笔记|强化学习(十一):V-GRPO——用变分方法让扩散模型的在线 RL 变得简单
本文为 RL 系列第十一篇。前文详细介绍了 MDP 路线的代表作(Flow-GRPO、DanceGRPO、MixGRPO),它们通过将去噪过程建模为 MDP,利用 SDE 的高斯转移核提取 \(\log\pi_\theta\)。然而,这条路线受限于 SDE 采样器、收敛效率低、算法复杂度高。V-GRPO 另辟蹊径,回归扩散模型的变分根基,用 ELBO 代理 替代 MDP 建模,实现了更简单、更快、更强的在线 RL 后训练。
⬅️ 上一篇:笔记|强化学习(十):奖励模型全景——从基础架构到 Reward Hacking 与前沿进阶
论文:V-GRPO: Online Reinforcement Learning for Denoising Generative Models Is Easier than You Think(Stanford & Tsinghua, 2026.04)
一句话理解 V-GRPO
V-GRPO 证明了一件事:用扩散模型预训练目标(ELBO)作为 log-likelihood 的代理,配合三个方差缩减技巧和三个梯度步调节技巧,就能在图像生成的在线 RL 中全面超越所有 MDP 路线方法——而且实现更简单、训练更快。
Table 1:V-GRPO 性能与效率总览(结果为所有评估奖励函数的均值,在测试集上报告)
| 方法 | 训练步数 | NFE\(_{\pi_{\theta_\text{old}}}\) | NFE\(_{\pi_\theta}\) | 平均奖励 |
|---|---|---|---|---|
| FLUX.1-dev | — | — | — | 1.25 |
| + BranchGRPO | 300 | 13.68 | 13.68 | 1.40 |
| + MixGRPO | 300 | 25 | 4 | 1.41 |
| + V-GRPO | 150 | 16 + 4 | 4 | 1.42 |
| + V-GRPO | 300 | 16 + 4 | 4 | 1.45 |
| SD 3.5 M (w/o CFG) | — | — | — | 0.95 |
| + DiffusionNFT | 1.7K | 40 + 40 | 40 | 1.71 |
| + V-GRPO | 580 | 40 + 6.9 | 6.9 | 1.71 |
NFE\(_{\pi_{\theta_\text{old}}}\) = 采样阶段的函数评估次数(V-GRPO 包含采样步数 + \(N_\text{MC}\));NFE\(_{\pi_\theta}\) = 训练阶段的函数评估次数。V-GRPO 在 150 步时即超越 MixGRPO 300 步的性能。
为什么需要 V-GRPO:MDP 路线的困境
在第五篇和第九篇中,我们详细推导了 MDP 路线的核心机制:将去噪过程建模为马尔可夫决策过程,通过 ODE→SDE 转换注入随机性,利用高斯转移核的对数概率累加得到 \(\log\pi_\theta\)。
这条路线在概念上是清晰的,但在工程中暴露了三个根本性问题:
问题一:收敛慢,训练效率低。 MDP 目标将整条去噪轨迹拆分为逐步的状态-动作序列,每步的梯度信号极其稀疏。即便 MixGRPO 用滑动窗口将 MDP 缩短到 4 步,仍然需要 300 个 iteration 才能收敛。
问题二:采样器被锁死。 MDP 建模要求使用一阶 SDE 离散化(Euler-Maruyama),因为只有 SDE 步才有可计算的高斯转移核概率。这直接排除了更高效的高阶 ODE 求解器(如 DPM-Solver++)在训练采样中的使用。即使 MixGRPO 允许窗口外用高阶求解器,窗口内仍被限制在一阶 SDE。
问题三:优化与采样高度耦合。 importance ratio 的计算依赖 rollout 时每步的转移核参数(\(\mu_\theta, \sigma_t\)),这意味着采样配置的任何改动(步数、求解器类型、噪声调度)都直接影响训练目标。为了修补这种耦合,MixGRPO 引入了滑动窗口+课程学习,BranchGRPO 设计了分支树——但代价是越来越复杂的算法和更多的超参数。
这些问题的根源是同一个:MDP 路线把"如何采样"和"如何优化"绑在了一起。
V-GRPO 的核心洞察是:完全可以跳过 MDP 建模,直接用扩散模型预训练时就在用的 ELBO 作为 log-likelihood 的可解析代理——这让优化与采样彻底解耦。
V-GRPO 的理论框架
从 ELBO 到 likelihood 代理
在扩散模型理论篇中我们知道,扩散模型的预训练本质上是在最大化数据的证据下界(ELBO):
\[\text{ELBO}_\theta(x) \leq \log \pi_\theta(x)\]
对于连续时间的扩散模型,ELBO 有一个简洁的形式:
\[\text{ELBO}_\theta(x) = -\frac{1}{2}\mathbb{E}_{t, \epsilon}\left[-\frac{d\lambda_t}{dt}\|\epsilon_\theta(z_t) - \epsilon\|_2^2\right] + C\]
其中 \(\lambda_t = \log(a_t^2/b_t^2)\) 是 log 信噪比,\(C\) 是与模型参数无关的常数。
V-GRPO 的关键操作:在 GRPO 的 importance ratio 中,将不可解析的 \(\log\pi_\theta(o_i|c)\) 替换为条件化的预训练损失(负加权 ELBO):
\[\log\pi_\theta(o_i|c) \leftarrow -\mathcal{L}_w(\theta|o_i, c) = -\mathbb{E}_{t, \epsilon}\left[w_t\|\text{NN}_t^\theta(z_t, c) - r_t(o_i, \epsilon)\|_2^2\right]\]
其中 \(o_i\) 是已生成的输出图像,\(c\) 是文本条件,\(z_t = a_t \cdot o_i + b_t \cdot \epsilon\) 是对 \(o_i\) 加噪后的中间状态。
importance ratio 变成了:
\[\rho_i^\theta = \exp\left(-\hat{\mathcal{L}}(\theta|o_i, c) + \hat{\mathcal{L}}(\theta_\text{old}|o_i, c)\right)\]
在实践中,用 Monte Carlo 采样 \(N_\text{MC}\) 个时间步-噪声对来近似期望:
\[\hat{\mathcal{L}}_w(\theta|o_i, c) = \frac{1}{N_\text{MC}}\sum_{j=1}^{N_\text{MC}} \ell_i^\theta(t_j, \epsilon_j)\]
其中 \(\ell_i^\theta(t_j, \epsilon_j) = w_{t_j}\|\text{NN}_{t_j}^\theta(z_{t_j}, c) - r_{t_j}(o_i, \epsilon_j)\|_2^2\)。
为什么直接用 ELBO 代理会失败
尽管 ELBO 代理在理论上很优美,但之前的工作(DDPO、FPO)在视觉生成任务上用这种方法时效果很差。V-GRPO 通过实验诊断出了根本原因:ELBO 代理的方差过大。
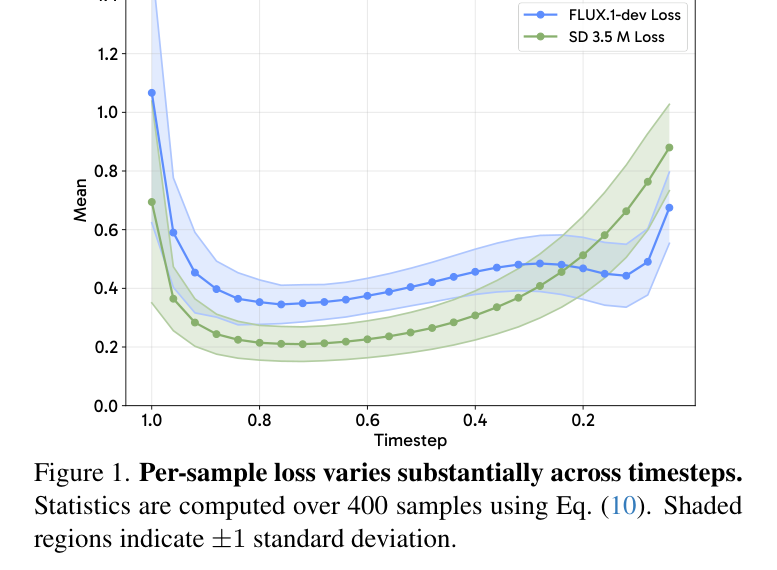
如上图所示,per-sample loss \(\ell_i^\theta(t_j, \epsilon_j)\) 在不同时间步 \(t_j\) 上的量级差异极大(可达数量级)。当为每个输出 \(o_i\) 独立采样时间步-噪声对 \(\{(t_j, \epsilon_j)\}\) 时,同一组内不同输出的代理值因为采样到不同的时间步区域而产生巨大差异——这种差异不反映真实的 likelihood 差别,而是来自随机采样的噪声。
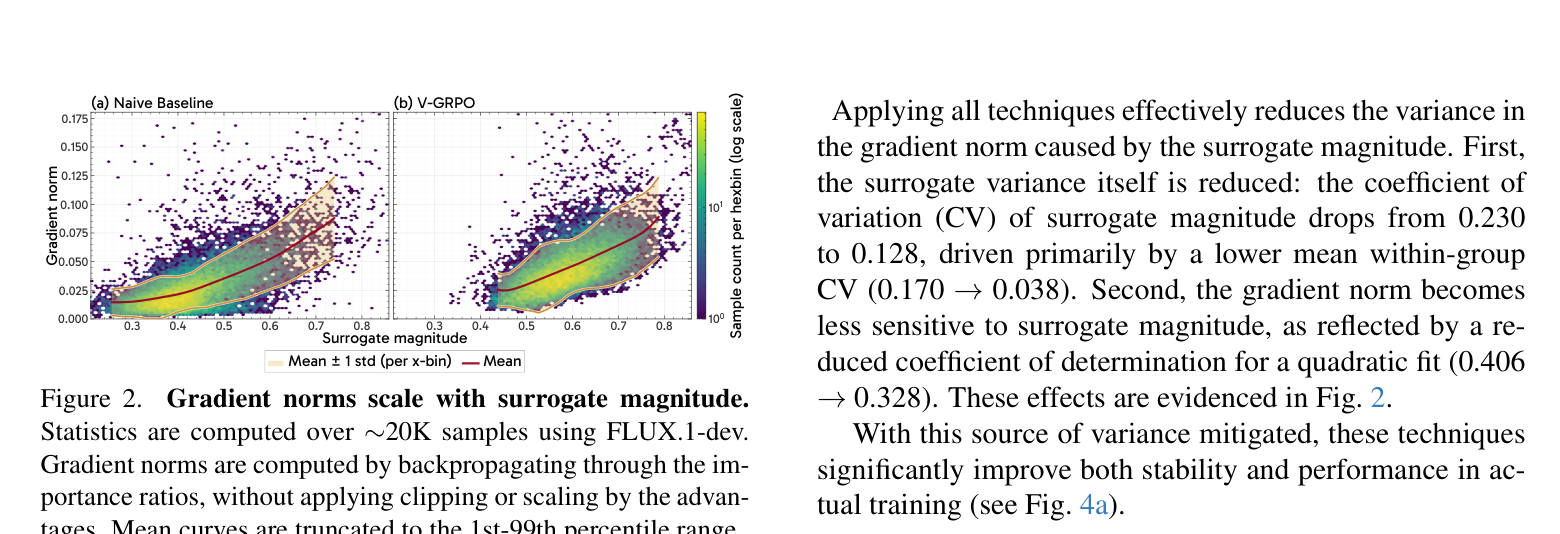
更糟糕的是,梯度范数与代理量级呈强正相关(Fig. 2a):代理值的随机波动直接传导为高方差的梯度,淹没了来自奖励的真实学习信号。
三个方差缩减技术:让 ELBO 代理变得稳定
V-GRPO 提出三个简单但关键的方差缩减技术,每个单独看都不起眼,但组合起来效果显著。
1. 组内共享时间步-噪声对(Group-Shared Timestep-Noise Pairs)
问题:如果为同一 prompt 的 \(G\) 个输出各自独立采样 \(\{(t_j, \epsilon_j)\}\),不同输出可能采到完全不同的时间步区域,导致代理值的差异来自采样噪声而非真实 likelihood 差别。
解决方案:对于同一个 prompt \(c\),随机采样一组固定的时间步-噪声对 \(\{(t_j, \epsilon_j)\}_{j=1}^{N_\text{MC}}\),并在该 prompt 下所有 \(G\) 个输出上共享使用。
效果:通过锚定所有输出到相同的随机基底,消除了组内方差的主要来源,使不同输出的代理值具有直接可比性。
在代码中,这对应 grpo_init_same 参数设为
"batch" 时的行为:
# 同一个 batch 共享时间步和噪声
minibatch_sigmas = stratified_sample(sigmas, N_MC).repeat(batch_size, 1)
minibatch_noise = randn(1, N_MC, ...).repeat(batch_size, 1, 1, 1)
# 广播到所有 GPU
dist.broadcast(minibatch_sigmas, src=0)
dist.broadcast(minibatch_noise, src=0)2. 分层时间步采样(Stratified Timestep Sampling)
问题:标准的均匀时间步采样可能导致所有 \(N_\text{MC}\) 个样本聚集在某个时间区域,造成覆盖不均。
解决方案:将离散化的时间步调度表等分为 \(N_\text{MC}\) 段,从每段中恰好抽取一个时间步。这保证了噪声调度的全局均匀覆盖。
if args.stratified_sampling:
minibatch_sigmas = torch.cat([
chunk[torch.randint(len(chunk), (1,))]
for chunk in torch.tensor_split(sigmas, train_timesteps)
], dim=0)3. 自适应损失加权(Adaptive Loss Weighting)
问题:不同时间步的 loss 量级差异巨大(Fig. 1),直接平均会让高噪声步主导梯度。
解决方案分两步:
(a) x-prediction 重参数化:将模型输出重新参数化为 x-prediction(对 Rectified Flow:\(x_\theta(z_t) = z_t - t \cdot \text{NN}_t^\theta(z_t)\)),在高噪声水平下隐式赋予更大权重。
(b) 自归一化:用 stop-gradient 的 L1 范数归一化每个样本的损失,使不同量级的样本对梯度的贡献大致对齐:
\[\mathcal{L}_\text{adaptive}(\theta|o_i, c) = \mathbb{E}_{t, \epsilon}\left[\frac{\|x_\theta(z_t) - o_i\|_2^2}{\text{sg}\left(\frac{1}{d}\|x_\theta(z_t) - o_i\|_1\right)}\right]\]
其中 \(\text{sg}(\cdot)\) 是 stop-gradient 算子,\(d\) 是 \(o_i\) 的维度。
在代码中的实现:
def calc_surrogate(args, transformer, ..., latents, noise, sigmas):
noisy_latents = (1.0 - sigmas) * latents + sigmas * noise
model_pred = transformer(hidden_states=noisy_latents, ...)
# x-prediction 重参数化
x0_pred = noisy_latents - sigmas * model_pred
surrogate = -torch.mean(
((x0_pred.float() - latents.float()) ** 2).reshape(noise.shape[0], -1),
dim=1,
)
# 自归一化
if args.self_normalize:
surrogate = surrogate / torch.mean(
torch.abs((x0_pred.detach().float() - latents.float())
.reshape(noise.shape[0], -1)),
dim=1,
)
return surrogate三个技术的联合效果:代理值的变异系数(CV)从 0.230 降至 0.128,组内 CV 从 0.170 降至 0.038。梯度范数对代理量级的依赖性显著降低(二次拟合的 \(R^2\) 从 0.406 降至 0.328)。在训练中,naive baseline 出现严重振荡甚至发散,而 V-GRPO 稳定收敛到更高的奖励值。
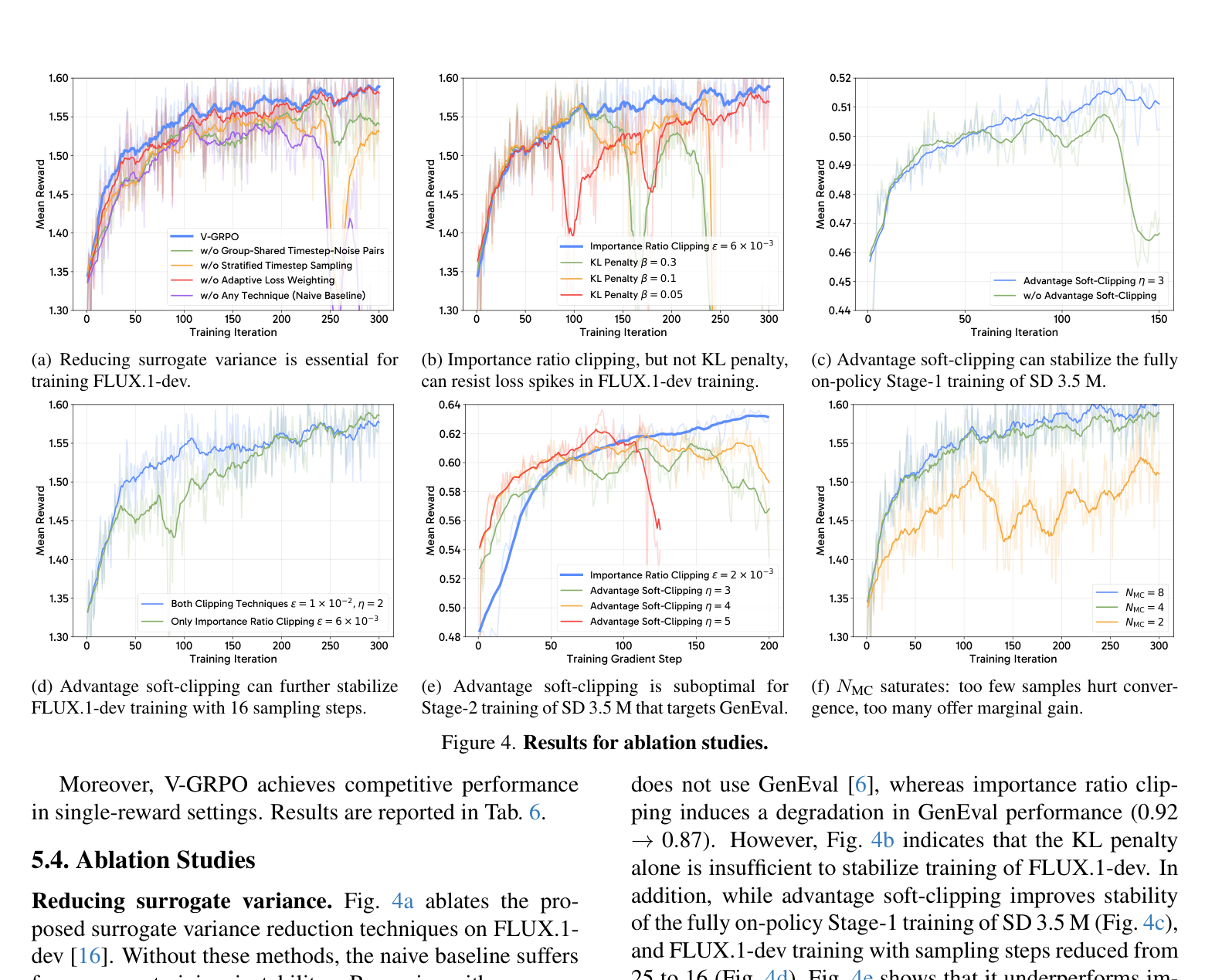
三个梯度步调节技术:控制策略更新幅度
方差缩减解决了代理函数本身的噪声问题,但稳定的在线 RL 还需要防止过激的策略更新。V-GRPO 根据不同训练场景,选择性地启用以下三种技术。
1. 重要性比率裁剪(Importance Ratio Clipping)
标准的 PPO 裁剪,将 importance ratio \(\rho_i^\theta\) 限制在 \([1-\varepsilon, 1+\varepsilon]\) 范围内。在大多数标准训练配置中,这已经足够保证稳定性。
2. KL 惩罚(KL Penalty)
当需要保留前序训练阶段习得的能力时(如 Stage 5 添加 OCR 奖励时不能让 GenEval 能力退化),引入行为策略 \(\pi_{\theta_\text{old}}\) 的 KL 惩罚:
\[D_i^\text{simple}(\pi_\theta\|\pi_{\theta_\text{old}}) = \mathbb{E}_{t, \epsilon}\left[\|x_\theta(z_t) - x_{\theta_\text{old}}(z_t)\|_2^2\right]\]
这里使用的是 x-prediction 空间的 MSE,与 Flow-GRPO 中用速度场 MSE 近似 KL 散度的思路类似,但 V-GRPO 利用已存储的时间步-噪声对来计算,无需额外的参考模型推理——只需存储 \(\theta_\text{old}\) 下的预测结果 \(\ell_i^{\theta_\text{old}}(t_j, \epsilon_j)\)。
3. 优势软裁剪(Advantage Soft-Clipping)
当采用完全 on-policy 训练(每个 iteration 只做 1 次梯度步,\(\theta \equiv \theta_\text{old}\))时,前两种技术均失效(ratio 恒为 1,KL 恒为 0)。V-GRPO 提出用双曲正切函数对优势值做软裁剪:
\[A_i^\text{soft} = \eta \cdot \tanh\left(\frac{1}{\eta}A_i\right)\]
小优势保持线性敏感,极端优势被平滑地压缩到 \([-\eta, \eta]\) 范围内。实验表明,这在 SD 3.5 M 的 Stage 1(完全 on-policy,150 次 iteration)中至关重要。
技术选择策略(来自 V-GRPO 论文的最佳实践):
| 训练场景 | 裁剪 | KL 惩罚 | 优势软裁剪 |
|---|---|---|---|
| 标准多步训练(FLUX.1-dev 主实验) | ✅ | ❌ | ❌ |
| 完全 on-policy 训练(SD 3.5 M Stage 1/3) | ❌ | ❌ | ✅ |
| 需要保留先前能力(SD 3.5 M Stage 5) | ❌ | ✅ | ❌ |
| 减少采样步数时(16 步 FLUX.1-dev) | ✅ | ❌ | ✅ |
完整算法流程
将上述所有组件组合在一起,V-GRPO 的完整训练流程如下:

与 MDP 路线训练流程的关键区别:
"""
V-GRPO 训练主循环(精简伪代码)
与 Flow-GRPO/MixGRPO 的 5 个核心差异:
1. 采样: 可用任意求解器(包括高阶 ODE),无需 SDE
2. log_prob: 不依赖转移核,而是对最终输出 o_i 算预训练损失
3. 噪声对: 组内共享 + 分层采样
4. 损失权重: 自适应 x-prediction 归一化
5. 解耦: 采样配置变化不影响训练目标
"""
for iteration in range(M):
θ_old ← θ
# Phase 1: 采样(可用任何求解器!)
for each prompt c:
生成 G 个输出 {o_i} ~ π_{θ_old}(·|c) # 使用 DPM-Solver++ ODE
# 组内共享 + 分层采样时间步-噪声对
{(t_j, ε_j)} ← stratified_sample(N_MC) # 共享!
# 计算 ELBO 代理(用 θ_old)
for each o_i:
L̂(θ_old | o_i, c) = mean_j[ adaptive_loss(θ_old, o_i, t_j, ε_j) ]
# 计算奖励和优势
R_i = reward_model(o_i, c)
A_i = normalize(R_i)
A_i^soft = η · tanh(A_i / η) # 软裁剪
# Phase 2: 梯度更新(N 步)
for gradient_step in range(N):
sample batch from collected data
# 用当前 θ 重算 ELBO 代理
L̂(θ | o_i, c) = mean_j[ adaptive_loss(θ, o_i, t_j, ε_j) ]
# importance ratio
ρ_i = exp(-L̂(θ | o_i, c) + L̂(θ_old | o_i, c))
# PPO 裁剪目标
J = min(ρ_i · A_i^soft, clip(ρ_i, 1-ε, 1+ε) · A_i^soft)
# KL 惩罚(可选)
KL = ||x_θ(z_t) - x_{θ_old}(z_t)||²
# 更新
θ ← optimizer(θ, ∇_θ(J - β·KL))注意 Phase 1 中的采样可以使用 DPM-Solver++ 等高阶 ODE 求解器——这是 V-GRPO 解耦优化与采样后获得的重大收益。虽然使用更高效的采样器意味着无法复用 rollout 时的模型预测来计算 importance ratio(因为 ODE 采样的轨迹中间状态与 ELBO 代理需要的 \((t_j, \epsilon_j)\) 不对应),但 ELBO 代理只需要在最终输出 \(o_i\) 上额外做 \(N_\text{MC}\) 次前向传播即可,总体仍然高效。
实验结果
FLUX.1-dev 主实验
V-GRPO 在 FLUX.1-dev 上训练 300 个 iteration,使用 HPSv2.1、PickScore、ImageReward、UnifiedReward 四个奖励函数的组合。
Table 2:FLUX.1-dev 多奖励实验详细结果(所有方法训练 300 步)
| 方法 | NFE\(_{\pi_{\theta_\text{old}}}\) | NFE\(_{\pi_\theta}\) | HPS-v2.1 | PickScore | ImageReward | UnifiedReward |
|---|---|---|---|---|---|---|
| FLUX.1-dev 基线 | — | — | 0.313 | 0.227 | 1.088 | 3.370 |
| + DanceGRPO | 25 | 4 | 0.334 | 0.225 | 1.335 | 3.374 |
| + BranchGRPO | 13.68 | 13.68 | 0.363 | 0.229 | 1.603 | 3.386 |
| + MixGRPO | 25 | 4 | 0.367 | 0.237 | 1.629 | 3.418 |
| + V-GRPO | 16 + 4 | 4 | 0.372 | 0.241 | 1.731 | 3.437 |
V-GRPO 在全部四个奖励指标上均超越所有基线。与 DanceGRPO 相比,ImageReward 提升 30%(1.335→1.731)。
关键结果:
- V-GRPO 在所有四个奖励指标上均超越所有基线方法
- 比 MixGRPO 快 2 倍(150 个 iteration 即超越 MixGRPO 300 个 iteration 的性能)
- 与 DanceGRPO(NFE=25)相比,ImageReward 提升 30%(1.335→1.731)
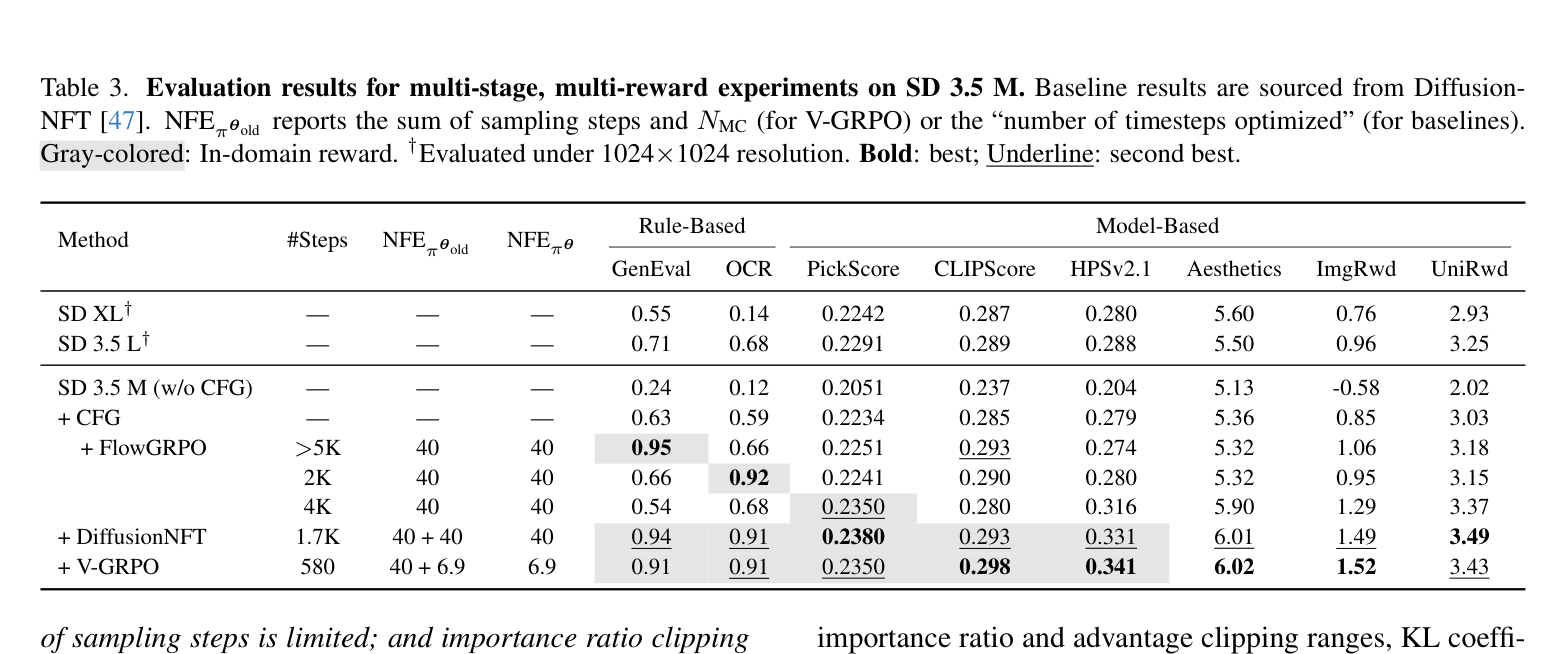

SD 3.5 M 多阶段实验
SD 3.5 M 采用 DiffusionNFT 的五阶段训练课程(GenEval → OCR → 人类偏好),运行 580 次梯度更新。
Table 3:SD 3.5 M 多阶段多奖励实验详细结果
| 方法 | 步数 | GenEval | OCR | PickScore | HPSv2.1 | Aesthetics | ImgRwd | UniRwd |
|---|---|---|---|---|---|---|---|---|
| SD 3.5 M (w/o CFG) | — | 0.24 | 0.12 | 0.2051 | 0.204 | 5.13 | -0.58 | 2.02 |
| + CFG | — | 0.63 | 0.59 | 0.2234 | 0.279 | 5.36 | 0.85 | 3.03 |
| + FlowGRPO | >5K | 0.95 | 0.66 | 0.2251 | 0.274 | 5.32 | 1.06 | 3.18 |
| + DiffusionNFT | 1.7K | 0.94 | 0.91 | 0.2380 | 0.331 | 6.01 | 1.49 | 3.49 |
| + V-GRPO | 580 | 0.91 | 0.91 | 0.2350 | 0.341 | 6.02 | 1.52 | 3.43 |
V-GRPO 仅用 580 步即匹配 DiffusionNFT 1700 步的性能,同时在 HPSv2.1 和 ImageReward 上反超。

关键结果:
- V-GRPO 匹配 DiffusionNFT 的性能
- 梯度步数仅为 DiffusionNFT 的 1/3(580 vs 1700)
- 平均 NFE 仅 53.8(DiffusionNFT 为 120)
Table 5:SD 3.5 M 各训练阶段的步数与 NFE 对比
| 训练阶段 | DiffusionNFT 步数 | DiffusionNFT NFE | V-GRPO 步数 | V-GRPO NFE |
|---|---|---|---|---|
| Stage 1(人类偏好) | ~800 | 120 | 150 | 48 |
| Stage 2(GenEval) | ~300 | 120 | 200 | 60 |
| Stage 3(人类偏好) | ~200 | 120 | 150 | 48 |
| Stage 4(GenEval) | ~200 | 120 | 50 | 60 |
| Stage 5(OCR) | ~100 | 120 | 30 | 60 |
| 总计 | ~1700 | 120 | 580 | 53.8 |
DiffusionNFT 各阶段步数为近似值(因使用了 early stopping),V-GRPO 为精确值。V-GRPO 实现了 3× 训练加速,同时平均每步的 NFE 也更低(53.8 vs 120)。
消融实验
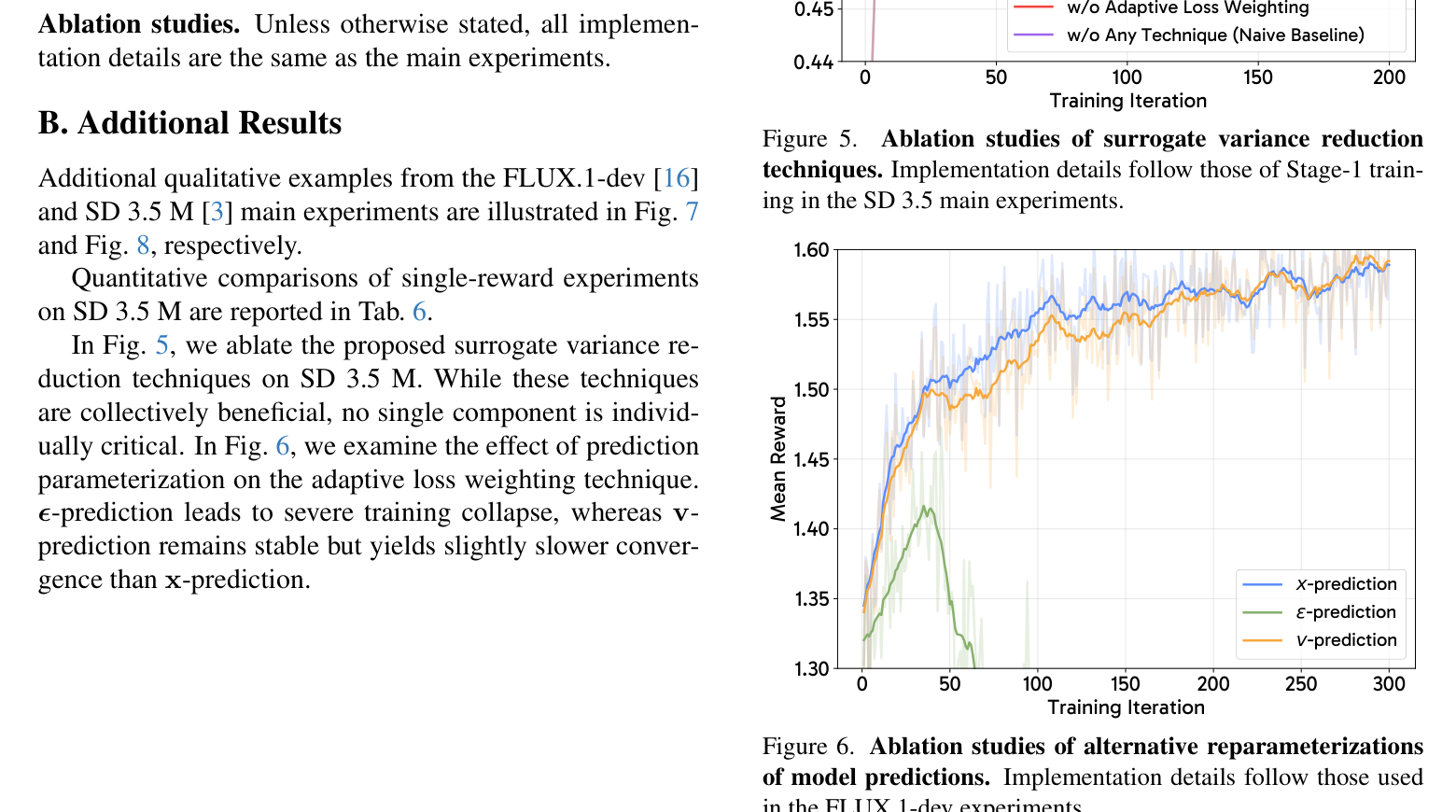
方差缩减技术的消融(Fig. 4a): 在 FLUX.1-dev 上,去掉任何一个方差缩减技术都会导致训练不稳定或性能下降。Naive baseline(不用任何技术)直接训练崩溃。
\(N_\text{MC}\) 的敏感性(Fig. 4f): \(N_\text{MC} = 2\) 时收敛困难,\(N_\text{MC} = 4\) 是性能与效率的最佳平衡点,\(N_\text{MC} = 8\) 仅有边际提升。这与 MDP 路线中"优化步数"的饱和效应一致。
预测参数化(Fig. 6): \(\epsilon\)-prediction 导致训练崩溃,\(v\)-prediction 稳定但收敛稍慢,\(x\)-prediction 表现最优。
V-GRPO 的代码实现解析
V-GRPO 的代码实现基于 FastVideo
框架。以下是核心函数 calc_surrogate 的完整解析,它计算 ELBO
代理值:
def calc_surrogate(args, transformer, ..., latents, noise, sigmas):
"""
计算 ELBO 代理值。
参数:
latents: 最终输出 o_i 的 latent 表示 (B, seq, hidden)
noise: 采样的噪声 ε_j (B, seq, hidden)
sigmas: 采样的时间步 t_j (B,)
返回:
surrogate: 代理值 (B,),越大表示 likelihood 越高
"""
# 构造加噪 latent: z_t = (1-t)·o_i + t·ε
while sigmas.ndim < latents.ndim:
sigmas = sigmas.unsqueeze(-1)
noisy_latents = (1.0 - sigmas) * latents + sigmas * noise
# 模型前向传播(预测速度场 v_θ)
model_pred = transformer(hidden_states=noisy_latents, ...)
# x-prediction 重参数化: x̂_0 = z_t - t·v_θ
x0_pred = noisy_latents - sigmas * model_pred
# L2 损失(取负号,因为 ELBO 是 likelihood 的下界)
surrogate = -torch.mean(
((x0_pred.float() - latents.float()) ** 2)
.reshape(noise.shape[0], -1),
dim=1,
)
# 自归一化(stop-gradient)
if args.self_normalize:
surrogate = surrogate / torch.mean(
torch.abs(
(x0_pred.detach().float() - latents.float())
.reshape(noise.shape[0], -1)
),
dim=1,
)
return surrogate # (B,)训练主循环中的 importance ratio 计算:
# 用当前策略 θ 计算新的代理值
pred, new_surrogates = calc_surrogate(
args, transformer, ...,
sample["latents"].repeat_interleave(N_MC, dim=0),
sample["noise"].flatten(0, 1),
sample["sigmas"].flatten(0, 1),
)
new_surrogates = new_surrogates.view(*sample["log_probs"].shape)
# 已存储的 θ_old 代理值
old_surrogates = sample["log_probs"]
# importance ratio(对 N_MC 个时间步取平均后再 exp)
ratio = torch.exp(new_surrogates.mean(dim=1) - old_surrogates.mean(dim=1))
# PPO 裁剪
unclipped_loss = -advantages * ratio
clipped_loss = -advantages * torch.clamp(ratio, 1-ε, 1+ε)
policy_loss = torch.mean(torch.maximum(unclipped_loss, clipped_loss))技术演进总结:从 MDP 到 ELBO
回顾整个系列的技术脉络,V-GRPO 代表了扩散模型在线 RL 的一次范式转换:
| 维度 | MDP 路线 | ELBO 路线 (V-GRPO) |
|---|---|---|
| 代表方法 | Flow-GRPO → DanceGRPO → MixGRPO → BranchGRPO | V-GRPO |
| \(\log\pi_\theta\) 获取 | SDE 转移核逐步累加 | 预训练损失(ELBO 代理) |
| 采样器 | 限于一阶 SDE | 任意(ODE/高阶求解器) |
| 优化-采样耦合 | 紧密耦合 | 完全解耦 |
| 实现复杂度 | 高(Score、SDE、窗口调度) | 低(仅需预训练损失) |
| FLUX.1-dev 收敛 | 300 iter (MixGRPO) | 150 iter |
| SD 3.5 M 梯度步 | 1700 (DiffusionNFT) | 580 |
| 与预训练的一致性 | 不一致(改用 SDE) | 完全一致 |
V-GRPO 的结果有力地证明:ELBO 路线不是二等公民。之前的失败不是方法本身的缺陷,而是没有做好方差控制。当 ELBO 代理的方差被正确缩减后,它在简洁性、效率和性能上全面超越复杂的 MDP 方法,有望成为去噪生成模型后训练的新默认方案。
参考资料:
- Tang, B., Zhang, Y., Wang, X., Mao, J., Schmidt, L., & Yeung-Levy, S. (2026). V-GRPO: Online Reinforcement Learning for Denoising Generative Models Is Easier than You Think. arXiv:2604.23380.
- Liu, J., et al. (2025). Flow-GRPO: Training Flow Matching Models via Online RL. arXiv:2505.05470.
- Li, J., et al. (2025). MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE. arXiv:2507.21802.
- Zheng, K., et al. (2025). DiffusionNFT: Online Diffusion Reinforcement with Forward Process. arXiv:2509.16117.