笔记|世界模型(二):Dreamer 系列——在想象中学习控制
核心论文:Dreamer v1 (ICLR 2020)、DreamerV2 (ICLR 2021)、DreamerV3 (Nature 2025)
⬅️ 上一篇:笔记|世界模型(一):什么是世界模型?
➡️ 下一篇:笔记|世界模型(三):JEPA——在嵌入空间预测世界
一句话概括
Dreamer 是一种基于世界模型的强化学习算法:先从经验中学一个环境的"脑内模型",然后在脑子里大量练习,而不是反复与真实环境交互。DreamerV3 用同一套超参数在 150+ 个任务上均表现优异,并首次在 Minecraft 中从零采到钻石。
1. Dreamer 是怎么训练的?
1.1 训练数据
Dreamer 的训练数据来自智能体与环境交互产生的经验——每一步包含当前观测(如游戏画面)、执行的动作、获得的奖励。这些经验被存入经验回放缓冲区,训练时从中随机采样。
与监督学习不同,Dreamer 不需要人工标注数据或专家示范,数据完全来自智能体的自我探索。
1.2 基于强化学习,但换了个思路
传统的 model-free RL(如 PPO)让智能体直接在真实环境中反复试错来学习策略。问题是:每次试错都要与环境交互,当环境本身很慢或交互代价很高时,这种方法极其低效。
Dreamer 属于 model-based RL,核心改进是在智能体和环境之间加了一层"世界模型"。训练分三个阶段交替进行:
- 经验收集:用当前策略在真实环境中交互,把观测、动作、奖励存入缓冲区
- 训练世界模型:从缓冲区采样,让模型学会"执行某个动作后,世界会如何变化、能获得多少奖励"
- 在想象中训练策略:在学好的世界模型内部大量模拟轨迹,用 Actor-Critic 方法优化策略
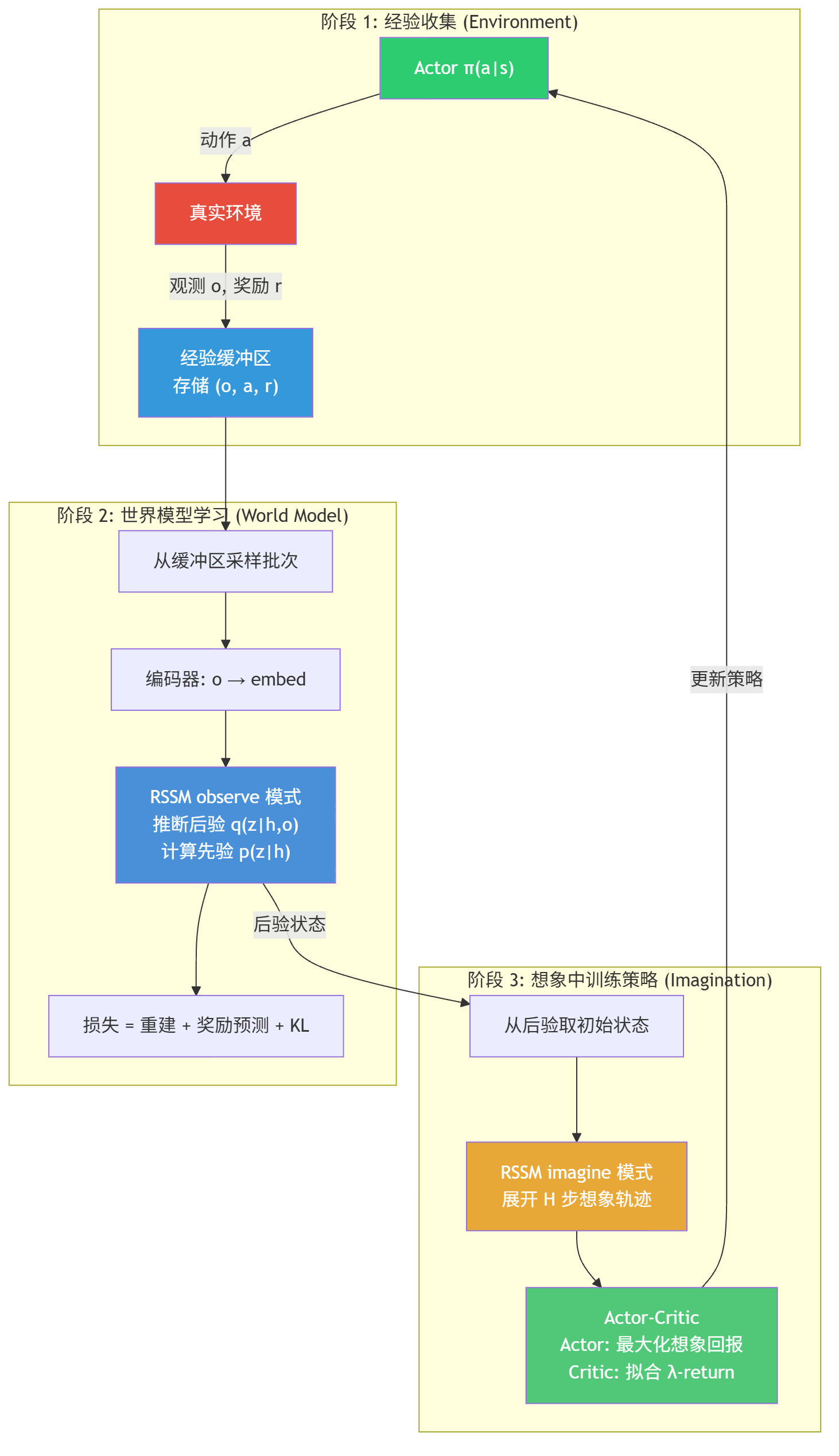
关键在于第三步:因为"想象"发生在 GPU 上,是纯神经网络的前向传播,速度比真实环境快几个数量级。这就是 Dreamer 样本效率远高于 model-free 方法的根本原因。
1.3 世界模型的核心:RSSM
Dreamer 的世界模型叫 RSSM(Recurrent State-Space Model),负责在潜在空间中模拟环境动力学。它的关键设计是把状态拆成两部分:
- 确定性部分(用 GRU 维护):记录"到目前为止发生了什么",提供稳定的长程记忆
- 随机性部分(从概率分布中采样):表达"接下来可能发生什么",允许多种可能的未来
为什么要这样设计?纯确定性模型无法处理不确定性——比如你站在十字路口,前方行人可能左转也可能右转,确定性模型只能输出一个模糊的"均值"。纯随机模型又无法保持记忆——每一步重新采样,很快就忘了之前发生的事。RSSM 通过两条并行路径同时获得了记忆能力和不确定性表达。
RSSM 还有一个重要机制——先验与后验。先验是不看当前观测、只靠历史记忆做的预测("闭卷考试"),后验是结合了当前观测后的准确推断("开卷考试")。训练时用后验,但想象阶段没有真实观测可用,只能依赖先验。通过 KL 散度损失迫使先验逼近后验——让模型即便"不看答案也能猜准",从而保证想象的可靠性。
2. Dreamer 系列的演进
2.1 Dreamer V1(2020):在想象中训练策略
核心贡献:首次实现了完全在世界模型内部用 Actor-Critic 训练策略。
V1 之前的 PlaNet(2019)虽然提出了 RSSM,但决策依赖 MPC(模型预测控制)——每一步都要在模型中搜索最优动作序列,计算量大。V1 的关键创新是:既然世界模型内的每一步都是可微的神经网络运算,梯度可以沿着想象轨迹一路反传回 Actor,直接告诉策略网络"该怎么调整动作"。相比 PPO 那种只给标量反馈的方式,信息量大得多,收敛更快。
能力:在 DeepMind Control Suite 上,样本效率远超 model-free 方法。
缺陷:
- 随机状态使用连续高斯分布,只能表达单峰不确定性——无法同时表示"可能左转也可能右转"
- KL 惩罚过强时,随机路径会坍缩,模型退化为纯确定性模型,失去不确定性表达能力
- 超参数需要针对每个任务仔细调整
2.2 DreamerV2(2021):离散化潜变量
核心改进:将连续高斯潜变量替换为离散分类分布(32 个独立的分类变量,每个 32 个类别)。
这一改动带来了几个关键提升:
- 天然多模态:离散分布可以同时给"左转"和"右转"分配高概率,不会被迫输出不存在的中间值
- KL 更稳定:离散 KL 有天然上界,不像连续高斯那样容易无限坍缩
- 性能大幅提升:Atari 上达到人类中位数的 164%(V1 仅 112%),首次在单 GPU 上超越 Rainbow 等顶级 model-free 方法
遗留问题:不同任务领域的奖励范围、KL 大小等数值尺度差异巨大,同一套超参数仍无法跨域通用。
2.3 DreamerV3(2023 / Nature 2025):一套超参横扫一切
核心改进:V3 没有重新设计 RSSM 的架构——模型结构和 V2 基本一致,仍然是 GRU + 离散分类变量。V3 改的是训练过程中各环节的数值处理方式,让同一个模型不管放到什么任务上都能稳定训练。
V2 跨域失败的根源是:不同领域的数值范围差异悬殊(Atari 奖励 0~10,某些任务回报可达 100000)。用同一套超参数去训练,梯度量级天差地别,自然学不好。V3 在训练流程的三个环节分别加了归一化:
- 世界模型训练时(阶段二)—— symlog 变换:对世界模型要预测的目标(奖励、观测等)做对称对数压缩,把不同量级的数值映射到相近范围,让世界模型的训练梯度在各种任务上都保持一致
- 世界模型的 KL 损失(阶段二)—— KL 平衡 + Free Bits:用不对称权重让大部分学习压力给先验(让"闭卷猜测"更准),同时设下限防止过度压缩随机状态
- Actor 训练时(阶段三)—— 百分位回报归一化:用历史回报分布的百分位自动缩放 Actor 的训练信号,无论回报范围是 0~1 还是 0~100000,Actor 看到的信号都在差不多的量级
简单来说,V3 的改进不在于"模型能表达什么"(这是 V2 解决的),而在于"训练过程对数值尺度的鲁棒性"——让同一套训练配置在任何任务上都能正常工作。
效果:同一套超参在 150+ 个任务上全部达到或超越专门调参的方法。DreamerV3 也是首个在不使用人类示范的前提下,从零在 Minecraft 中采到钻石的算法。该成果于 2025 年发表在 Nature 上,标志着 model-based RL 从研究兴趣走向实用方法。
剩余局限:GRU 的固定大小限制了超长序列的记忆能力(Transformer 世界模型在这方面更有优势);像素级重建把大量算力花在了与决策无关的视觉细节上。
3. 总结
Dreamer 系列的演进可以概括为:让"在想象中训练"变得更稳定、更通用。
| 版本 | 核心改进 | 解决了什么 | 遗留了什么 |
|---|---|---|---|
| V1 | 在世界模型中用 Actor-Critic 训练 | 样本效率远超 model-free | 高斯单峰、后验坍缩、超参敏感 |
| V2 | 连续高斯 → 离散分类 | 多模态表达、KL 更稳定 | 跨领域超参不通用 |
| V3 | 架构不变,训练流程加三层归一化 | 一套超参适用所有任务 | GRU 记忆瓶颈、像素重建浪费 |
每一代都不是推倒重来,而是针对上一代最突出的瓶颈做改进:V1 → V2 改的是模型能表达什么(高斯换成离散分类),V2 → V3 改的是训练流程如何适应不同任务(三层归一化消除尺度差异)。
参考资料:
- Hafner, D., et al. (2019). Learning Latent Dynamics for Planning from Pixels. ICML 2019.
- Hafner, D., et al. (2020). Dream to Control: Learning Behaviors by Latent Imagination. ICLR 2020.
- Hafner, D., et al. (2021). Mastering Atari with Discrete World Models. ICLR 2021.
- Hafner, D., et al. (2023). Mastering Diverse Domains through World Models. Nature 2025.
➡️ 下一篇:笔记|世界模型(三):JEPA——在嵌入空间预测世界