笔记|生成模型(七):Score-Based理论
Score-based 模型理论基础
生成模型通常从某个已有的概率分布中进行采样以生成样本。Score-based 模型的关键在于对概率分布的对数梯度,即 Score Function 的建模。为了学习这个对象,我们需要使用一种称为 score matching 的技术,这是 Score-based 模型名称的由来。
Score Function 和 Score-based Models:什么是 Score?
核心思考出发点:在生成模型中,我们的目标是让模型学会真实数据的概率分布 \(p(x)\)。如果知道了这个分布,我们就能在概率高的地方采样,生成出逼真的图片。但真实分布极其复杂,直接建模 \(p(x)\) 非常困难(比如需要计算极其复杂的归一化常数 \(Z\))。
能不能换个思路? 我们不直接求概率的具体数值 \(p(x)\),而是求概率增加的方向! 就像你在爬山,你不需要知道整座山的海拔地图(绝对概率),你只需要知道站在当前位置,往哪个方向走最陡峭(梯度),顺着走就能爬到山顶(高概率区域,即真实的图片)。
这个“概率增加的方向”,在数学上就是对数概率的梯度,我们称之为 Score Function(得分函数)。
考虑一个数据集 \(\{x_1, x_2, \ldots, x_N\}\) 的概率分布 \(p(x)\),我们可以使用一种通用的方式——能量模型(Energy-based model)的形式表示这个概率分布:
\[ p_\theta(x) = \frac{\exp(-f_\theta(x))}{Z_\theta} \]
\(Z_\theta\) 是归一化因子,定义为:
\[ Z_\theta = \int \exp(-f_\theta(x)) \mathrm{d} x \]
因此,有了上式通用的概率模型定义方式,我们一般可以通过最大化对数似然的方式来训练参数,使得网络模型的分布逼近真实数据的分布:
\[ \max_{\theta} \sum_{i=1}^N \log p_\theta(x_i) \] 但是因为 \[\log p_\theta(x) = -f_\theta(x) - \log Z_\theta\] \(Z_\theta\) 是难处理的,我们无法求出 \(\log p_\theta(x)\),自然也就无法优化参数 \(\theta\)。这个问题已经有了几种不同的解决方案,例如正则化流通过保证网络可逆来使得每一步的 \(Z_\theta\) 恒定为1;VAE 改用变分推断逼近并学习距离的变分下界等。
在Score-based Models中,为了解决归一化项无法计算的问题,引入了 Score Function。定义如下:
\[ {s}_\theta(x) = \nabla_x \log p_\theta(x) \]
因为 \(Z_\theta\) 是常数,所以它的梯度为零,从而有:
\[ {s}_\theta(x) = \nabla_x \log p_\theta(x) = -\nabla_x f_\theta(x) \]
这表明 Score Function 实际上对应于神经网络的梯度。因此我们可以构建优化目标为:
\[ \theta = \arg\min_{\theta} \mathbb{E}_{p(x)}\left[ \left\| \nabla_x \log p(x) - {s}_\theta(x) \right\|_2^2 \right] \]
使得模型预测的 Score Function 与真实分布的 Score Function 之间的均方误差最小。然而真实分布的log梯度 \(\nabla_x \log p(x)\) 是未知的,我们需要利用 Score Matching 方法,Score Matching可以让我们在不知道真实分布的 \(p(x)\) 的情况下最小化这个Loss。
开源代码参考: 在实际的代码实现中(例如 Yang Song 的
score_sde 官方库),计算 Score Matching Loss 的核心 PyTorch
伪代码如下:
1 | # x: 真实数据样本 |
Score Matching
我们把上述的损失函数记为 \(\mathcal{L}\),并进行展开:
\[ \begin{aligned} \mathcal{L} &= \mathbb{E}_{p(x)}\left[ \left\| \nabla_x \log p(x) - s_\theta(x) \right\|^2 \right] \\ &= \int p(x) \left\| \nabla_x \log p(x) - s_\theta(x) \right\|^2 \mathrm{d}x \end{aligned} \]
进一步展开平方项:
\[ = \int p(x) \left[ \left\| \nabla_x \log p(x) \right\|^2 + \left\| s_\theta(x) \right\|^2 - 2 (\nabla_x \log p(x))^T s_\theta(x) \right] \mathrm{d}x \]
第一项是常数项,与参数 \(\theta\) 无关,可以忽略。第二项可以通过数据样本直接计算。现在我们关注第三项:
\[ -2 \int p(x) (\nabla_x \log p(x))^T s_\theta(x) \mathrm{d}x \]
对于 \(x\) 的维度 \(N\),我们可以将其展开为:
\[ = -2 \int p(x) \sum_{i=1}^{N} \frac{\partial \log p(x)}{\partial x_i} s_{\theta i}(x) \mathrm{d}x \]
利用对数导数的链式法则 \(\frac{\partial \log p(x)}{\partial x_i} = \frac{1}{p(x)} \frac{\partial p(x)}{\partial x_i}\):
\[ = -2 \int p(x) \sum_{i=1}^{N} \frac{1}{p(x)} \frac{\partial p(x)}{\partial x_i} s_{\theta i}(x) \mathrm{d}x \]
\[ = -2 \sum_{i=1}^{N} \int \frac{\partial p(x)}{\partial x_i} s_{\theta i}(x) \mathrm{d}x \]
对每个分量应用分部积分法,令 \(u = s_{\theta i}(x)\),\(\mathrm{d}v = \frac{\partial p(x)}{\partial x_i} \mathrm{d}x\):
\[ = -2 \sum_{i=1}^{N} \left[ \left. p(x) s_{\theta i}(x) \right|_{-\infty}^{\infty} - \int p(x) \frac{\partial s_{\theta i}(x)}{\partial x_i} \mathrm{d}x \right] \]
假设当 \(|x| \rightarrow \infty\) 时,\(p(x) \rightarrow 0\),则边界项为零:
\[ \begin{aligned} &= -2 \sum_{i=1}^{N} \left[ - \int p(x) \frac{\partial s_{\theta i}(x)}{\partial x_i} \mathrm{d}x \right] \\ &= 2 \sum_{i=1}^{N} \int p(x) \frac{\partial s_{\theta i}(x)}{\partial x_i} \mathrm{d}x \\ &= 2 \int p(x) \sum_{i=1}^{N} \frac{\partial s_{\theta i}(x)}{\partial x_i} \mathrm{d}x \end{aligned} \]
所以我们有: \[\sum_{i=1}^{N} \frac{\partial s_{\theta i}(x)}{\partial x_i} = \mathrm{tr}(\nabla_x s_\theta(x))\]
最终表达式为: \[= 2 \int p(x) \mathrm{tr}(\nabla_x s_\theta(x)) \mathrm{d}x\]
因此,最终的优化目标为:
\[ \mathcal{L} = \int p(x) \left\| s_\theta(x) \right\|^2 \mathrm{d}x + 2 \int p(x) \mathrm{tr}(\nabla_x s_\theta(x)) \mathrm{d}x \]
写成期望形式:
\[ \mathcal{L} = \mathbb{E}_{p(x)} \left[ \left\| s_\theta(x) \right\|^2 + 2 \mathrm{tr}(\nabla_x s_\theta(x)) \right] \]
这个优化目标的重要意义在于:
- 它完全避开了对 \(Z_\theta\) 的计算
- 不再依赖于真实分布 \(p(x)\) 的 Score Function
- 只需要通过数据样本就可以直接优化
从分布采样:朗之万动力学采样(Langevin Dynamics)
现在我们已经通过神经网络学习到了数据分布的Score Function,那么如何用Score Function从这个数据分布中得到样本呢?答案就是朗之万动力学采样:
- 从任意先验分布中采样初始状态 \(x_0 \sim \pi(x)\)。
- 迭代更新:
\[ x_{i+1} \leftarrow x_i + \epsilon \nabla_{x} \log p(x) + \sqrt{2\epsilon} {z}_i, \quad i = 0, 1, \ldots, K \]
其中 $ {z}_i (0, I)$,当 \(\epsilon \rightarrow 0\) 且 \(K \rightarrow \infty\) 时,\(x_K\) 会收敛到从 \(p(x)\) 直接采样的结果。
这样我们其实就得到了一个生成模型。我们可以先训练一个网络用来估计Score Function,然后用Langevin Dynamics和网络估计的Score Function采样,就可以得到原分布的样本。因为整个方法由Score Matching和Langevin Dynamics两部分组成,所以叫SMLD。
Pitfall陷阱
现在我们得到了SMLD生成模型,但实际上这个模型有很大的问题。 \[ \begin{aligned} \mathcal{L} = \int p(x) \left\| \nabla_x \log p(x) - s_\theta(x) \right\|^2 \mathrm{d}x \end{aligned} \] 观察我们用来训练神经网络的损失函数,我们可以发现这个L2项其实是被 \(p(x)\) 加权了。所以对于低概率的区域,估计出来的Score Function就很不准确。
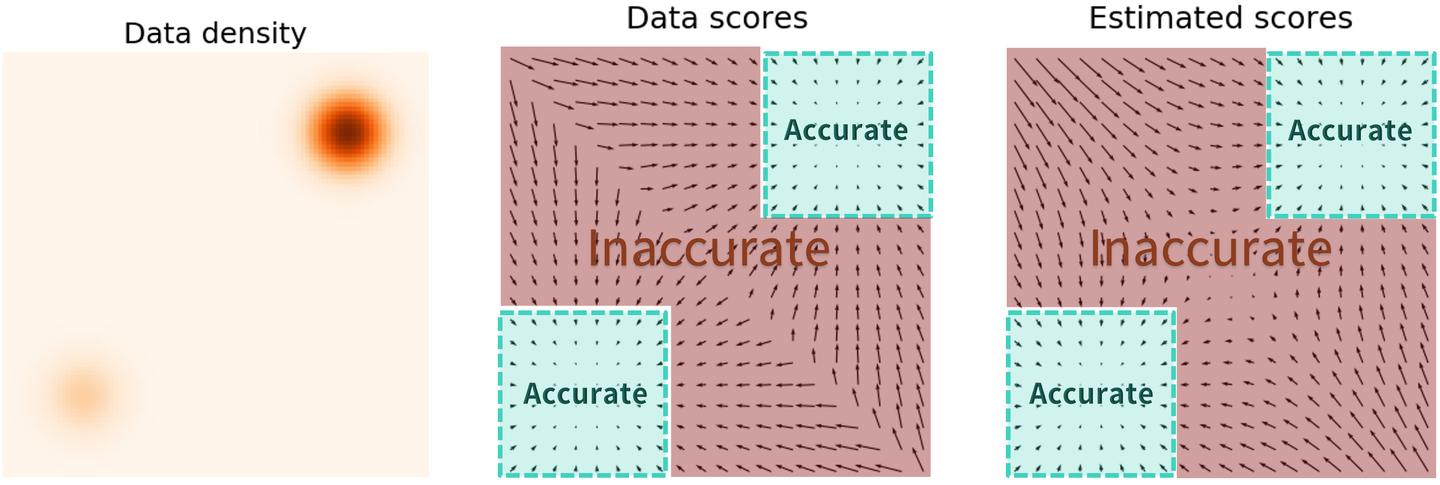
对于上面这张图来说,只有在高概率的红色区域,loss才高,Score Function可以被准确地估计出来。但如果我们采样的初始点在低概率区域的话,因为估计出的 Score Function 不准确,很有可能生成不出真实分布的样本。
那怎么样才能解决上面的问题呢?其实可以通过给数据增加噪声扰动的方式扩大高概率区域的面积。给原始分布加上高斯噪声,原始分布的方差会变大。这样相当于高概率区域的面积就增大了,更多区域的Score Function可以被准确地估计出来。

但是噪声扰动的强度如何控制是个问题:
- 强度太小起不到效果,高概率区域的面积还是太小
- 强度太大会破坏数据的原始分布,估计出来的Score Function就和原分布关系不大了
这里作者给出的解决方法是加不同程度的噪声,让网络可以学到加了不同噪声的原始分布的Score Function。
对于使用高斯噪声进行扰动的情况,可以使用 \(L\) 个带有不同方差 \(\sigma_1<\sigma_2<\cdots<\sigma_L\) 的高斯分布 \(\mathcal{N}(0,\sigma_i^2I),i=1,2,\cdots,L\) 分别对原始分布 \(p(\mathbf{x})\) 进行扰动: \[ p_{\sigma_i}(\mathbf{x})=\int p(\mathbf{y})\mathcal{N}(\mathbf{x};\mathbf{y},\sigma_i^2I)\mathrm{d}\mathbf{y} \] 从 \(p_{\sigma_i}(\mathbf{x})\) 中采样是比较容易的,和 diffusion 中的重参数化技巧类似:先采样 \(\mathbf{x}\sim p(\mathbf{x})\),再计算 \(\mathbf{x}+\sigma_i\mathbf{z}\),其中 \(\mathbf{z}\sim\mathcal{N}(0,I)\)。
获得一系列用噪声进行扰动过的分布后,依然是对每一个分布进行 score matching,对于 \(\nabla_\mathbf{x}\log p_{\sigma_i}(\mathbf{x})\) 得到一个与噪声有关的 Score Function \(\mathbf{s}_\theta(\mathbf{x},i)\)。总体上的优化目标是对所有的这些分布 score matching 优化目标的加权: \[ \sum_{i=1}^L\lambda(i)\mathbb{E}_{p_{\sigma_i}(\mathbf{x})}\left[||\nabla_\mathbf{x}\log p_{\sigma_i}(\mathbf{x})-\mathbf{s}_\theta(\mathbf{x},i)||_2^2\right] \] 对于加权权重的选择,通常直接指定 \(\lambda(i)=\sigma_i^2\)。这样我们就获得了一系列用不同的高斯噪声扰动过的分布,直观地看,扰动程度比较小的分布更接近真实分布,能在高概率密度的区域提供比较好的估计;扰动程度比较大的分布则能在低概率密度的区域提供比较好的估计,带有不同扰动程度的分布形成了一种比较互补的关系,有利于提高概率建模质量。
采样的过程依然是进行一系列迭代,不过因为有多个分布,所以需要依次对每个分布迭代一遍,相当于一共迭代 \(L\times T\) 轮,得到最终的结果。这种采样方法叫做 Annealed Langevin Dynamics,具体的采样算法可以参考这个链接的内容。
总结与算法对比
作为生成模型的一种,Score-based model 也遵循学习+采样的范式,其学习过程使用 Score Matching 来间接学习分布,采样过程使用 Langevin dynamics 通过迭代过程进行采样。
算法对比:Score-based Models vs DDPM vs Flow Matching
- 与 DDPM 的关系:Yang Song 在后续的论文(SDE)中证明了,Score-based Models 和 DDPM 在本质上是等价的! DDPM 预测的噪声 \(\epsilon_\theta\),实际上就是 Score Function 的一种缩放形式。DDPM 是从离散时间步出发的,而 Score-based Models 是从连续概率分布和向量场出发的。
- 与 Flow Matching 的关系:Flow Matching 是 Score-based Models 的进一步进化。Score-based Models 必须依赖于高斯噪声(Langevin 动力学),路径是弯曲且随机的。而 Flow Matching 允许我们定义任意的、笔直的概率流路径(比如从纯噪声直线走向真实图片),这使得 Flow Matching 的采样速度更快、训练更稳定(SD3 和 Flux 均采用了 Flow Matching)。
意义:Score-based Models 的提出,彻底打破了传统生成模型(如 GAN、VAE)必须计算复杂似然函数或对抗训练的束缚,用极其优雅的“梯度场”概念,为现代扩散模型奠定了坚实的数学基础。
参考资料: