笔记|世界模型(一):世界模型全景综述——从认知科学到通用物理智能
系列说明:本文是世界模型系列的第一篇,也是一篇面向初学者的全景综述。本文从最直觉的类比出发,剥离了繁复的数学,带你看懂世界模型的核心架构、两大路线之争以及它的前世今生。
闭眼踢球——大脑里的物理模拟器
闭上眼睛,想象你在踢一个足球。球从脚尖飞出,在空中画一条抛物线,弹地后滚动减速。你不需要真的看到球,就能在脑海中预测它的轨迹。这种能力,来自你大脑中的世界模型——一个关于物理世界如何运作的内部模拟器。
认知科学家 Kenneth Craik 在 1943 年就提出了这个概念:"如果生物体能在头脑中构建一个外部现实的微型模型,它就能在行动前先在模型中尝试各种方案,预测哪种最优。"
在深度学习中,世界模型就是这个内部模拟器的计算实现:一个能够预测环境在你的动作下会如何变化的神经网络。这个定义虽然简单,却引出了 AI 领域最激动人心的研究路线之一。从 DeepMind 的 Dreamer 在虚拟想象中训练机器人,到 OpenAI 的 Sora 将视频生成重新定义为世界模拟,再到 LeCun 提出的 JEPA 试图改变 AI 理解世界的方式——世界模型正在成为通往通用人工智能(AGI)的关键拼图。
世界模型的核心架构
无论技术路线怎么变,世界模型的底层架构大多包含四个核心组件:
- 推断模型(编码器):从“看到的东西”反推“世界真正的样子”。智能体的视野总是局部的,它需要把复杂的像素画面,压缩成只保留关键信息的低维潜状态(Latent State)。
- 动力学模型(模拟器):在脑中模拟“如果我这样做,世界会怎么变”。给定当前状态和动作,向前推演下一步。这是世界模型的核心引擎,它能纯凭想象推演未来。
- 观测模型(解码器):把脑中推演出的状态,重新渲染成像素画面。这主要用来检验模型有没有瞎想——如果无法还原画面,说明想象已经脱离了现实。
- 奖励模型(裁判):评估脑中推演出的未来局面对自己有多好。这样智能体就能在不实际采取行动的情况下,选出最佳方案。
训练的核心痛点: 模型需要学会在脑中做梦(预测未来),但又要防止乱做梦。训练的底层逻辑就是在追求预测准确性和不丢弃环境随机性之间找平衡。为此,学术界(特别是著名的 Dreamer 系列)摸索出了几个重要技巧:
- 拆分确定与随机(RSSM):把对未来的预测拆成两部分,一部分像物理定律一样必然发生(确定性),另一部分允许有多种可能性(随机性)。
- 非对称优化(KL Balancing):在调整预测时,多去惩罚那些“闭卷乱猜”的部分,少去苛求那些本来就很难预测的环境细节。
经典起源:Ha & Schmidhuber (2018)
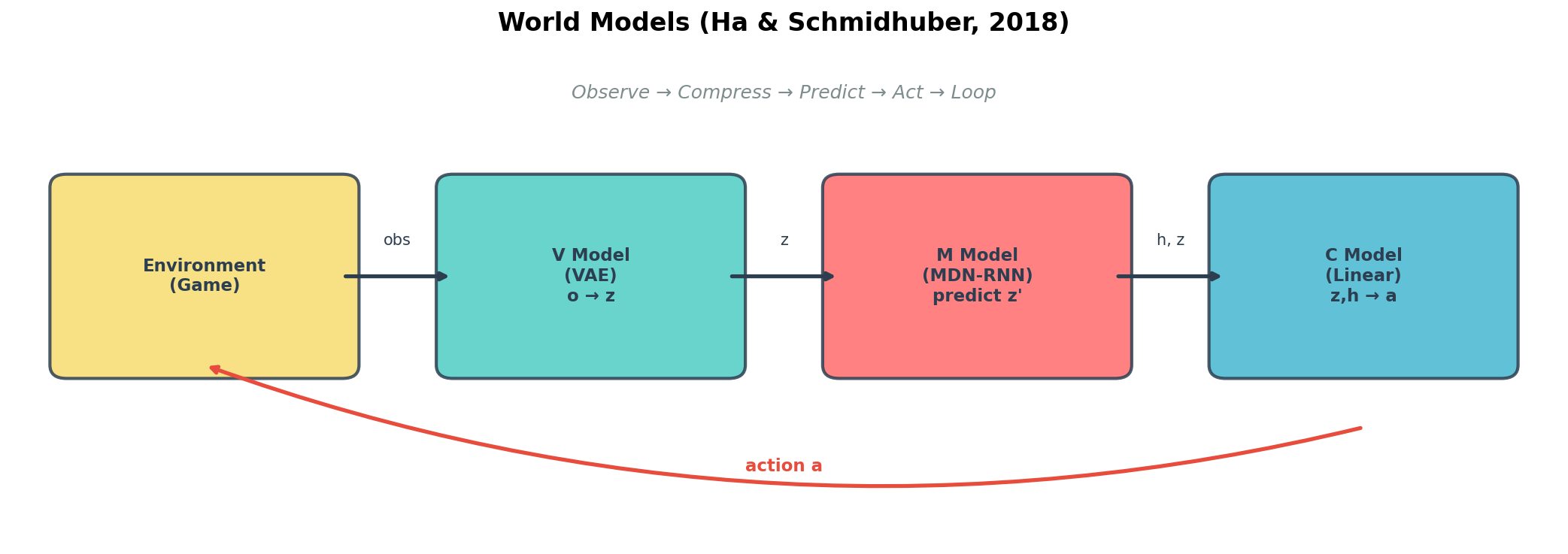
2018 年,David Ha 和 Jürgen Schmidhuber 首次将“世界模型”的概念在深度学习中系统化。他们用三个模块复现了人类的思维过程:
- V 模型(Vision,看):用变分自编码器(VAE)把复杂的像素画面压缩成几十个数字的低维向量。
- M 模型(Memory,想):用 RNN 预测这几十个数字在下一步会怎么变。
- C 模型(Controller,做):一个极简的控制器,根据压缩后的状态做出决策。
他们最惊艳的实验是:先让 V 和 M 看看真实游戏,然后完全在 M 模型生成的“梦境”中训练控制器,最后把这个控制器丢回真实游戏里,直接通关了。这完美证明了:只要学懂了世界的运作规律,就可以在想象中无限练习。
为什么要在“潜空间”做梦?
为什么不直接预测下一帧的像素?
- 维度太高,学不动:一帧画面动辄上万个像素,其中绝大多数是风吹草动、光影变化等无关紧要的废话细节。把像素压缩成低维特征(潜空间),就是过滤掉这些废话,只保留“前面有辆车在左转”这样的核心语义。
- 误差会滚雪球:连续预测 50 步未来,如果在像素层面上预测,哪怕每步错一点点,几十步后画面就彻底糊了。而在低维空间里,只有几十个核心数字,误差累积极慢,长程预测稳定得多。
路线之争:预测派 vs 生成派
截至 2026 年,世界模型百花齐放。但褪去外衣,其核心分歧只有一条:世界模型到底需不需要“看得见”(重建像素)? 这将整个领域分成了两大阵营:
1. 预测派(Predictive)—— 决策不需要看清细节
预测派认为:真实世界有太多不可预测的废话细节(比如树叶的摆动)。强行预测每一个像素纯属浪费算力。所以,预测派既不预测你的下一个动作,也不预测下一帧具体的像素画面,而是预测“世界未来的抽象状态(潜变量)”。只要模型在脑海里预测的这个抽象状态是符合物理规律的,能用来做决策就行了。
- Model-based RL(在想象中控制):代表作 Dreamer 系列。它在抽象空间里做梦、训练策略,甚至通过数值缩放等工程技巧,用一套死磕的参数横扫了上百个不同领域的任务。
- JEPA 架构(完全抛弃像素):Yann LeCun 主导的 V-JEPA。它连解码器都不要了,直接预测未来的抽象特征。因为不生成像素,它的效率极高,但训练时为了防止模型“偷懒”(把所有特征都预测成 0),引入了非对称的动量更新机制。
2. 生成派(Generative)—— 完美重建即完美理解
生成派(以 OpenAI 为代表)则坚信大力出奇迹:只要模型能完美生成高保真的未来视频,它在内部就必然已经学懂了物理规律。
- 视频生成即世界模拟器:代表作 Sora, Genie 3, Cosmos。它们能生成极其逼真的视频,Genie 3 甚至能从无标注视频中反推出潜在动作,让你能像打游戏一样和生成的视频交互。
- 物理化世界模型(进阶补丁):因为纯靠看视频很难学懂牛顿定律(容易出现穿模、重力异常),2025-2026 年的最新研究开始往生成模型里强行注入物理常识。方法包括:直接外挂物理引擎跑出真轨迹引导生成、用大模型当物理裁判给错误梯度惩罚,甚至用强化学习(DPO)去对齐物理定律。
这不仅在基础大模型中爆发,还一路延伸到了自动驾驶(例如 OccWorld,不看像素,直接预测 3D 占据栅格里哪里有障碍物)和3D空间智能(李飞飞团队的 World Labs,致力于生成几何与物理一致的 3D 空间)。
终局:万物归一
生成派和预测派真的是水火不容吗?2026 年的 Var-JEPA 给出了一统的数学证明:两者其实共享同一套变分推断框架,区别仅在于一个旋钮——观测噪声的大小。当观测噪声较大时,潜变量必须保持概率分布以应对不确定性,模型需要解码器来重建观测,这就是生成派的完整形态;当观测噪声趋近于零时,概率分布坍缩为确定性的点,解码器变得多余,模型退化为直接在抽象空间中预测未来状态——这就是 JEPA(预测派)。换句话说,JEPA 是变分推断在"零噪声"极限下的确定性特例,预测派与生成派不过是同一套数学框架在这个旋钮不同位置上的表现。
开放问题与总结
尽管进展神速,世界模型仍面临几个核心挑战:
- 长期一致性:当前模型在长时间跨度的想象预测上仍易崩溃。
- 因果 vs 相关:如何证明模型真正掌握了因果推理,而非仅是海量数据的相关性插值?
- Sim2Real 鸿沟:在完美的梦境中学到的策略,如何无缝迁移到嘈杂的真实机器人上。
本文从最直觉的类比出发,剥离了繁复的数学,梳理了世界模型的核心架构(看、想、做、评),回顾了其经典起源,并清晰地划分了当前的两大核心阵营:预测派与生成派。
下一篇将深入 Dreamer 系列——目前 Model-based RL 方向最成功的世界模型家族,看它是如何真正在想象中学会控制的。
参考文献: 1. Craik, K. (1943). The Nature of Explanation. 2. Ha, D. & Schmidhuber, J. (2018). World Models. arXiv:1803.10122. 3. Hafner, D. et al. (2020/2021/2023). Dreamer 系列 (v1–v3). ICLR 2020/2021, arXiv:2301.04104. 4. LeCun, Y. (2022). A Path Towards Autonomous Machine Intelligence. 5. Bardes, A. et al. (2024). V-JEPA. Meta AI. 6. Var-JEPA (2026). arXiv:2603.20111. ICML 2026. 7. OpenAI (2024). Video Generation Models as World Simulators. 8. DeepMind (2024/2025). Genie 系列 (1–3). 9. Zheng, W. et al. (2024). OccWorld. ECCV 2024. 10. Ding, Z. et al. (2025). A Comprehensive Survey of World Models. arXiv:2411.14499.