笔记|世界模型(四):视频生成即世界模拟——从 Sora 到 Genie 与 Cosmos
核心论文:Genie (arXiv:2402.15391, ICML 2024)、Cosmos (arXiv:2501.03575, 2025)、UniSim (arXiv:2310.06114, ICLR 2024)
前置知识:上一篇:JEPA
⬅️ 上一篇:笔记|世界模型(三):JEPA——在嵌入空间预测世界
0. 如果视频模型就是世界模型?
上一篇介绍了 JEPA 的哲学:"不需要画出未来,只需要理解未来。"但另一个阵营持完全相反的立场。
给一个视频生成模型一张图片和指令"向左走",它生成了一段视角向左移动的视频——走廊延伸出去,墙上的画从右侧滑入视野,地板的透视关系正确变化。这个模型"理解"了三维空间吗?它是不是已经在内部构建了某种"世界模型"?
2024 年 2 月,OpenAI 发布 Sora 时明确提出:视频生成模型是世界模拟器的有前途的路径。 这是与 JEPA 截然相反的立场——JEPA 说"不需要生成像素",Sora 说"生成像素本身就是理解世界"。
本文将梳理四个代表性的视频世界模型方案——Sora(视频生成)、Genie(可交互世界)、Cosmos(Physical AI 平台)、UniSim(通用模拟器),分析它们各自的核心创新、能力边界以及一个根本性的问题:像素级相关性是否等于物理理解?
1. Sora:视频生成模型作为世界模拟器
1.1 OpenAI 的定位
OpenAI 在 Sora 的技术报告中写道:
"我们发现视频模型在大规模训练后展现出了许多有趣的涌现能力。这些能力使 Sora 能够模拟物理世界中人、动物和环境的某些方面。"
这句话背后的逻辑是:如果模型能够准确预测视频的每一帧,它就必须在某种程度上理解场景中物体的三维结构、运动规律和相互作用——否则它无法生成物理上合理的画面。
1.2 架构要点
Sora 的架构未完全公开,但从技术说明和第三方分析可推断其核心流程:
- 时空 Patch 化:将视频分为 \(T \times H \times W\) 的时空 patch(类似 ViT 对图像的处理)
- VAE 编码:先用 VAE 将视频压缩到低维潜空间
- 扩散去噪:在潜空间中用 Diffusion Transformer(DiT) 做去噪生成
- 可变分辨率/时长:支持不同宽高比和视频长度(NaViT 式的灵活 patch 化)
1.3 "世界模拟器"的能力与局限
涌现能力(据官方报告):
3D 一致性:摄像机移动时场景几何保持一致
对象持久性:物体被遮挡后重新出现时保持一致
简单物理交互:球的弹跳、液体的流动
局限性:
复杂物理推理失败:反重力、物体穿透
长程因果关系弱:前后帧的因果链容易断裂
本质上是统计相关性而非物理因果模型
1.4 数学分析与 2025 年的理论反思:为什么像素相关性 ≠ 物理理解?
设 \(p_\theta(V)\) 为视频生成模型学到的分布,\(p_{\text{real}}(V)\) 为真实视频分布。
即使 \(D_{\text{KL}}(p_{\text{real}} \| p_\theta) \to 0\)(模型完美拟合数据分布),也不意味着模型理解了物理:
命题(统计模拟的不充分性):存在视频分布 \(p(V)\) 和两个模型 \(M_1, M_2\),使得 \(p_{M_1}(V) = p_{M_2}(V) = p(V)\),但 \(M_1\) 内部包含正确的物理模型而 \(M_2\) 不包含。两者在分布匹配意义下不可区分,但在反事实推理("如果重力加倍会怎样?")上表现不同。
2024-2025 年的实证与机理研究:
为了回答"Sora 等模型离真正的世界模型还有多远",2024 年末的一项重要研究(How Far is Video Generation from World Model: A Physical Law Perspective)构建了一个受经典力学控制的 2D 碰撞测试床。研究发现:
- 泛化能力的三层测试:该研究用 2D
碰撞场景设计了三个泛化难度递增的测试。用一个具体例子来说明——假设训练数据中有"红球以
5m/s 撞击蓝球"和"绿球以 3m/s 撞击黄球"这类场景:
- 分布内(In-distribution):测试场景和训练数据来自同一分布——比如还是"红球以 5m/s 撞蓝球",只是换了一个随机种子。结果:完美。这不意外,相当于"考试题和练习题一模一样"。
- 组合泛化(Compositional):把训练中见过的"零件"重新组合——比如训练中见过"红球"和"5m/s",但没见过"红球以 5m/s 撞绿球"。结果:有一定能力,且增大模型规模能提升(出现了 Scaling law)。
- 分布外(Out-of-distribution):给出训练中从未见过的物理参数——比如训练只有 1~5m/s 的速度,测试用 10m/s。结果:彻底失败,且增大模型规模几乎没有改善。OOD 误差比分布内高一个数量级。
- 基于案例的模仿,而非规则抽象:为什么分布外会失败?机理分析表明,视频生成模型并没有学到"动量守恒"这样的通用物理规则。它做的是查表式推理——遇到新场景时,模型在"记忆库"中找到最相似的训练样本,然后模仿那个样本的结果。如果训练中没有类似的案例(OOD),模型就无从模仿,输出的物理行为完全错误。
- 特征优先级的偏置:在"查表"时,模型并不根据物理相关的特征(如速度、质量)来检索,而是优先匹配表观特征。优先级顺序为:颜色 > 大小 > 速度 > 形状。也就是说,一个"红色慢球"和一个"红色快球"在模型看来比"蓝色快球"和"红色快球"更相似——模型在用颜色而非速度来"理解"物理。
结论:单靠扩大模型规模(Scaling alone)不足以让视频生成模型发现基础的物理定律。这直接挑战了"只要数据足够多,视频模型就能自然涌现出物理引擎"的乐观假设。
2. Genie:可交互的世界模型
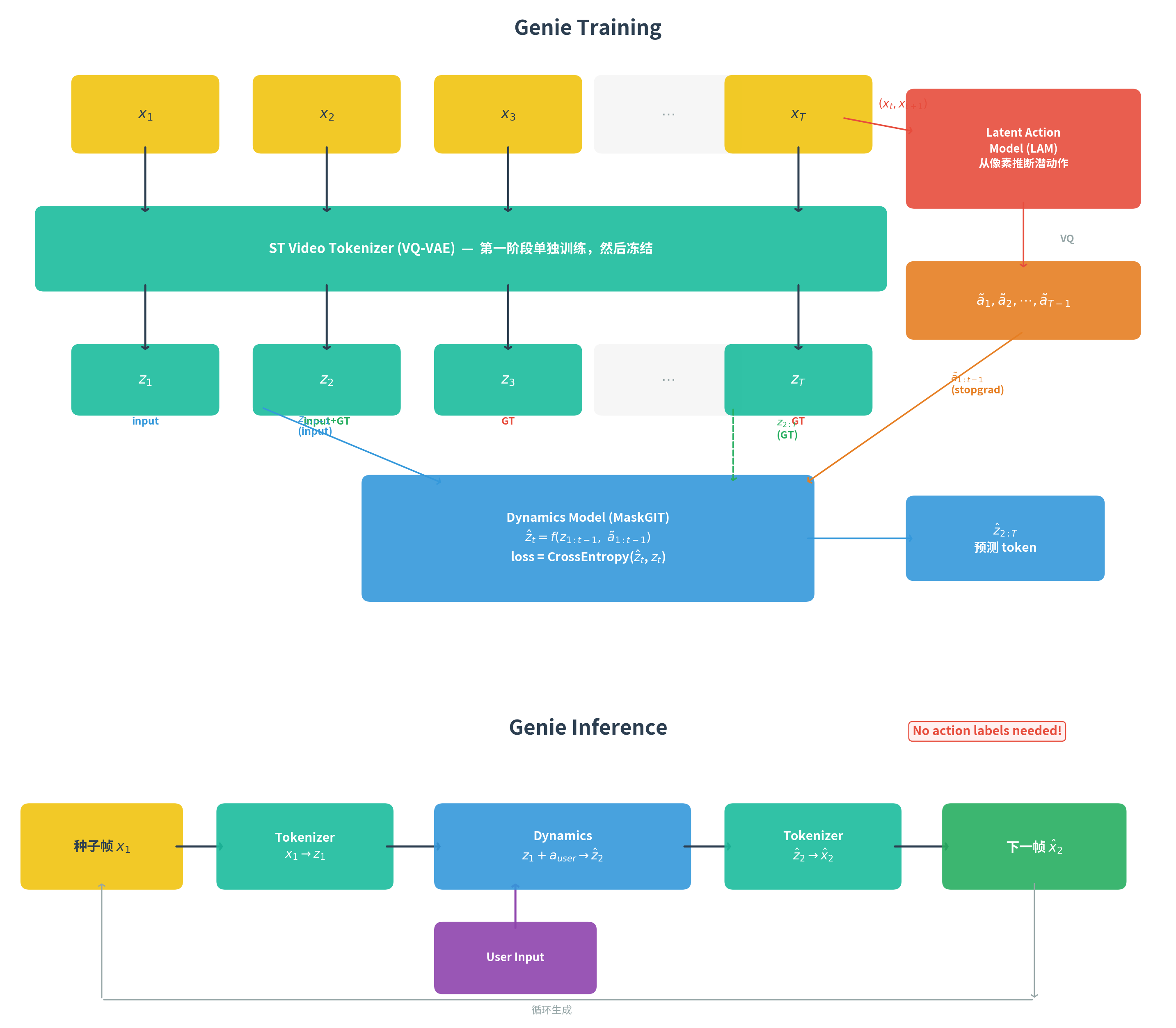
2.1 核心创新:从视频中学习潜动作
Sora 的一大局限是不可交互——它只能生成视频,用户无法在生成的世界中"行动"。Genie(DeepMind, ICML 2024)解决了这个问题,但面临一个更根本的挑战:大多数互联网视频没有动作标注。人玩游戏的视频只有画面,没有对应的按键记录。
如果需要成对的 \((帧_t, 动作_t, 帧_{t+1})\) 数据才能训练可交互的世界模型,数据量就被严重限制。Genie 的突破性方案:从视频中自动发现潜在动作空间——不需要任何动作标注。
2.2 三模块架构与训练流程
上图展示了 Genie 的完整架构,由三个模块组成:
\[ \text{Genie} = \underbrace{\text{ST-Tokenizer}}_{\text{时空视频编码}} + \underbrace{\text{Latent Action Model}}_{\text{潜动作推断}} + \underbrace{\text{Dynamics Model}}_{\text{下一帧预测}} \]
训练分两个阶段:
阶段一:单独训练 ST Video Tokenizer(图中绿色块)。Tokenizer 本身是一个 VQ-VAE,使用 ST-Transformer(Spatio-Temporal Transformer)作为编码器和解码器骨架。它将 \(T\) 帧原始视频 \(x_{1:T} \in \mathbb{R}^{T \times H \times W \times C}\) 压缩为每帧 \(D\) 个离散 token:
\[ z_{1:T} = \text{VQ}(\text{Enc}(x_{1:T})) \in \mathbb{I}^{T \times D} \]
与只做空间压缩的 tokenizer 不同,ST-ViViT 的编码器在时间维度上使用因果注意力——每个 token \(z_t\) 不仅包含当前帧 \(x_t\) 的空间信息,还隐式携带了 \(x_{1:t}\) 的时序信息。训练目标是标准的 VQ-VAE 重建损失:让解码器从离散 token 重建原始像素。训练完成后 Tokenizer 被冻结,后续阶段不再更新。
阶段二:冻结 Tokenizer,同时(co-train) 训练 LAM 和 Dynamics Model——注意不是先训 LAM 再冻结,两者同步优化但通过 stopgrad 保证梯度互不干扰:
Latent Action Model(图中红色块):直接从原始像素接收连续帧 \((x_{1:t}, x_{t+1})\),推断潜动作 \(\tilde{a}_t \in \{1, \ldots, N_a\}\)。\(N_a\) 是通过 VQ 离散化后的潜动作空间大小(论文中 \(N_a = 8\))。\(\tilde{a}_t\) 不是人类标注的,而是模型自动从帧间变化中推断的。LAM 内部还有一个解码器,用 \((x_{1:t}, \tilde{a}_t)\) 重建 \(x_{t+1}\),以 VQ-VAE 重建损失单独优化 LAM 参数。
Dynamics Model(图中蓝色块):接收前 \(t-1\) 帧的 token \(z_{1:t-1}\) 和对应的潜动作 \(\tilde{a}_{1:t-1}\)(stopgrad——不把 Dynamics 的梯度回传给 LAM),预测第 \(t\) 帧的 token \(\hat{z}_t\):
\[ \hat{z}_t = \text{Dynamics}(z_{1:t-1}, \tilde{a}_{1:t-1}) \]
GT 是 Tokenizer 编码真实帧得到的 \(z_t\),损失是 cross-entropy。图中 token 下方的颜色标注了它们的双重角色:\(z_1\) 仅作为 input(蓝色),\(z_2\) 既是 input 也是前一步的 GT(绿色),\(z_T\) 仅作为 GT(红色)。Dynamics Model 使用 MaskGIT 式并行解码——一次性预测所有 token 的初始估计,然后迭代精化最不确定的位置。
2.3 从观看到操控
推理时(图下半部分):LAM 被丢弃(只保留其 VQ codebook),用户通过手柄选择一个离散动作替代 LAM 的输出。完整流程:种子帧 \(x_1\) → Tokenizer 编码为 \(z_1\) → Dynamics Model 接收 \(z_1\) + 用户动作 → 预测 \(\hat{z}_2\) → Tokenizer 解码为下一帧图像 \(\hat{x}_2\) → 循环生成,形成可交互的"可玩"环境。
关键问题:从零学出来的潜动作,推理时不会乱吗?
LAM 是从零开始训练的,潜动作编码确实是"随机分配"的——编码 3 可能对应"向右",也可能对应"跳跃",取决于训练收敛到的结果。那为什么推理时用户选一个编码,模型能给出一致的行为?
答案在于 LAM 的信息瓶颈设计。LAM 内部是一个编码器-解码器结构:编码器看到 \((x_{1:t}, x_{t+1})\)(过去帧+下一帧),输出潜动作 \(\tilde{a}_t\);解码器只看到 \((x_{1:t}, \tilde{a}_t)\)(过去帧+潜动作),必须重建 \(x_{t+1}\)。解码器唯一的新信息来源就是 \(\tilde{a}_t\)——过去帧它已经知道了,所以 \(\tilde{a}_t\) 被迫编码"从过去到未来最关键的变化"。
同时,VQ codebook 只有 8 个编码。这个极小的瓶颈逼迫模型只能编码最粗粒度的语义变化(如"向左走"、"向右跳"),而不是像素级细节。论文观察到每个编码的含义在不同输入下保持一致——编码 3 不管在什么场景下都大致表示同一种运动方向。用户第一次玩时确实不知道哪个编码对应什么,但这就像拿到一个陌生手柄,试几下就能学会按钮映射——而且映射是稳定的。
但你的直觉指向了一个真实的局限:这种无监督学出的潜动作在训练分布外的场景中可能失效。如果训练数据以平台游戏为主,潜动作自然对应"跑跳"类运动;换到一个驾驶场景,同样的 8 个编码可能完全无法表达"转弯"、"加速"等动作。这正是 Genie 不如 V-JEPA 2-AC 那种有显式动作标注系统的地方——后者的动作空间是明确定义的 7 维连续向量(3D 位置 + 3D 朝向 + 夹爪),不存在"编码含义不清"的问题。
2.4 规模与结果
| 配置 | 值 |
|---|---|
| 模型参数 | 11B |
| 训练数据 | 大规模互联网 2D 平台游戏视频 |
| 潜动作数 | 8 个离散动作 |
| 帧率 | 1 FPS(受限于计算) |
Genie 证明了无需动作标注就能从视频中学习可交互的世界模型。
2.5 Genie 2:从 2D 到 3D
Genie 2(DeepMind, 2024 年 12 月)是一个根本性的飞跃——从 2D 平台游戏扩展到逼真的 3D 环境:
- 架构升级:从 MaskGIT 改为自回归潜在扩散模型(Autoregressive Latent Diffusion),更适合高保真 3D 场景
- 真实控制:支持键盘鼠标输入,模型自动识别场景中的可控角色
- 长程记忆:能记住离开视野的场景区域,返回时正确重新渲染(但一致性通常维持在 10-20 秒)
- 涌现物理行为:水的反射、物体的碰撞反弹、NPC 的自主行为
3. Cosmos:世界基础模型平台

3.1 NVIDIA 的定位
Sora 面向内容创作,Genie 面向游戏/具身 AI——但工业界最需要世界模型的领域是机器人和自动驾驶。NVIDIA 的 Cosmos(arXiv:2501.03575, 2025)不只是一个模型,而是一个完整的平台——为 Physical AI 提供从数据处理到模型训练到部署的全套基础设施。
3.2 平台组成
Cosmos 平台
├── 视频策展管线(数据清洗、过滤、字幕生成)
├── 视频 Tokenizer(连续 / 离散)
├── Cosmos-Predict(预训练世界模型)
├── Cosmos-Transfer(条件化世界生成)
└── 后训练工具(面向特定领域微调)3.3 Cosmos-Predict
基于 Diffusion Transformer 的视频预测模型,预训练在大规模真实世界视频上:
\[ \hat{V}_{t+1:t+K} = \text{Cosmos-Predict}(V_{1:t}, c) \]
其中 \(c\) 为可选的条件信号(文本描述、动作指令等)。
3.4 Cosmos-Transfer1:多模态控制
Cosmos-Transfer1 支持多种结构化控制条件进行世界变换:
| 控制条件 | 含义 |
|---|---|
| 深度图 | 场景的 3D 结构 |
| 语义分割 | 物体类别 |
| 边缘图 | 轮廓信息 |
| LiDAR 点云 | 激光雷达数据 |
| HD Map | 高精地图 |
核心用途:Sim2Real——将仿真器的结构化输出(深度、分割)转化为逼真的视频。
model = CosmosTransfer.from_pretrained(...) # 加载预训练的 Cosmos-Transfer1 模型
conditions = { # 输入多种结构化条件
"depth": depth_map, # 深度图序列 (T, H, W)
"segmentation": seg_map, # 语义分割序列 (T, H, W)
"hdmap": hd_map, # 高精地图
}
weights = {"depth": 0.8, "seg": 0.5, "hdmap": 0.3} # 各条件的权重
video = model.generate(conditions, weights) # 多条件融合 → 生成逼真驾驶视频4. UniSim:用视频模型替代仿真器
4.1 动机:仿真器的瓶颈
训练机器人的传统流程是:先在仿真器中学策略,再迁移到真实世界(Sim2Real)。但建造高保真仿真器极其昂贵——每个新场景都需要手工建模 3D 资产、物理参数、光照条件。
UniSim(Yang, S., ... & Abbeel, P., ICLR 2024, Outstanding Paper Award)提出了一个激进的替代方案:直接从真实视频中学一个"通用模拟器",用它替代手工仿真器来训练 RL 智能体。
4.2 统一多源数据
UniSim(5.6B 参数,512 TPU-v3 训练 20 天)将多种不同标注水平的数据统一到同一个视频扩散框架中:
- 互联网视频(无动作标注):提供丰富的视觉多样性
- 机器人操作视频(有动作标注):提供动作-效果的因果关系
- 导航视频(有 pose 标注):提供空间理解
- 仿真器渲染(有完整标注):提供精确的物理参考
4.3 条件生成接口
\[ V_{t+1:t+K} = \text{UniSim}(V_{1:t}, a_t, \text{text}_t, \text{pose}_t, \ldots) \]
UniSim 支持多种条件信号的任意组合——高级指令("打开抽屉")和低级连续动作(\(\Delta x, \Delta y\))都能处理。
4.4 零样本 Real-World 迁移
UniSim 最激动人心的结果:在 UniSim 中训练的 RL 策略可以零样本迁移到真实机器人——不需要任何真实世界的微调。这意味着视频生成模型已经学到了足够准确的视觉动力学,可以作为 RL 的训练环境使用。
5. 四大视频世界模型对比
| 维度 | Sora | Genie | Cosmos | UniSim |
|---|---|---|---|---|
| 机构 | OpenAI | DeepMind | NVIDIA | Google/Berkeley |
| 开源 | ✗ | 部分 | ✓ | ✗ |
| 可交互 | ✗ | ✓ | ✗(预测模式) | ✓ |
| 动作空间 | 无 | 潜动作(自学习) | 条件信号 | 多类型动作 |
| 3D 一致性 | 有限 | Genie 2 支持 | Sim2Real | 有限 |
| 物理理解 | 统计相关 | 涌现行为 | 领域微调 | 统计相关 |
| 目标应用 | 内容创作 | 游戏/具身 AI | 机器人/驾驶 | 通用仿真 |
6. 视频世界模型的数学框架
6.1 统一形式化
所有视频世界模型都可以用条件视频分布统一描述:
\[ p_\theta(V_{t+1:t+H} \mid V_{1:t}, c) \]
其中 \(c\) 为条件信号(动作/文本/控制图等),\(H\) 为预测时域。
不同模型的区别在于:
| 组件 | Sora | Genie | Cosmos |
|---|---|---|---|
| \(V\) 的表示 | 潜在连续 (VAE) | 离散 token (VQ) | 两者兼有 |
| 生成方式 | 扩散去噪 | MaskGIT 并行解码 | 扩散去噪 |
| \(c\) 的类型 | 文本 | 潜动作 | 多模态 |
6.2 与传统仿真器的对比
| 维度 | 传统仿真器 | 视频世界模型 |
|---|---|---|
| 物理模型 | 显式方程(\(F=ma\)) | 隐式(从数据学习) |
| 视觉真实感 | 有限(需要手工设计) | 高(从真实视频学习) |
| 开发成本 | 高(每个场景需要建模) | 低(数据驱动) |
| 物理准确性 | 高(精确方程) | 低(统计近似) |
| 可验证性 | ✓(可检查方程) | ✗(黑盒) |
| 反事实推理 | ✓(改变参数即可) | ✗(需要重新训练) |
7. 总结:像素相关性 ≠ 物理理解
视频生成世界模型代表了一种大胆的假设:通过学习预测像素,模型会隐式地学到世界的结构。 这与 JEPA 的"丢弃像素细节"形成了鲜明对照。
从目前的证据来看,这条路线取得了令人印象深刻的视觉效果,但在物理准确性上存在根本性的差距:
- "How Far" 论文(ICML 2025)表明,视频生成模型做的是"基于案例的模仿"而非"物理规则的抽象"——它在见过的场景上完美,在分布外彻底失败
- 优先级偏差:模型关注的是颜色 > 大小 > 速度 > 形状,而非物理上正确的动量、能量等守恒量
下一篇将介绍一条折中路线:不完全丢弃像素(如 JEPA),也不完全依赖像素统计(如 Sora),而是在视频生成中显式嵌入物理定律。
参考资料:
- OpenAI (2024). Video generation models as world simulators. Technical Report.
- Bruce, J., ... & Vinyals, O. (2024). Genie: Generative Interactive Environments. ICML 2024.
- NVIDIA (2025). Cosmos World Foundation Model Platform for Physical AI. arXiv:2501.03575.
- Yang, S., ... & Abbeel, P. (2024). Learning Interactive Real-World Simulators. ICLR 2024 (Outstanding Paper Award).
- Kang, B., et al. (2025). How Far is Video Generation from World Model: A Physical Law Perspective. ICML 2025. arXiv:2411.02385.