续,随机采样无意义 | ✅ 隐空间连续,支持随机生成 |
| 隐空间约束 | ❌ 无约束,可能不规整 | ✅ KL散度约束到先验分布 |
| 优化目标 | 仅重构误差:\(\mathcal{L} = \|\|x - \hat{x}\|\|^2\) | 重构损失 + KL正则:\(\mathcal{L} = \mathcal{L}_{recon} + \mathcal{L}_{KL}\) |
| 理论基础 | 信息压缩和特征学习 | 变分推断和贝叶斯框架 |
| 训练稳定性 | 容易过拟合,记忆训练数据 | KL正则化防止过拟合 |
| 插值性质 | ❌ 隐空间插值可能无意义 | ✅ 支持语义插值和平滑变换 |
| 不确定性 | ❌ 确定性输出,无不确定性建模 | ✅ 概率框架,可量化不确定性 |
| 应用场景 | 特征提取、降维、异常检测 | 数据生成、插值、潜在空间探索 |
变分自编码器的一些数学证明和推导:
生成模型的技术路线总览中有讨论到,生成模型所需要做的事就是:给定从真实分布 \(P(x)\) 中采样的观测数据 \(x\),训练得到一个由参数 \(\theta\) 控制、能够逼近真实分布的模型 \(p_\theta(x)\)。VAE的想法是借助AE的思想,引入隐变量 \(z\) 用来表示数据的低维流形,这个\(z\) 不是孤立的,而是服从某种人为规定的先验分布,定义为 \(p(z)\)。那么,数据的边际似然可以写为:
\[p_\theta(x) = \int p_\theta(x|z)p(z)dz\]
为了让分布可控和方便重采样,\(p(z)\)通常选择已知的分布形态来表示,比如标准高斯分布 \(p(z) = \mathcal{N}(0, I)\)。
然而,直接优化边际似然面临两个关键挑战:
- 积分 \(\int p_\theta(x|z)p(z)dz\) 通常无法解析计算
- 后验分布 \(p_\theta(z|x)\) 难以直接获得
这就是VAE要解决的核心问题:如何在无法直接计算边际似然和后验分布的情况下,有效地训练一个生成模型?
VAE的解决方案
VAE采用了变分推断来解决这个问题。
引入变分分布:既然真实的后验分布 \(p_\theta(z|x)\) 难以计算,则引入一个参数化的变分分布 \(q_\phi(z|x)\) 来近似它。这个分布由编码器网络参数化。
优化证据下界(ELBO):通过最大化证据下界来同时优化编码器和解码器。我们可以将对数边际似然重写为:
推导步骤详解:(这里采用Jensen不等式,用基础理论章节中的贝叶斯推断也是可以的)
\[ \begin{aligned} \log p_\theta(x) &= \log \int p_\theta(x|z)p(z)dz \quad \text{(边际似然的积分形式)} \\ &= \log \int \frac{p_\theta(x|z)p(z)}{q_\phi(z|x)} q_\phi(z|x) dz \quad \text{(乘除变分分布)} \\ &= \log \mathbb{E}_{q_\phi(z|x)}\left[\frac{p_\theta(x|z)p(z)}{q_\phi(z|x)}\right] \quad \text{(期望形式)} \\ &\ge \mathbb{E}_{q_\phi(z|x)}\left[\log \frac{p_\theta(x|z)p(z)}{q_\phi(z|x)}\right] \quad \text{(Jensen不等式)} \\ &= \mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x|z)] + \mathbb{E}_{q_\phi(z|x)}\left[\log \frac{p(z)}{q_\phi(z|x)}\right] \\ &= \mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x|z)] - \text{KL}(q_\phi(z|x) \| p(z)) \\ &= ELBO \end{aligned} \]
- Jensen不等式,因为\(\log\)是凹函数,所以\(\log(\mathbb{E}[X]) \ge \mathbb{E}[\log(X)]\)
- KL散度定义:\(\text{KL}(q\|p) = \mathbb{E}_q[\log q - \log p]\)
所以VAE 优化目标可表述为:
\[ \max_{\theta, \phi} \ \mathcal{L}_{VAE}(\theta, \phi) = \mathbb{E}_{q_\theta(z|x)} \left[ \log p_\phi(x|z) \right] - \mathrm{KL}\left( q_\theta(z|x) \,\|\, p(z) \right) \]
由两部分组成:
重构损失(Reconstruction Loss):\(-\mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x|z)]\)
- 衡量解码器重构输入的能力
- 对于伯努利分布,这等价于二元交叉熵
- 对于高斯分布,这等价于均方误差
正则化项(Regularization Term):\(\text{KL}(q_\phi(z|x) \| p(z))\)
- 约束编码器输出的分布接近先验分布
- 防止编码器简单地记忆训练数据
- 确保隐空间的连续性和可插值性
VAE的直观理解
从信息论的角度,VAE可以理解为一个信息瓶颈(Information Bottleneck):
- 编码器:压缩输入信息到隐变量,但要保留足够的信息用于重构
- KL正则化:限制隐变量携带的信息量,防止过拟合
- 解码器:从压缩的表示中恢复原始信息
从几何角度,VAE学习了一个从数据空间到隐空间的光滑映射:
- 连续性:相似的输入被映射到隐空间中相近的位置
- 可插值性:隐空间中两点之间的插值对应有意义的生成结果
- 解耦性:理想情况下,隐变量的不同维度对应数据的不同属性
VAE的优势与局限
优势:
- 理论基础扎实:基于变分推断的严格数学框架
- 稳定训练:相比GAN,训练过程更稳定,不存在模式坍塌问题
- 可解释的隐空间:隐变量有明确的概率解释
- 支持推断:可以将新数据编码到隐空间
- 易于扩展:框架灵活,易于加入各种先验知识
局限:
- 生成质量:由于使用像素级重构损失,生成的图像往往比较模糊
- 后验坍塌:KL项可能导致编码器忽略输入,退化为先验分布
- 表达能力受限:简单的高斯假设可能无法捕捉复杂的数据分布
- 重构与生成的权衡:重构质量和生成多样性之间存在固有矛盾
VAE的重要变体
为了克服原始VAE的局限性,研究者们提出了许多改进版本:
| 变体名称 | 核心思想 | 数学表示 | 主要特点 | 应用场景 |
|---|---|---|---|---|
| Conditional VAE (CVAE) | 引入条件信息实现可控生成 | \(q_\phi(z\|x,c), p_\theta(x\|z,c)\) | • 支持条件生成 • 可控制生成内容 • 结合标签信息 |
条件图像生成、半监督学习、多模态学习 |
| VQ-VAE | 使用离散隐变量和向量量化技术 | 离散编码本 \(e \in \mathbb{R}^{K \times D}\) | • 解决后验坍塌 • 提高生成质量 • 支持自回归生成 |
图像生成、语音合成、强化学习 |
| Hierarchical VAE | 使用多层隐变量捕捉层次结构 | \(z = \{z_1, z_2, ..., z_L\}\) | • 高层捕捉全局信息 • 低层捕捉局部细节 • 更强表达能力 |
复杂数据建模、层次化表示学习 |
| Adversarial VAB (AVB) | 结合GAN思想使用判别器定义变分分布 | 隐式变分分布通过判别器学习 | • 避免高斯假设限制 • 提高后验表达能力 • 结合对抗训练 |
复杂后验分布建模、高质量生成 |
VAE在实际应用中的技巧
| 技巧类别 | 具体技巧 | 技术描述 | 应用目的 |
|---|---|---|---|
| 防止后验坍塌 | KL退火 (KL Annealing) | 训练初期减小KL项权重,逐渐增加 | 避免编码器忽略输入信息 |
| 自由比特 (Free Bits) | 为每个隐变量维度设置最小信息量 | 确保每个维度承载有效信息 | |
| 跳跃连接 | 在解码器中加入跳跃连接 | 减少对隐变量的过度依赖 | |
| 提高生成质量 | 感知损失 | 使用预训练网络的特征匹配损失代替像素损失 | 生成更具语义合理性的图像 |
| 对抗训练 | 加入判别器,提高生成样本的真实感 | 增强生成图像的视觉质量 | |
| 自回归解码器 | 使用PixelCNN等自回归模型作为解码器 | 改善像素级细节生成 | |
| 改进隐空间 | 归一化流 (Normalizing Flows) | 增强后验分布的表达能力 | 学习更复杂的后验分布 |
| 混合高斯先验 | 使用更灵活的先验分布 | 提供更丰富的隐空间结构 | |
| 信息最大化 | 鼓励隐变量之间的独立性 | 实现更好的属性解耦 |
VAE与其他生成模型的比较
| 特性 | VAE | GAN | 扩散模型 |
|---|---|---|---|
| 理论基础 | 变分推断 | 博弈论 | 随机过程 |
| 训练稳定性 | 高 | 低 | 高 |
| 生成质量 | 中等 | 高 | 最高 |
| 推断能力 | 支持 | 不支持 | 部分支持 |
| 训练速度 | 快 | 中等 | 慢 |
| 可解释性 | 高 | 低 | 中等 |
最后贴上VAE的代码
模型代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class VAE(nn.Module):
def __init__(self):
super().__init__()
# 编码器
self.encoder_layer = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 128),
)
self.fc_mu = nn.Linear(128, 10) # 均值
self.fc_log_var = nn.Linear(128, 10) # 对数方差
# 解码器
self.decoder = nn.Sequential(
nn.Linear(10, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, 784),
)
def encode(self, x):
"""编码器:输出均值和对数方差"""
h = self.encoder_layer(x) # [b,784] -> [b,128]
mu = self.fc_mu(h) # [b,128] -> [b,10]
log_var = self.fc_log_var(h) # [b,128] -> [b,10]
return mu, log_var
def reparameterize(self, mu, log_var):
"""重参数化技巧"""
eps = torch.randn_like(mu) # 标准正态分布采样
std = torch.exp(0.5 * log_var) # 标准差
z = mu + eps * std # [b,10]
return z
def decode(self, z):
"""解码器"""
return self.decoder(z) # [b,10] -> [b,784]
def forward(self, x):
x = x.view(-1, 28*28) # [b,1,28,28] -> [b,784]
mu, log_var = self.encode(x) # 编码
z = self.reparameterize(mu, log_var) # 重参数化
recon_x = self.decode(z) # 解码重构
return recon_x, mu, log_var训练代码:
# 训练设置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = VAE().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
def vae_loss(recon_x, x, mu, log_var):
"""VAE损失函数:重构损失 + KL散度"""
# 重构损失(BCE或MSE)
recon_loss = F.mse_loss(recon_x, x.view(-1, 784), reduction='sum')
# KL散度损失
kl_loss = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
return recon_loss + kl_loss
for batch_idx, data in enumerate(train_loader):
data = data.to(device)
optimizer.zero_grad()
# 前向传播
recon_batch, mu, log_var = model(data)
# 计算损失
loss = vae_loss(recon_batch, data, mu, log_var)
# 反向传播
loss.backward()
optimizer.step()参考资料:
- Kingma, D. P., & Welling, M. (2013). Auto-Encoding Variational Bayes. arXiv:1312.6114.
- Doersch, C. (2016). Tutorial on Variational Autoencoders. arXiv:1606.05908.
下一篇:杂谈|写作的目的