笔记|世界模型(五):物理化的视频生成——让模型理解牛顿定律
核心论文:PhysDreamer (arXiv:2404.13026, ECCV 2024)、PhysGen (arXiv:2409.18964, ECCV 2024)、NewtonGen (arXiv:2509.21309, 2025)、NewtonRewards (arXiv:2512.00425, 2025)
代码:stevenlsw/physgen · pandayuanyu/NewtonGen | 前置知识:上一篇:视频生成世界模型
0. Sora 生成的球为什么不遵守牛顿定律?
上一篇我们看到,纯数据驱动的视频模型存在根本性的物理缺陷——"How Far" 论文(ICML 2025)证明它们做的是"基于案例的模仿"而非"物理规则的抽象"。
一个具体的例子:用 Sora 生成"球从桌子上滚下来"。你可能会看到球的轨迹大致合理,但仔细观察——球在桌边没有加速(无视重力),落地后弹跳角度不对,甚至可能穿过桌面。模型学到了"球通常往下掉"这种统计规律,但没有学到 \(F = ma\)。
那么,有没有办法让视频生成模型既保持视觉逼真度,又遵守物理定律?本篇介绍四种技术路线,按"物理嵌入的深度"排列——从显式仿真驱动,到潜空间物理约束,再到后训练物理奖励。
1. PhysDreamer:从视频先验蒸馏物理属性
1.1 核心思想
PhysDreamer(MIT 等,2024)将问题分为两步:
从视频模型中"蒸馏"出物理属性(如材质的弹性模量)
用显式物理仿真器驱动运动(Material Point Method)
这是"数据驱动的物理参数估计 + 基于物理的仿真"的混合方案。
1.2 方法
给定一个静态 3D 物体(用 3D Gaussian Splatting 表示),PhysDreamer 的流程:
Step 1:物理属性估计
对 3D 场景中的每个 Gaussian 预测一个材质参数向量 \(\mathbf{m}_i = (\mu_i, \lambda_i)\)(杨氏模量和泊松比):
\[ \mathbf{m}_i = \text{MLP}_\theta(\mathbf{x}_i, \mathbf{f}_i) \]
其中 \(\mathbf{x}_i\) 是空间位置,\(\mathbf{f}_i\) 是外观特征。
如何训练这个 MLP?用视频扩散模型的得分函数作为监督信号(Score Distillation):
\[ \nabla_\theta \mathcal{L}_{\text{SDS}} = \mathbb{E}_{t, \epsilon}\left[w(t) \cdot (\hat{\epsilon}_\phi(z_t, t, c) - \epsilon) \cdot \frac{\partial z}{\partial \theta}\right] \]
直觉:视频扩散模型"知道"物体在外力作用下应该如何运动(从训练视频中学到),PhysDreamer 利用这个知识来估计材质参数。
Step 2:物理仿真
用 Material Point Method (MPM) 进行可微物理仿真:
\[ \begin{aligned} \mathbf{v}^{n+1}_p &= \mathbf{v}^n_p + \Delta t \cdot \left(\mathbf{g} + \frac{1}{m_p} \mathbf{f}^n_p\right) \\ \mathbf{x}^{n+1}_p &= \mathbf{x}^n_p + \Delta t \cdot \mathbf{v}^{n+1}_p \end{aligned} \]
其中 \(\mathbf{g}\) 是重力加速度,\(\mathbf{f}^n_p\) 是弹性力(由材质参数决定),\(m_p\) 是质点质量。
弹性力通过变形梯度 \(\mathbf{F}\) 和应力张量 \(\boldsymbol{\sigma}\) 计算:
\[ \boldsymbol{\sigma} = \frac{1}{J}\frac{\partial \Psi}{\partial \mathbf{F}} \mathbf{F}^\top \]
其中 \(\Psi\) 是弹性势能密度(由杨氏模量 \(E\) 和泊松比 \(\nu\) 决定),\(J = \det(\mathbf{F})\)。
Step 3:渲染
将仿真后的粒子位置更新到 3D Gaussian,用可微渲染生成视频。
1.3 效果
PhysDreamer 能让静态 3D 物体在外力作用下产生物理合理的形变和运动。例如推一只布料做的兔子,它会像真正的布料一样变形和回弹。
局限:偏向慢速、平滑的运动(弹性形变),无法处理碰撞、断裂等复杂物理。
2. PhysGen:刚体物理 + 扩散视频
2.1 混合管线
PhysGen(UIUC, 2024)走了一条不同的路——先仿真后生成:
图像理解 → 物理参数提取 → 刚体仿真 →
视频扩散细化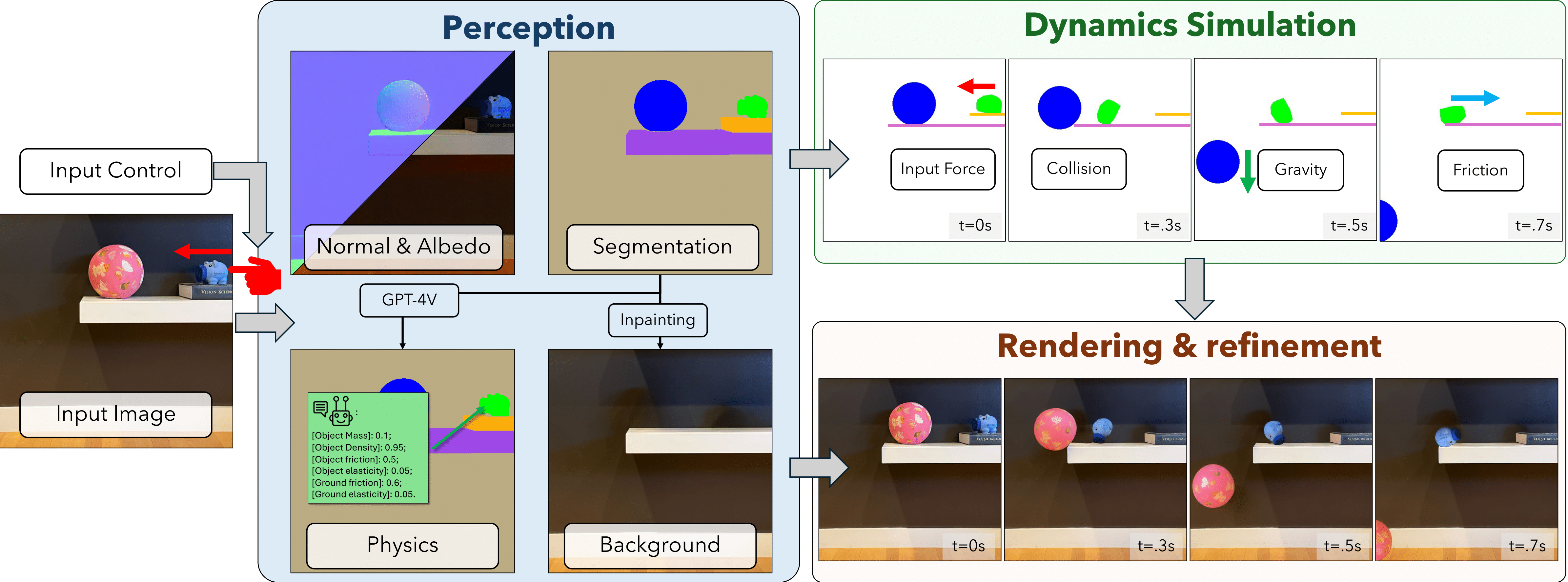
2.2 三阶段流程
阶段 1:场景理解
从单张图像中提取物理信息:
\[ \{\text{几何}, \text{材质}, \text{物理参数}\} = \text{SceneParser}(\mathbf{I}) \]
包括物体的 3D 形状、质量、摩擦系数等。
阶段 2:图像空间物理仿真
在 2D 图像空间中运行简化的刚体动力学:
\[ \begin{aligned} \mathbf{F} &= m\mathbf{a} \quad &\text{(牛顿第二定律)} \\ \boldsymbol{\tau} &= I\boldsymbol{\alpha} \quad &\text{(旋转动力学)} \\ \mathbf{v}' &= -e \cdot \mathbf{v}_n + \mu \cdot \mathbf{v}_t \quad &\text{(碰撞响应)} \end{aligned} \]
其中 \(e\) 是恢复系数,\(\mu\) 是摩擦系数。仿真输出是粗糙但物理正确的运动轨迹。
阶段 3:视频扩散细化
用视频扩散模型将粗糙的仿真结果(线条/简笔画级别)"美化"为逼真视频:
\[ V_{\text{realistic}} = \text{VideoDiffusion}(V_{\text{sim}}, \mathbf{I}_0, \text{prompt}) \]
2.3 数学:力条件控制
PhysGen 允许用户指定作用力来控制生成:
\[ \mathbf{F}_{\text{ext}} = (F_x, F_y), \quad \text{作用点} = (x_0, y_0) \]
物理仿真器根据这些力计算运动轨迹,再交给视频模型渲染。
3. NewtonGen:Neural Newtonian Dynamics
3.1 核心创新
NewtonGen(Pan et al., 2025, arXiv:2509.21309)提出了 Neural Newtonian Dynamics(NND):用物理信息 Neural ODE 预测物体的牛顿运动轨迹,再将预测轨迹转化为光流(optical flow)来引导视频生成器。
NND 在一个 9 维的物理状态向量上操作:
\[ Z = [x, y, v_x, v_y, \theta, \omega, s, l, a] \]
包括位置、速度、旋转角/角速度、物体尺寸等。状态更新遵循牛顿运动方程:
\[ Z_{t+1} = Z_t + \Delta t \cdot \dot{Z}_t + \frac{1}{2} (\Delta t)^2 \cdot \ddot{Z}_t \]
3.2 架构
NewtonGen 在标准视频扩散模型中加入一个 NND 模块:
\[ \begin{aligned} v_t &= \text{VelocityNet}_\psi(z_t, t) \\ a_t &= \text{AccelNet}_\psi(z_t, v_t, t, F_{\text{ext}}) \\ z_{t+1}^{\text{physics}} &= z_t + \Delta t \cdot v_t + \frac{(\Delta t)^2}{2} a_t \\ z_{t+1} &= (1 - \lambda) \cdot z_{t+1}^{\text{diffusion}} + \lambda \cdot z_{t+1}^{\text{physics}} \end{aligned} \]
\(\lambda\) 控制物理约束的强度——\(\lambda = 0\) 回退为标准扩散,\(\lambda = 1\) 完全由物理主导。
3.3 可控物理参数
NewtonGen 支持用户指定物理参数来控制生成:
| 参数 | 含义 | 效果 |
|---|---|---|
| 重力 \(g\) | 重力加速度 | 改变物体下落速度 |
| 恢复系数 \(e\) | 弹性碰撞程度 | 控制弹跳高度 |
| 摩擦系数 \(\mu\) | 表面摩擦 | 影响滑动速度 |
| 外力 \(\mathbf{F}_{\text{ext}}\) | 施加的力 | 推动物体运动 |
4. NewtonRewards:用后训练奖励教模型物理
4.1 另一种思路
前面三种方法都在训练/推理过程中嵌入物理。NewtonRewards(2025)走了一条更简单的路:后训练——用可验证的物理奖励对已有视频模型做 RLHF。
4.2 可验证物理奖励
速度奖励:通过光流估计速度,检查是否满足匀加速运动:
\[ r_{\text{vel}} = -\sum_t \|v_t - (v_0 + a \cdot t)\|^2 \]
如果物体做自由落体,\(a = g\),奖励鼓励模型生成符合 \(v = v_0 + gt\) 的运动。
质量一致性奖励:检测到的物体应有一致的质量表现:
\[ r_{\text{mass}} = -\text{Var}\left(\frac{F_i}{a_i}\right)_{i=1}^{N} \]
如果同一个物体在不同碰撞中表现出不同的质量(\(m = F/a\) 不一致),给低奖励。
综合奖励:
\[ r = w_1 r_{\text{vel}} + w_2 r_{\text{mass}} + w_3 r_{\text{quality}} \]
4.3 后训练流程
用已有视频模型生成 \(N\) 个候选视频
计算每个视频的物理奖励
用 GRPO/DPO 等方法优化模型偏好
4.4 NewtonBench-60K
NewtonRewards 附带了 NewtonBench-60K 评测基准——60K 个视频,涵盖 5 种牛顿运动元(Newtonian Motion Primitives):
| 运动元 | 物理现象 | 示例 |
|---|---|---|
| 自由落体 | \(y = \frac{1}{2}gt^2\) | 球从高处落下 |
| 水平抛出 | 匀速水平 + 匀加速下落 | 球从桌边滚落 |
| 抛物线抛出 | 抛物线轨迹 | 投篮 |
| 斜面下滑 | \(a = g\sin\theta\) | 物体沿斜面滑下 |
| 斜面上滑 | 先减速后加速 | 物体被推上斜面 |
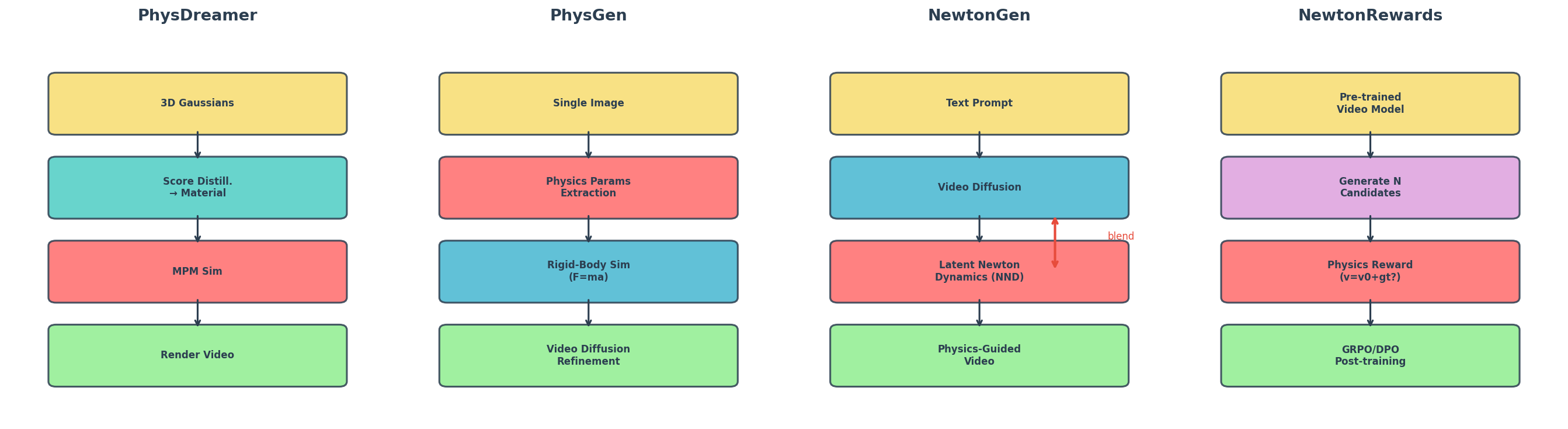
5. 四种方案对比
| 方案 | 物理嵌入方式 | 优点 | 局限 |
|---|---|---|---|
| PhysDreamer | 蒸馏材质参数 + MPM 仿真 | 物理准确的3D形变 | 仅弹性体,速度慢 |
| PhysGen | 先仿真后生成 | 力控制,刚体物理 | 仿真粗糙,仅2D |
| NewtonGen | 潜空间牛顿方程 | 端到端,参数可控 | 物理近似 |
| NewtonRewards | 后训练物理奖励 | 即插即用,不改架构 | 依赖奖励质量 |
6. 物理约束的数学框架
6.1 守恒律作为损失项
物理中最基本的约束是守恒律。可以将其作为正则化项加入训练损失:
能量守恒:
\[ \mathcal{L}_{\text{energy}} = \left|\sum_i \frac{1}{2}m_i v_i^2(t) + m_i g h_i(t) - E_0\right|^2 \]
动量守恒(无外力时):
\[ \mathcal{L}_{\text{momentum}} = \left\|\sum_i m_i \mathbf{v}_i(t) - \mathbf{p}_0\right\|^2 \]
6.2 PINN 式混合动力学与 2025 年的理论反思
Physics-Informed Neural Networks(PINN)的核心思想:让神经网络的输出满足物理 PDE。
对于视频世界模型,理论上可以要求:
\[ \mathcal{L}_{\text{total}} = \underbrace{\mathcal{L}_{\text{data}}}_{\text{拟合数据}} + \alpha \underbrace{\mathcal{L}_{\text{PDE}}}_{\text{满足物理方程}} \]
例如,对流体场景,\(\mathcal{L}_{\text{PDE}}\) 可以是 Navier-Stokes 方程的残差:
\[ \mathcal{L}_{\text{NS}} = \left\|\frac{\partial \mathbf{u}}{\partial t} + (\mathbf{u} \cdot \nabla)\mathbf{u} + \frac{1}{\rho}\nabla p - \nu \nabla^2 \mathbf{u}\right\|^2 \]
理论局限性与 2025 年的实证挑战:
尽管将物理方程作为损失项(PINN 范式)在科学计算中很成功,但在高维视频生成中遇到了巨大阻力。2025 年发表于 ICML 的研究(How Far Is Video Generation from World Model)以及相关的物理评测基准(如 MORPHEUS,2025)揭示了深层原因:
- 表观特征的"捷径"(Shortcut Learning):视频模型在优化 \(\mathcal{L}_{\text{total}}\) 时,倾向于优先拟合颜色、大小等表观特征,而不是速度、加速度等物理特征。因为在像素空间中,改变颜色的梯度远大于改变运动轨迹的梯度。
- 基于案例的泛化(Case-based Generalization):即使加上了物理正则化,模型依然没有抽象出普遍的物理规律(如动量守恒),而是在遇到新场景时,试图"回忆"并拼接训练集中最相似的视觉片段。这导致在分布外(OOD)场景下,物理约束往往失效。
- 评估的错觉:传统的评估方法(如 FID 或人类主观评价)往往会被"视觉上合理但物理上错误"的视频欺骗。只有引入基于守恒律的严格物理指标,才能发现当前最先进的视频模型在物理推理上依然极其脆弱。
因此,纯粹的软约束(Loss penalty)很难让视频模型真正"理解"物理,这也是为什么像 PhysGen 这样采用硬约束(先显式仿真,后视频渲染)的混合管线在当前阶段更为可靠。
7. 总结:物理知识如何进入视频模型?
物理化的视频生成代表了世界模型领域最重要的交叉方向——数据驱动的学习与物理知识的注入并非对立,而是互补。四种方案形成了一个从"硬物理"到"软物理"的谱系:
| 方案 | 物理嵌入方式 | 物理保证强度 | 灵活性 |
|---|---|---|---|
| PhysDreamer | 显式 MPM 仿真 | 最强(精确方程) | 最低(需要 3D 表示) |
| PhysGen | 先仿真后渲染 | 强(刚体方程) | 中等(2D 仿真) |
| NewtonGen | 潜空间 Neural ODE | 中等(学到的近似) | 较高(端到端) |
| NewtonRewards | 后训练奖励 | 最弱(统计偏好) | 最高(不改架构) |
当前的趋势是混合方案——用物理仿真提供"骨架",用视频生成填充视觉细节;或用可验证的物理奖励在后训练阶段"校准"模型的物理直觉。下一篇将进入世界模型最重要的工业应用之一——自动驾驶。
参考资料:
- Zhang, T., ... & Freeman, W. T. (2024). PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation. ECCV 2024.
- Liu, S., ... & Wang, S. (2024). PhysGen: Rigid-Body Physics-Grounded Image-to-Video Generation. ECCV 2024.
- Pan, Y., ... & Lu, C. (2025). NewtonGen: Physics-Consistent and Controllable Text-to-Video Generation via Neural Newtonian Dynamics. arXiv:2509.21309.
- Duan, H., ... & Li, Y. (2025). What about gravity in video generation? Post-Training Newton's Laws with Verifiable Rewards. arXiv:2512.00425.
- Kang, G., et al. (2025). How Far Is Video Generation from World Model: A Physical Law Perspective. ICML 2025.
- (2025). MORPHEUS: A Physics-Informed Benchmark for Video Generation. arXiv:2504.02918.