笔记|世界模型(三):JEPA——在嵌入空间预测世界
核心论文:I-JEPA (arXiv:2301.08243, CVPR 2023)、V-JEPA (arXiv:2404.08471, 2024)、V-JEPA 2 (arXiv:2506.09985, 2025)
代码:facebookresearch/ijepa · facebookresearch/jepa | 前置知识:上一篇:Dreamer 系列
0. 预测每片树叶的飘动是愚蠢的
上一篇介绍了 Dreamer 系列:在潜空间想象未来,用解码器重建像素来训练世界模型。DreamerV3 甚至在 Minecraft 中从零采到了钻石。但 Yann LeCun 提出了一个尖锐的质疑:为什么世界模型一定要能"画出"未来?
观察窗外的一棵树。树叶在风中随机飘动——每片叶子的具体轨迹本质上不可预测。但你能预测"树叶还会继续飘动"、"风变大了树会摇得更厉害"。你的大脑从不尝试重建每一片叶子的像素级位置,却对未来有清晰的"理解"。
Dreamer 的解码器被迫建模这些不可预测的细节——因为重建损失对每个像素一视同仁。这意味着模型容量的一大部分被浪费在树叶纹理、光影变化等对决策无关的随机性上。
JEPA(Joint-Embedding Predictive Architecture,联合嵌入预测架构)走了一条完全不同的路:丢弃不可预测的细节,只在嵌入空间中预测。 不需要解码器,不需要重建像素——一个好的预测只需要在语义层面捕捉未来。
1. LeCun 的认知架构提案
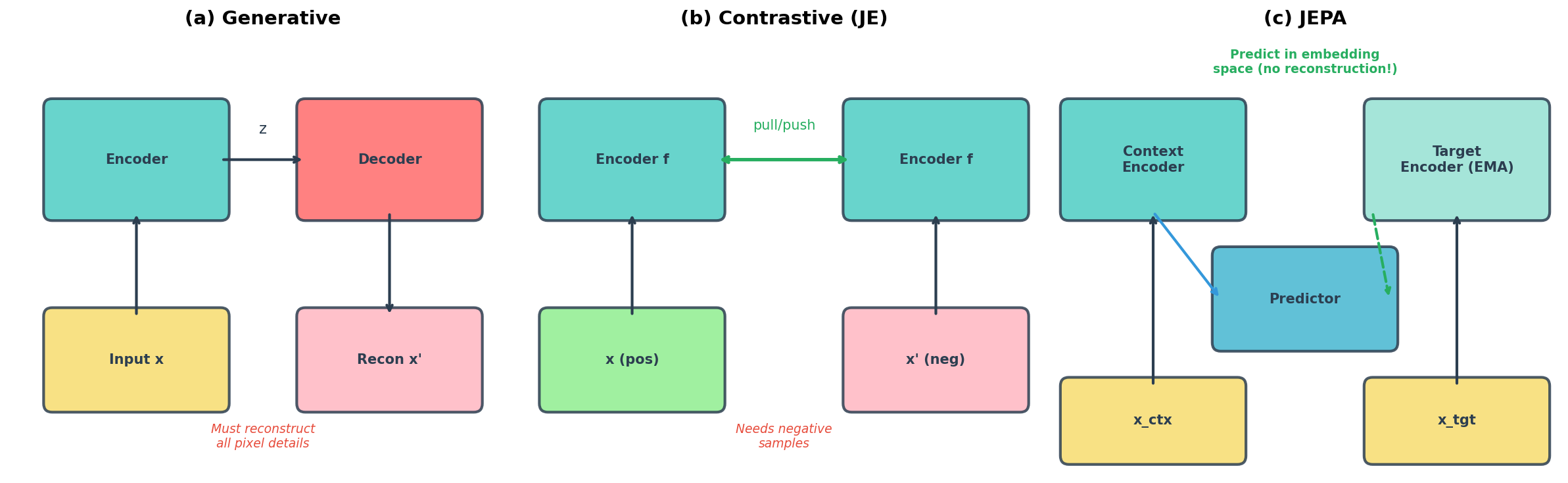
1.1 三种学习架构
2022 年,Yann LeCun 在白皮书 "A Path Towards Autonomous Machine Intelligence" 中系统对比了三种自监督学习架构。为了理解 JEPA 的设计动机,我们需要先搞清楚另外两种方案各自的"致命缺陷"。
| 架构 | 预测对象 | 核心缺陷 |
|---|---|---|
| 生成式(Generative) | 重建原始输入 \(\hat{x} \approx x\) | 被迫建模不可预测的细节(像素噪声、纹理) |
| 对比式(Contrastive/JE) | 拉近正样本嵌入、推远负样本 | 依赖负样本构造,训练不稳定,可能丢失信息 |
| JEPA(联合嵌入预测) | 在嵌入空间预测目标表征 | 无需重建、无需负样本,但需要防止崩塌 |
为什么 LeCun 要从 JE(对比学习)出发讨论这个问题? 2022 年的学术背景是:JE 方法(SimCLR、MoCo、BYOL、DINO、CLIP)已经成为自监督学习的统治范式,在分类、检索、零样本迁移上全面超越监督学习。JE 已经证明了两件关键的事:
- 嵌入空间是正确方向——不需要在像素空间操作,在嵌入空间学表征更高效
- 不需要标签——自监督就能学到强大的特征
但 LeCun 指出了 JE 的根本局限:它只学会了"静态的同一性判断",没有任何"如果...那么..."的预测能力。 JE 能判断"这两张照片是不是同一个人",但无法回答"如果我推他一下,他会怎么反应"。
这引出了从 JE 到世界模型的推理链:
\[ \text{JE(对比学习)} \xrightarrow{\text{加入预测器 } g_\phi} \text{JEPA} \xrightarrow{\text{加入动作条件 } a_t} \text{世界模型} \]
| JE(对比式) | JEPA | 世界模型 | |
|---|---|---|---|
| 核心操作 | 判断两个输入"是否相似" | 从一个嵌入预测另一个嵌入 | 给定状态+动作,预测未来状态 |
| 时间建模 | ✗ 无(静态表征) | ✓ 有(预测目标可以是未来帧) | ✓ 有(\(s_{t+1} = f(s_t, a_t)\)) |
| 本质 | 学"什么是什么"(同一性) | 学"什么会变成什么"(动态) | 学"做了什么会发生什么"(因果) |
JEPA 的命名本身就揭示了这个设计——Joint-Embedding Predictive Architecture = JE + P。LeCun 的论证策略是"先肯定再超越":肯定 JE 在嵌入空间和丢弃无用细节上做对了,然后指出它缺少预测能力,最后说明 JEPA 如何用最小的改动(加一个 predictor \(g_\phi\))弥补这个缺陷。
回到三种架构各自的问题:
生成式(如 MAE、Dreamer 的解码器、Sora):损失函数对每个像素都"一视同仁"。模型被迫为树叶的随机飘动分配概率,这些计算对理解"树在摇"毫无帮助。
对比式 / JE(如 SimCLR、CLIP):需要精心设计"什么是正样本、什么是负样本"。这引入了大量工程选择(数据增强策略、负样本队列大小等),且对比损失只关心"样本对的相对距离",可能丢弃绝对位置、时间顺序等有用信息。更根本的是:JE 没有预测器,只做匹配,不做预测——它永远无法回答"接下来会发生什么"。
JEPA 取两者之长:像生成式一样做预测(不需要负样本),但预测发生在嵌入空间而非像素空间(不需要建模噪声)。同时,它继承了 JE 在嵌入空间操作的优势,只增加了一个预测器来赋予模型"预测未来"的能力。
1.2 JEPA 的形式化定义
JEPA 的核心思路可以用一句话概括:把输入映射到嵌入空间,然后在嵌入空间里做预测。
给定上下文输入 \(x^{\text{ctx}}\)(你能看到的部分)和目标输入 \(x^{\text{tgt}}\)(你需要预测的部分——被遮挡的图像块、未来的视频帧等):
\[ \begin{aligned} s_x &= f_\theta(x^{\text{ctx}}) \quad &\text{(上下文编码器:把看到的东西变成嵌入)} \\ s_y &= f_{\bar{\theta}}(x^{\text{tgt}}) \quad &\text{(目标编码器:把要预测的东西变成嵌入)} \\ \hat{s}_y &= g_\phi(s_x) \quad &\text{(预测器:从看到的嵌入推测目标嵌入)} \end{aligned} \]
训练目标极其简洁——让预测嵌入 \(\hat{s}_y\) 逼近目标嵌入 \(s_y\):
\[ \mathcal{L}_{\text{JEPA}} = \|\hat{s}_y - \text{sg}(s_y)\|_2^2 \]
其中 \(\text{sg}(\cdot)\) 是 stop-gradient(梯度不回传到目标编码器)。目标编码器 \(f_{\bar{\theta}}\) 通过 EMA(指数移动平均) 缓慢跟踪上下文编码器的权重:
\[ \bar{\theta} \leftarrow \tau \bar{\theta} + (1 - \tau) \theta, \quad \tau \in [0.996, 1) \]
什么是 EMA? 用一个类比:假设你在追踪股票价格,每天有一个新价格 \(p_t\)。直接看每日价格波动剧烈,你想要一条"平滑的趋势线" \(\bar{p}_t\):
\[ \bar{p}_t = \tau \cdot \bar{p}_{t-1} + (1 - \tau) \cdot p_t \]
\(\tau\) 越接近 1,趋势线越平滑、对新数据反应越迟钝。在 JEPA 中取 \(\tau = 0.996\) 意味着目标编码器每步只接受 \(0.4\%\) 的新权重——变化极其缓慢,相当于上下文编码器"过去几百步权重的平均版本"。
为什么需要两个编码器和 EMA? 如果上下文编码器和目标编码器共享参数且同时更新,模型会找到一个"捷径"——让所有输入都映射到同一个常数向量,损失自动为零,但什么也没学到。这就是表征崩塌。EMA 目标编码器的缓慢移动创造了一种"异步":上下文编码器快速学习,目标编码器缓慢跟随——快的追慢的,始终有差距,始终有非平凡的预测目标。
1.3 为什么不在像素空间预测?
用一个具体例子理解这个问题。假设你在看一段视频:一个人在走路,背景有树叶飘动、路面有水洼反光。
- 像素重建模型(MAE、Dreamer 解码器)必须预测:"下一帧这片树叶在哪?水洼反光的形状是什么?"——这些细节本质上是随机的,对理解"人在走路"毫无帮助。
- JEPA 只需要在嵌入空间预测:"这个人的姿态将如何变化?"——编码器可以自由选择丢弃树叶和反光的细节。
从信息论角度,输入 \(x\) 的信息可以分解为:
\[ H(x) = \underbrace{H_{\text{semantic}}}_{\text{可预测的语义(人的姿态)}} + \underbrace{H_{\text{stochastic}}}_{\text{不可预测的噪声(树叶飘动)}} \]
像素重建被迫建模全部 \(H(x)\),包括 \(H_{\text{stochastic}}\)。JEPA 的编码器 \(f_\theta\) 则可以学会丢弃 \(H_{\text{stochastic}}\),只在嵌入空间保留 \(H_{\text{semantic}}\)。
命题(JEPA 的信息选择性):设 \(s = f_\theta(x)\) 为 JEPA 编码器的输出,\(y\) 为预测目标。在理想情况下,JEPA 的最优编码器满足:
\[I(s; y) \to \max, \quad I(s; x \mid y) \to 0\]
这两个条件的含义:
- \(I(s; y) \to \max\):互信息 \(I(s; y)\) 衡量"知道 \(s\) 后,对预测 \(y\) 有多大帮助"。最大化它要求 \(s\) 保留所有对预测目标有用的信息。例如:\(x\) 是走路视频帧,\(y\) 是下一帧——\(s\) 必须编码步频、方向、重心等与预测相关的语义信息。
- \(I(s; x \mid y) \to 0\):条件互信息 \(I(s; x \mid y)\) 衡量"已经知道 \(y\) 后,\(s\) 还额外携带了多少原始输入 \(x\) 的信息"。让它为零要求 \(s\) 不包含与预测无关的信息。例如:\(x\) 中有树叶飘动、水面反光——即使知道了 \(y\),如果 \(s\) 还编码了树叶位置,那就是"多余的"。
两个条件合在一起定义了最小充分统计量(Minimal Sufficient Statistics):保留所有有用信息,丢弃所有无用信息。这正是 Information Bottleneck(Tishby et al., 2000)的核心思想:在"信息保留"和"噪声过滤"之间找到最优平衡。
1.4 防止崩塌:从工程技巧到理论保证
JEPA 面临的最大风险是表征崩塌(Representation Collapse)——如果上下文编码器和目标编码器都学会输出同一个常数向量,MSE 损失自动为零,但模型什么也没学到。
工程层面的防崩塌机制(I-JEPA、V-JEPA 采用):
- EMA 目标编码器:目标侧参数缓慢更新(\(\tau \approx 0.996\)),防止两个编码器同步退化为常数映射。
- 大块掩码策略:遮挡的区域足够大且语义丰富,使预测任务非平凡——模型无法通过简单的空间插值完成任务。
这些技巧在实践中效果良好,但缺乏严谨的理论解释:"为什么 EMA 能防止崩塌?\(\tau\) 取多少才够?"
2026 年的理论进展:变分推断视角
最新的理论研究将 JEPA 重新表述为变分推断(Variational Inference)框架下的概率模型:
- Var-JEPA(Gögl & Yau, 2026, arXiv:2603.20111)证明了标准 JEPA 实际上是变分推断在方差趋于零时的确定性特例。通过显式地优化 ELBO,Var-JEPA 能够在不使用 EMA 的情况下从原理上避免表征崩塌。
- VJEPA(Huang et al., 2026, arXiv:2601.14354)进一步证明了 JEPA 学到的表征可以是最优控制的充分信息状态(Sufficient Information States)——即它包含了做出最优决策所需的全部信息,同时自动过滤掉高方差的随机噪声。
这个结果具有深远的意义:预测派(JEPA)和生成派(Dreamer 的 ELBO)在底层数学结构上正在走向统一。 JEPA 不是 ELBO 的"替代品",而是 ELBO 在特定条件下的另一种实现方式。
2. I-JEPA:在图像上的第一次实践
2.1 核心思路
I-JEPA(Assran et al., CVPR 2023)是 JEPA 思想在图像领域的首次大规模实现。它的任务非常直观:遮挡图像的一部分,从可见部分预测被遮挡部分的嵌入表征——注意,不是预测像素,而是预测语义特征。
具体流程:
- 分块:图像被切成 \(N\) 个 patch(ViT 的标准做法,如 14×14 = 196 个 patch)
- 掩码:选定若干大块连续区域作为目标(被遮挡),剩余部分作为上下文(可见)
- 编码:上下文编码器处理可见 patch → 得到上下文嵌入;目标编码器(EMA)处理目标 patch → 得到目标嵌入
- 预测:预测器(一个轻量 ViT)从上下文嵌入 + 目标位置编码 → 预测目标嵌入
- 损失:预测嵌入与目标嵌入的 L2 距离
2.2 掩码策略:为什么大块比随机好?
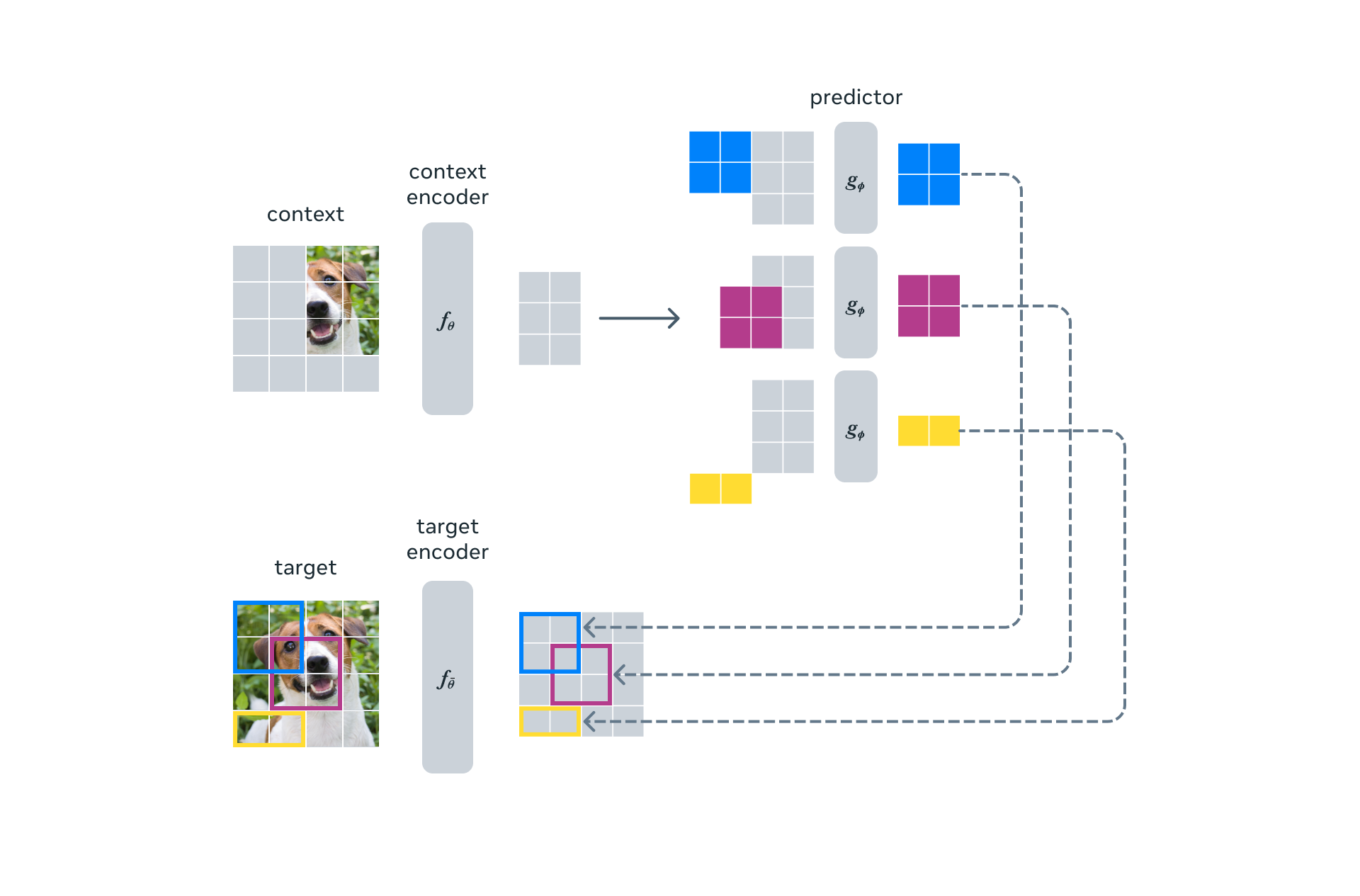
I-JEPA 的掩码策略是其成功的关键设计,与 MAE 的随机掩码形成鲜明对比。论文中的具体参数:
- 4 个目标块(\(M=4\)),每个面积占图像的 15%–20%,长宽比在 (0.75, 1.5) 内随机采样
- 1 个上下文块,面积占 85%–100%,并移除与目标重叠的区域
为什么这样设计?关键在于让模型学习语义而非纹理:
- MAE 遮挡 75% 的随机散布 patch。由于每个被遮挡的 patch 周围大概率有相邻的可见 patch,模型可以通过局部纹理插值来重建——不需要理解语义,靠纹理接龙就够了。
- I-JEPA 遮挡的是大块连续区域(可能覆盖一只狗的整个头部)。模型无法靠周围像素"接龙"——它必须理解"这是一只狗,狗头应该长什么样"才能预测该区域的嵌入。
此外,I-JEPA 的预测目标是嵌入而非像素,这进一步避免了对纹理细节的过度关注。
2.3 与 MAE 的定量对比
| 维度 | MAE | I-JEPA |
|---|---|---|
| 预测目标 | 像素重建 | 嵌入预测 |
| 解码器 | 需要(像素解码器) | 不需要 |
| 掩码策略 | 75% 随机散布 patch | 15-20% 大块连续区域 |
| 数据增强 | 必需(裁剪、翻转等) | 不需要 |
| ImageNet 线性评估 | 77.2% (ViT-H/14, 1600 epochs) | 79.3% (ViT-H/14, 300 epochs) |
| 训练效率 | 显著更慢(需要像素解码器) | 快 >10× |
I-JEPA 用不到 MAE 五分之一的预训练 epoch,在 ImageNet 线性评估上取得了更高的准确率——而且不需要任何数据增强。这验证了 LeCun 的核心论点:在嵌入空间预测比在像素空间重建更高效。
2.4 代码核心
# ---- 初始化 ----
ctx_enc = ViT() # 上下文编码器,只看可见 patch
tgt_enc = deepcopy(ctx_enc) # 目标编码器,EMA 更新,看完整图像
predictor = MLP() # 预测器:从可见 token 预测被遮挡 token
# ---- 前向传播 ----
ctx_tok = ctx_enc(img, mask=visible) # 只编码可见 patch → 上下文 token
tgt_tok = tgt_enc(img) # 编码完整图像 → 目标 token(不算梯度)
pred = predictor(ctx_tok, masked_pos) # 用上下文 token 预测被遮挡位置的嵌入
loss = MSE(pred, tgt_tok[masked_pos]) # 在嵌入空间算 MSE,而非像素空间
# ---- EMA 更新 ----
tgt_enc = τ * tgt_enc + (1-τ) * ctx_enc # τ≈0.996,目标编码器缓慢跟踪上下文编码器3. V-JEPA:从图像到视频
3.1 为什么视频比图像更需要 JEPA?
I-JEPA 在图像上验证了嵌入预测的有效性。但 JEPA 的真正优势在视频领域更加明显——因为视频中不可预测的随机性远多于图像。
想象预测一段行走视频的下一帧:行人的姿态变化是可预测的(语义),但他外套的褶皱、地面的反光、远处树叶的飘动都是随机的。像素级视频预测模型(如 Sora)必须为所有这些细节分配计算资源;V-JEPA 则可以在嵌入空间中只保留"姿态变化"的信息。
3.2 时空掩码:遮挡什么、保留什么
V-JEPA(Bardes et al., 2024, arXiv:2404.08471)将 I-JEPA 的掩码思路从 2D 图像扩展到 3D 视频。输入视频被切成 \((t, h, w)\) 的 3D patch(时间 × 高度 × 宽度),然后在时空维度上同时做掩码。
V-JEPA 使用多种掩码策略的组合:
- 短程掩码(空间为主):在同一帧或相邻帧内遮挡空间区域——类似 I-JEPA 的大块遮挡,测试模型的空间理解能力
- 长程掩码(时间为主):遮挡未来若干帧的整个帧或大面积区域——测试模型的时间动力学预测能力
数学上与 I-JEPA 完全一致,只是从 2D patch 变成了 3D patch。设视频被分为 \(N\) 个时空 patch,上下文集合 \(\mathcal{C}\),目标集合 \(\mathcal{T}\):
\[ \begin{aligned} \mathbf{s}_{\mathcal{C}} &= f_\theta(\{x_i\}_{i \in \mathcal{C}}) \in \mathbb{R}^{|\mathcal{C}| \times d} \\ \mathbf{s}_{\mathcal{T}} &= f_{\bar{\theta}}(\{x_j\}_{j \in \mathcal{T}}) \in \mathbb{R}^{|\mathcal{T}| \times d} \\ \hat{\mathbf{s}}_{\mathcal{T}} &= g_\phi(\mathbf{s}_{\mathcal{C}}, \text{pos}_{\mathcal{T}}) \in \mathbb{R}^{|\mathcal{T}| \times d} \end{aligned} \]
预测器 \(g_\phi\) 接收上下文嵌入和目标位置编码(告诉它要预测"哪个时刻的哪个位置"),输出目标位置的嵌入预测。损失函数不变:
\[ \mathcal{L} = \frac{1}{|\mathcal{T}|} \sum_{j \in \mathcal{T}} \|\hat{s}_j - \text{sg}(s_j)\|_2^2 \]
3.3 关键设计:纯特征预测 + 冻结评估
V-JEPA 有两个值得强调的设计哲学:
纯特征预测:整个训练过程不使用任何像素重建、对比学习、负样本、预训练图像编码器或文本标注。这使它成为"最纯粹"的 JEPA 实现——训练信号完全来自嵌入空间的 MSE。
冻结评估(Frozen Evaluation):下游任务(动作识别、图像分类等)只在冻结的 backbone 上训练一个轻量探针(attentive probe),不微调 backbone。这是对表征质量最严格的测试——如果冻结评估就能取得高精度,说明预训练得到的表征真正具有通用性。
V-JEPA(ViT-H/16)在冻结评估下的结果:Kinetics-400 达 81.9%,Something-Something-v2 达 72.2%,ImageNet-1K 达 77.9%。
3.4 V-JEPA vs 视频生成模型
| 维度 | V-JEPA | 视频生成模型(Sora 等) |
|---|---|---|
| 预测对象 | 嵌入向量 | 像素/视频帧 |
| 解码器 | 无 | 需要(扩散/自回归) |
| 训练信号 | 嵌入 MSE | 扩散 ELBO / NLL |
| 输出 | 不可视化的表征 | 可视化的视频 |
| 对随机细节的处理 | 可以丢弃 | 必须建模 |
| 适用场景 | 表征学习、理解、规划 | 视频生成、仿真 |
4. V-JEPA 2:JEPA 终于成为世界模型
4.1 从"表征学习"到"行动决策"
V-JEPA 在视频理解上表现出色,但它有一个根本性的缺失:没有动作。V-JEPA 只能"看视频并理解内容",不能回答"如果我执行动作 \(a\),世界会怎么变?"——而这恰恰是世界模型最核心的能力。
V-JEPA 2(Meta AI, 2025, arXiv:2506.09985)补上了这块关键拼图:它在 V-JEPA 的基础上增加了动作条件预测,使 JEPA 架构第一次具备了规划(Planning) 能力。
4.2 两阶段训练
V-JEPA 2 采用两阶段训练范式:
阶段一:大规模视频预训练。在超过 100 万小时的互联网视频上,用标准的 V-JEPA 目标(时空掩码 + 嵌入预测)训练一个 1.2B 参数的 ViT 编码器。这个阶段让模型学会了"世界长什么样、物体怎么运动"的通用物理直觉。
阶段二:动作条件后训练(V-JEPA 2-AC)。在冻结的 V-JEPA 2 编码器之上,训练一个 300M 参数的 Transformer 网络,使其能够根据动作预测未来嵌入。这个阶段仅需不到 62 小时的无标注机器人交互数据(来自 Droid 数据集)。
数学上:
\[ \begin{aligned} \text{编码:} \quad & s_t = f_\theta(o_t) \quad \text{(冻结的 V-JEPA 2 编码器)} \\ \text{动作条件预测:} \quad & \hat{s}_{t+1} = g_\phi(s_t, a_t) \quad \text{(后训练的 Transformer)} \\ \text{规划:} \quad & a^* = \arg\min_a \|\hat{s}_{t+1} - s_{\text{goal}}\|_1 \end{aligned} \]
4.3 嵌入空间中的规划:MPC + CEM
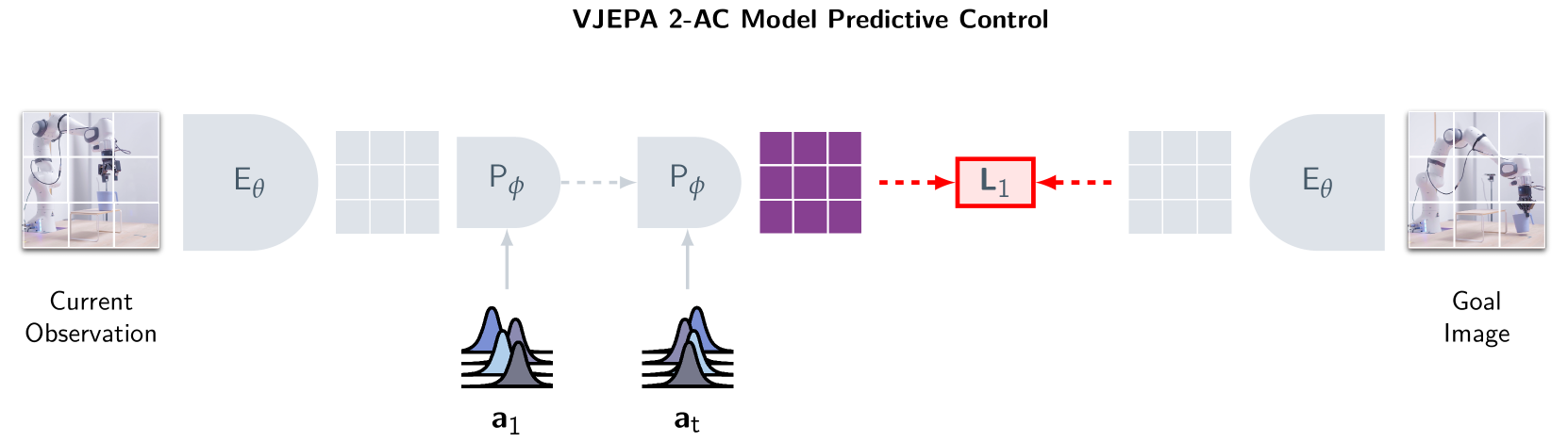
有了动作条件预测能力后,V-JEPA 2-AC 使用 模型预测控制(MPC) 配合 交叉熵方法(CEM) 来做规划。用一个具体例子来理解:假设机器人面前有一个杯子,你拍了一张"杯子放到桌子右侧"的目标照片,让机器人执行这个任务。
第一步:定义"什么算成功"
把目标照片通过编码器变成嵌入向量 \(s_{\text{goal}} = f_\theta(o_{\text{goal}})\)。现在"成功"有了数学定义:让当前状态的嵌入尽可能接近 \(s_{\text{goal}}\)。不需要人工写奖励函数——两个嵌入的距离就是奖励。
第二步:在脑中"试"很多种动作序列(CEM,Cross-Entropy Method,交叉熵方法)
机器人不可能真的尝试每种动作。CEM 的做法是在想象中反复筛选:
- 随机猜:从高斯分布中采样 \(N=512\) 条候选动作序列,比如"先右移 3cm 再下压 2cm 再夹紧"、"先前推 5cm 再左移 1cm"……
- 在脑中模拟:对每条动作序列,用世界模型 \(g_\phi\) 在嵌入空间中逐步推演未来状态:\(\hat{s}_1 = g_\phi(s_0, a_0)\),\(\hat{s}_2 = g_\phi(\hat{s}_1, a_1)\),……最终得到每条序列的"预测结局"
- 留下最好的:算每条序列的结局嵌入与 \(s_{\text{goal}}\) 的距离,保留距离最小的 top-\(K\) 条
- 基于精英重新采样:用这 \(K\) 条精英序列的均值和方差作为新的采样分布,回到第 1 步
- 重复 3–5 轮:分布越来越集中在"好动作"附近,最终收敛到一条高质量的动作序列
\[ \mu_{t+1}, \sigma_{t+1} = \text{fit}(\text{top-}K \text{ 精英序列}) \quad \text{(用精英的统计量更新采样分布)} \]
第三步:只执行第一个动作,然后重新规划(MPC)
找到最优序列后,只执行第一个动作 \(a_0^*\),然后观察真实世界的变化,重新从第一步开始规划。为什么不一口气执行完?因为真实世界和模型预测总有偏差——每执行一步就"睁眼看一下",比蒙着眼执行一整套动作要靠谱得多。这就是 MPC 的核心思想:滚动规划,走一步看一步。
整个过程完全在嵌入空间中进行,不需要渲染任何像素。相比之下,基于视频生成的规划方法(如 Cosmos)需要先生成视频帧再评估——V-JEPA 2-AC 的规划速度是 Cosmos 的约 15 倍(16 秒 vs 4 分钟)。
零样本机器人操作:V-JEPA 2-AC 实现了在新环境、新物体上的零样本抓取和放置——不需要环境特定的数据收集或任务特定的奖励函数。只需一张目标照片,机器人就能自己规划出动作序列。
4.4 与 Dreamer 的深度对比
| 维度 | Dreamer | V-JEPA 2-AC |
|---|---|---|
| 预测空间 | 潜变量 \(h_t, z_t\) + 解码器重建 | 纯嵌入空间 \(s_t\)(无解码器) |
| 训练信号 | ELBO(重建 + KL) | 嵌入 MSE |
| 策略学习 | Actor-Critic(在想象中训练) | MPC + CEM(在线规划) |
| 奖励 | 显式预测奖励头 | 隐式(目标嵌入距离) |
| 预训练数据 | 无(只用环境交互数据) | 100 万小时互联网视频 |
| 泛化能力 | 同一域内泛化 | 跨域零样本(新物体、新环境) |
核心差异在于:Dreamer 从零开始在单一环境中学习一切(世界模型 + 策略),而 V-JEPA 2 先从海量视频中学习通用的物理世界表征,然后只需少量机器人数据就能适配到具体任务。这种"预训练 → 后训练"的范式正是 LLM 成功的关键——V-JEPA 2 将其引入了世界模型。
4.5 V-JEPA 2.1:让每个 token 都精确(2026)
V-JEPA 2 的一个局限是:其表征更擅长全局语义理解("这是一只杯子"),但在精细空间定位("杯子的把手在哪里")上不够准确。这对需要精确抓取的机器人操作是致命的。
V-JEPA 2.1(2026, arXiv:2603.14482)通过三个创新解决了这个问题:
创新一:稠密预测损失——让每个 token 都"知道自己在哪"
V-JEPA 2 的问题根源:只有被遮挡的 token 参与损失计算,可见的 token 仅作为预测器的"输入"。这意味着可见 token 没有任何压力去编码"我在图像的哪个位置"——它可以把自己变成一个全局摘要向量,丢失精确的空间信息。
V-JEPA 2.1 的解决方案:对所有 token(包括可见的)都施加预测损失。具体做法:
- 被遮挡 token:标准 L1 损失(和之前一样)
- 可见 token:加一个距离加权的 L1 损失。对于可见 token \(i\),权重为:
\[ \lambda_i = \frac{1}{\sqrt{d_i}} \]
其中 \(d_i\) 是该 token 到最近被遮挡 token 的时空距离(以 patch 为单位)。
为什么要按距离加权?直觉很简单:靠近遮挡边界的 token 必须编码精确的局部信息(因为旁边就是需要预测的位置),远处的 token 可以更"全局"一些。\(1/\sqrt{d}\) 的衰减创造了从精细到粗糙的平滑过渡。
这个损失如何让 token 对应到时空位置?目标编码器独立处理完整输入,其位置 \((t, h, w)\) 的输出自然编码了该位置的内容。现在上下文编码器的每个输出都必须匹配目标编码器在同一位置的输出——这就迫使每个 token 忠实地表征"自己所在位置的内容",而非退化为全局摘要。
创新二:深层自监督
标准 JEPA 只在 Transformer 最后一层施加损失。但空间细节(边缘、纹理位置)往往在浅层就已经存在,只是因为深层没有被约束去保留它们,这些信息在逐层传递中被丢弃了。V-JEPA 2.1 在多个中间层都施加预测目标——相当于在每一层都提醒模型"别忘了空间细节"。
创新三:多模态 tokenizer
对图像使用 2D patch embedding,对视频使用 3D patch embedding,替代统一的扁平化格式——让每种模态都能用最自然的方式被切分。
结果:V-JEPA 2.1(ViT-G, 2B 参数)在机器人抓取任务上比 V-JEPA 2 提升了 20%。
5. JEPA vs 生成式世界模型:一个根本性的设计选择
5.1 损失函数决定了模型"关注什么"
生成式和 JEPA 的根本差异不在架构,而在损失函数对信息的处理方式。
生成式模型(Dreamer 解码器, Sora)优化的是负对数似然:
\[ \mathcal{L}_{\text{gen}} = -\mathbb{E}_{p_{\text{data}}}[\log p_\theta(x)] \]
这要求模型对输入 \(x\) 的每一个细节都分配合理的概率密度。一棵树有 10 万片叶子,每片叶子在风中的位置都算在损失里——模型无法选择"忽略叶子的细节"。
JEPA 优化的是嵌入空间的 MSE:
\[ \mathcal{L}_{\text{JEPA}} = \mathbb{E}[\|g_\phi(f_\theta(x^{\text{ctx}})) - \text{sg}(f_{\bar{\theta}}(x^{\text{tgt}}))\|^2] \]
关键区别:编码器 \(f_\theta\) 可以自由选择丢弃哪些信息——只要目标编码器也丢弃了同样的信息,MSE 就不会增大。如果"叶子的具体位置"被两个编码器同时丢弃了,这个信息对损失没有任何贡献。
5.2 信息瓶颈:JEPA 编码器自动学会"丢弃噪声"
命题(JEPA 编码器的信息瓶颈性质):在 JEPA 框架下,最优编码器 \(f^*\) 是 \(x\) 关于预测目标 \(y\) 的最小充分统计量:
\[f^* = \arg\min_{f: I(f(x); y) = I(x; y)} H(f(x))\]
即在保持对预测目标的全部信息的同时,最小化自身的熵(丢弃一切冗余信息)。
这与 Information Bottleneck(Tishby et al., 2000)的形式完全一致。直觉上:JEPA 编码器会自动找到输入中"对预测有用"的最小信息子集。树叶的随机位置对预测"人在走路"没有帮助,所以会被自动丢弃。
5.3 什么时候该用哪种?
| 任务 | 生成式更好 | JEPA 更好 | 原因 |
|---|---|---|---|
| 视频/图像生成 | ✓ | ✗ | JEPA 无法生成可视化输出 |
| 仿真数据合成 | ✓ | ✗ | 需要像素级输出 |
| 图像分类 | - | ✓ | 嵌入表征更紧凑 |
| 视频理解 | - | ✓ | 自动过滤无关视觉细节 |
| 机器人规划 | 可行但慢 | ✓(快 15×) | 不需要渲染像素 |
| 跨域泛化 | 困难 | ✓ | 大规模视频预训练 + 少量适配 |
6. 总结:理解未来,而非画出未来
| 模型 | 年份 | 模态 | 核心创新 | 关键能力 |
|---|---|---|---|---|
| I-JEPA | 2023 | 图像 | 大块掩码 + 嵌入预测 | 高效自监督表征学习 |
| V-JEPA | 2024 | 视频 | 时空掩码 + 纯特征预测 | 冻结评估下的视频理解 |
| V-JEPA 2 | 2025 | 视频+动作 | 动作条件后训练 + MPC 规划 | 零样本机器人操作 |
| V-JEPA 2.1 | 2026 | 图像+视频 | 稠密预测 + 深层自监督 | 精细空间定位 |
JEPA 系列的演进脉络清晰:从图像理解(I-JEPA)→ 视频理解(V-JEPA)→ 世界模型(V-JEPA 2)→ 精细定位(V-JEPA 2.1)。每一步都在保持核心优势(嵌入空间预测、无需像素重建)的同时,扩展能力边界。
JEPA 代表了一种优雅的世界模型哲学:不需要能"画出"未来,只需要能"理解"未来。 但它有一个明显的限制——无法生成可视化的预测。如果你的目标不是理解,而是生成逼真的虚拟世界呢?下一篇将介绍走向另一个极端的方案:视频生成即世界模拟——从 Sora 到 Genie 与 Cosmos。
参考资料:
- LeCun, Y. (2022). A Path Towards Autonomous Machine Intelligence. OpenReview.
- Assran, M., ... & Rabbat, M. (2023). Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture. CVPR 2023.
- Bardes, A., ... & Rabbat, M. (2024). Revisiting Feature Prediction for Learning Visual Representations from Video. arXiv:2404.08471.
- Tishby, N., Pereira, F., & Bialek, W. (2000). The Information Bottleneck Method. arXiv:physics/0004057.
- Gögl, S., & Yau, C. (2026). Var-JEPA: A Variational Formulation of the Joint-Embedding Predictive Architecture. arXiv:2603.20111.
- Huang, B., et al. (2026). Variational Joint-Embedding Predictive Architecture. arXiv:2601.14354.