笔记|强化学习(九):DanceGRPO 与 MixGRPO——视觉生成 GRPO 的扩展与加速
Flow-GRPO 证明了 GRPO 在图像生成上的有效性,但留下了两个方向的空白:任务维度(能否推广到视频?)和效率维度(全轨迹 SDE 的开销能否降低?)。
本文讲清楚两篇一脉相承的工作:DanceGRPO 解决了"广度"问题,将 GRPO 统一到 Diffusion + Flow Matching 双范式和图像+视频双模态;MixGRPO 解决了"效率"问题,用混合 ODE-SDE 和滑动窗口将训练时间砍掉 50%~71%。
⬅️ 上一篇:笔记|强化学习(八):SuperFlow 与图像生成 RL 前沿(2026)
➡️ 下一篇:笔记|强化学习(十一):V-GRPO——用变分方法让扩散模型的在线 RL 变得简单
论文: - DanceGRPO: Unleashing GRPO on Visual Generation(ByteDance, 2025) - MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE(Tencent Hunyuan, 2025)
Part I: DanceGRPO 的理论分析
出发点:Flow-GRPO 留下了哪些空白
Flow-GRPO(前文已详细讨论)首次将 GRPO 引入 Flow Matching 模型,通过 ODE→SDE 转换实现了随机探索。它的理论框架(论文 Eq. 7)适用于 Flow Matching 模型全家族,而非仅限于 Rectified Flow 一种实例。但它存在两个显著局限:
- 范式局限:Flow-GRPO 的 ODE→SDE 转换要求模型预测速度场 \(v_t\),这是 Flow Matching 模型的特征。传统 Diffusion 模型(如 SD v1.4)使用噪声预测 \(\epsilon\)-prediction 和不同的前向过程(\(z_t = \alpha_t x + \sigma_t \epsilon\)),其 SDE 形式与 Flow Matching 在数学结构上不同。Flow-GRPO 未对 Diffusion 模型进行适配。
- 模态局限:仅处理文生图(T2I),未触及视频生成(T2V、I2V),而视频的高维度、高算力需求和更复杂的评价标准是全新的挑战。
- 方法局限:先前的 RL 方法(DDPO、DPOK)在大规模 Prompt 集上训练不稳定,且未在 Flow Matching 模型上被充分验证。
DanceGRPO 的出发点就是:能否用一个统一的 GRPO 框架,同时覆盖 Diffusion 和 Flow Matching(含 Rectified Flow)两种范式、图像和视频两种模态?
关键贡献一:统一的 SDE 公式——从 Flow Matching 到 Diffusion
DanceGRPO 的第一个理论贡献是推导出覆盖传统 Diffusion 模型和Flow Matching 模型(含 Rectified Flow)的统一 SDE 框架。为了理解这个贡献,我们需要先弄懂这两个公式背后的物理意义。
1. 为什么需要 SDE(随机微分方程)? 无论是 Diffusion 还是 Flow Matching,它们在推理时通常使用常微分方程(ODE)进行确定性采样。但强化学习(RL)的核心是试错与探索(Exploration)。如果每次给定相同的 Prompt 和初始噪声,模型生成的轨迹完全一样,RL 就无法通过对比“好”与“坏”的样本来学习。因此,必须将确定性的 ODE 转换为包含随机噪声的 SDE。
2. 传统 Diffusion Model 的反向 SDE(基于 Score-based SDE 理论): \[dz_t = \underbrace{f_t z_t dt}_{\text{收缩项}} - \underbrace{\frac{1}{2}g_t^2\nabla\log p_t(z_t)dt}_{\text{去噪引导项}} - \underbrace{\frac{\varepsilon_t^2}{2}g_t^2\nabla\log p_t(z_t)dt + \varepsilon_t g_t\,dw}_{\text{Langevin 随机探索项}}\]
- 物理意义:前两项是确定性的,负责把纯噪声一步步还原成图像。最后面的
Langevin 随机探索项是为了 RL 引入的“扰动”。它在注入随机噪声(\(\varepsilon_t g_t\,dw\))让模型去探索不同画面的同时,又加入了一个基于 Score 的修正力(\(-\frac{\varepsilon_t^2}{2}g_t^2\nabla\log p_t(z_t)dt\)),确保这种随机扰动不会破坏图像原本的概率分布。
3. Flow Matching / Rectified Flow 的反向 SDE(基于 Stochastic Interpolant 理论): \[dz_t = \underbrace{u_t dt}_{\text{直线速度场}} - \underbrace{\frac{1}{2}\varepsilon_t^2\nabla\log p_t(z_t)dt + \varepsilon_t\,dw}_{\text{随机探索与修正项}}\]
- 物理意义:与 Diffusion 类似,第一项 \(u_t dt\) 是 Flow Matching 特有的直线速度场,直接指向目标图像。后面的项同样是注入随机噪声并用 Score 函数进行修正,以保证探索过程的合法性。
4. 统一的数学本质 这两个 SDE 看起来不同,但 DanceGRPO 借助 Stochastic Interpolant 框架(Albergo et al., 2023)证明它们在数学结构上完全等价:Diffusion 的弯曲路径 \(z_t = \alpha_t x_0 + \sigma_t \epsilon\) 和 Rectified Flow 的直线路径 \(z_t = (1-t)x_0 + tx_1\) 本质上都是对数据和噪声的插值。只要对 Diffusion 做坐标缩放(\(\tilde{z} = z/\alpha\),\(\eta = \sigma/\alpha\)),两者就坍缩为同一个公式 \(\tilde{z}_s = \tilde{z}_t + \text{网络输出} \cdot (\eta_s - \eta_t)\)。这意味着同一套 GRPO 代码可以直接通吃两种范式,DanceGRPO 也因此成为首个在 SD v1.4(Diffusion)和 FLUX/HunyuanVideo(Flow Matching)上统一验证的 GRPO 框架。
关键贡献二:面向视频的多维奖励机制
视频的评价维度远比图像复杂。DanceGRPO 使用 VideoAlign 作为代理奖励模型(RM),它评估三个独立维度:
- VQ(Visual Quality):画面质量、美学水平
- MQ(Motion Quality):运动流畅度、物理合理性
- TA(Text Alignment):文本-视频对齐度(实验中发现不稳定,被排除)
如果将 VQ 和 MQ 简单加权求和后再做组内标准化,VQ 的绝对值范围(约 [4, 8])远大于 MQ(约 [0, 4])。更致命的是,方差较小的奖励项(MQ)在最终 Advantage 中的梯度贡献会被方差大的项(VQ)完全“吃掉”,导致模型忽视动作质量。这被称为尺度淹没。DanceGRPO 提出分项标准化(本质上是在做梯度归一化):
\[\hat{A}_i^{(d)} = \frac{r_i^{(d)} - \bar{r}_{\text{group}}^{(d)}}{\sigma_{\text{group}}^{(d)} + \epsilon}, \quad d \in \{\text{VQ}, \text{MQ}\}\]
每个维度独立计算组内优势后,各自应用 PPO clip loss,最后加权合并:\(L = \alpha_\text{VQ} \cdot L^\text{(VQ)} + \alpha_\text{MQ} \cdot L^\text{(MQ)}\)。
关键贡献三:共享初始噪声与训练稳定性
Flow-GRPO 对同一 Prompt 的 \(G\) 个样本使用不同的初始噪声 \(x_T^{(i)} \sim \mathcal{N}(0, I)\),以增加探索多样性。其消融实验(论文 Fig. 10)证实这在图像生成中是有益的。
但 DanceGRPO 发现,在视频生成的高维空间中,不同初始噪声会导致严重的 reward hacking(论文 Fig. 8)——模型找到某些噪声模式能"欺骗"奖励模型,产生视觉上不合理但分数虚高的视频。
DanceGRPO 改为:同一 Prompt 的所有 \(G\) 个样本共享同一个初始噪声,差异仅来自 SDE 过程中各步注入的随机噪声。这使得组内对比更加公平——差异反映的是去噪策略的好坏,而非初始条件的不同。
关键贡献四:时间步随机抽样
完整的去噪轨迹需要 \(T\) 步(如 25~50 步)。如果每步都反向传播计算梯度,显存需求将不可承受,尤其是视频任务。DanceGRPO 提出随机子采样:
- 全轨迹 Rollout + 随机子集:先用 SDE 无梯度走完
\(T\) 步,记录每步的 latent、timestep
和
log_prob;再将时间步打乱,按比例 \(\tau\)(默认 0.6)截取前 \(K = \lfloor T \times \tau \rfloor\) 步用于优化,打破相邻步的梯度相关性。 - 单步独立反传:对选中的 \(K\) 步逐步计算 PPO Clip Loss 并立刻
.backward(),不拼接大计算图,显存占用始终相当于单步。
论文 Fig. 4(b) 的消融实验揭示了一个关键规律:前 30% 时间步(靠近噪声端、构图阶段)贡献最大,后期步贡献递减。随机 60% 可以接近全量的性能。
DanceGRPO 的实验成果
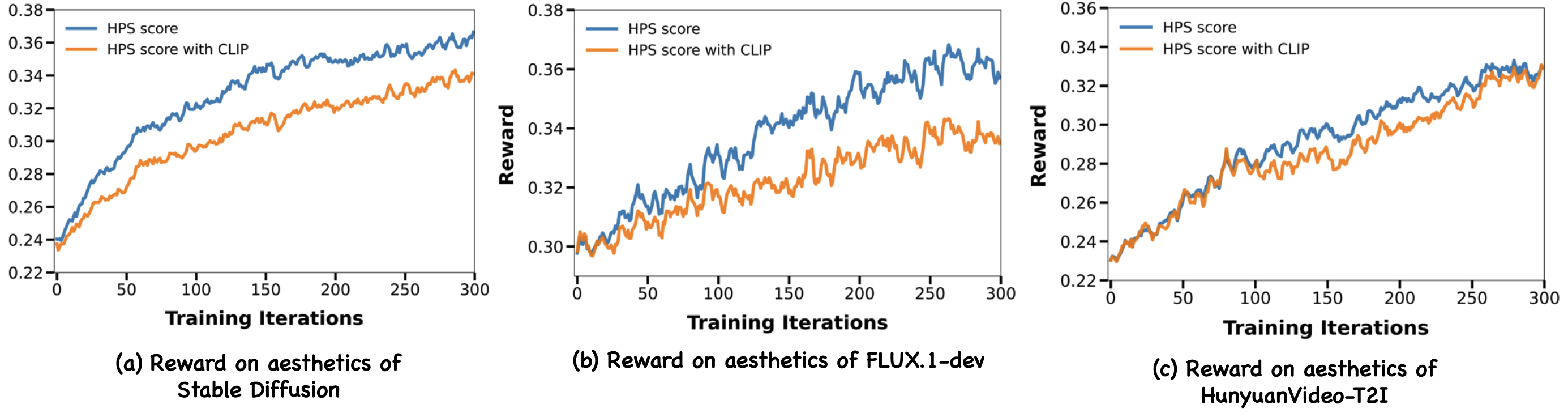
| 任务 | 基线 | DanceGRPO | 提升 |
|---|---|---|---|
| T2I HPS-v2.1(FLUX) | 0.304 | 0.372 | +22% |
| T2I CLIP Score(FLUX) | 0.405 | 0.427 | +5% |
| T2V VQ(HunyuanVideo) | 4.51 | 7.03 | +56% |
| T2V MQ(HunyuanVideo) | 1.37 | 3.85 | +181% |
| I2V MQ(SkyReels-I2V) | — | — | +118% |
DanceGRPO 在四个基础模型(SD v1.4、FLUX、HunyuanVideo、SkyReels-I2V)上均表现稳定,人类评估中 RLHF 优化后的模型在 T2I、T2V、I2V 三个任务上均被一致偏好。
与 DDPO、DPOK、ReFL、DPO 等方法相比,DanceGRPO 是唯一同时满足以下全部条件的方法:RL-based + 视频支持 + 大规模数据可扩展 + 显著奖励提升 + 同时兼容 Diffusion 和 Flow Matching(Rectified Flow)+ 不要求可微奖励。
DanceGRPO 的遗留问题
尽管贡献显著,DanceGRPO 存在两个核心瓶颈——它们是 MixGRPO 的直接动机:
问题一:全轨迹 SDE 的算力浪费 + 不必要的随机性 Rollout 阶段必须在 \(T\) 步去噪的每一步注入 SDE 噪声以满足 MDP 建模,导致无法使用 DPM-Solver++ 等高阶 ODE 求解器加速数据收集。更根本的是,生成过程具有阶段性(早期定构图、后期修细节),却在所有时间步都注入探索噪声——在不需要探索的步上浪费了算力。
问题二:随机抽样导致的策略偏移与梯度冲突 采样时整条轨迹 \(T\) 步都注入探索噪声,训练时却只随机优化其中 \(K\) 步(如 4 步),未被选中的步上的错误探索无法纠正;同时,打乱后的 \(K\) 步混在同一 Batch 中,早期构图步与后期细节步的梯度方向可能冲突。实验证明:优化步数从 14 降到 4 时,ImageReward 下降 7%。MixGRPO 论文评价:“这种方法并没有从根本上解决计算开销的问题。”
Part II: MixGRPO 的理论分析
出发点:重新审视 MDP 的范围
MixGRPO 从一个根本性的观察出发:Flow-GRPO 和 DanceGRPO 将整条去噪轨迹 \((s_0, a_0, \ldots, s_T, a_T)\) 建模为 MDP,但并非所有步都需要是随机的。 ODE 步是确定性的,不产生探索——它们在 MDP 中贡献零信息量但消耗大量计算。
因此,MixGRPO 提出:将 MDP 缩短到仅包含 SDE 步的子区间,其余步退化为确定性 ODE。
关键贡献一:混合 ODE-SDE 采样

MixGRPO 在去噪时间线上定义一个子区间 \(S = [t_l, t_r) \subseteq [0, 1)\),在 \(S\) 内用 SDE,在 \(S\) 外用 ODE:
\[dx_t = \begin{cases} \left(v_\theta - \frac{1}{2}\sigma_t^2\,s_t(x_t)\right)dt + \sigma_t\,dw, & t \in S \\ v_\theta\,dt, & \text{otherwise} \end{cases}\]
其中 Score Function \(s_t(x_t) = -\frac{x_t}{t} - \frac{1-t}{t}v_\theta(x_t, t)\) 由 Tweedie 公式给出。
边界条件的平滑性:在窗口 \(S\) 的边界处(即从 SDE 切换回 ODE 的瞬间),由于没有引入额外的非连续跳变,整个轨迹的马尔可夫性并没有被破坏。这是其能在窗口外安全使用高阶求解器加速的数学前提。
Euler-Maruyama 离散化后:
\[x_{t+\Delta t} = \begin{cases} x_t + \mu_\theta(x_t, t)\Delta t + \sigma_t\sqrt{\Delta t}\,\epsilon, & t \in S \\ x_t + v_\theta(x_t, t)\Delta t, & \text{otherwise} \end{cases}\]
SDE 漂移项 \(\mu_\theta = v_\theta + \frac{\sigma_t^2}{2t}(x_t + (1-t)v_\theta)\)。
GRPO 优化的范围缩小为仅 \(S\) 内的步:
\[J_\text{MixGRPO}(\theta) = \mathbb{E}\left[\frac{1}{N}\sum_{i=1}^{N}\frac{1}{|S|}\sum_{t\in S}\min\left(r_t^i\hat{A}^i,\ \text{clip}(r_t^i, 1-\varepsilon, 1+\varepsilon)\hat{A}^i\right) - \beta J_\text{KL}\right]\]
收敛性保证: MixGRPO 在 Supplementary 中利用 Fokker-Planck 方程证明:SDE 中多出的漂移项与扩散噪声项精确对消一半,混合 ODE-SDE 采样与纯 ODE 采样产生完全相同的边缘分布 \(q_t(x)\)——无论在哪个时间段切换,宏观概率密度演化轨迹一致。
关键贡献二:滑动窗口作为优化调度器
\(S\) 不是固定的——它是一个滑动窗口 \(W(l) = \{t_l, t_{l+1}, \ldots, t_{l+w-1}\}\),随训练进行从低 SNR 向高 SNR 移动:
\[l \leftarrow \min(l + s,\; T - w) \quad \text{every } \tau \text{ iterations}\]
这等价于一种隐式课程学习(analogous to temporal discounting in RL):
- 在训练早期,窗口位于低 SNR 区域(靠近纯噪声端,\(l \approx 0\))。此时模型主要优化全局构图和物体布局,探索空间大,具有较高的随机性。
- 在训练后期,窗口滑动到高 SNR 区域(靠近干净图像端,\(l \rightarrow T-w\))。此时模型主要优化纹理细节和色彩精修,探索空间小,随机性更低。
MixGRPO 论文的消融实验验证了这种直觉:
| 窗口策略 | HPS-v2.1 | ImageReward | 要点 |
|---|---|---|---|
| Frozen(固定开头) | 0.354 | 1.580 | 缺乏后期细节优化 |
| Random(随机跳跃) | 0.365 | 1.513 | 破坏学习连贯性 |
| Progressive + Constant \(\tau\) | 0.367 | 1.629 | HPS 最优 |
| Progressive + Exp Decay \(\tau\) | 0.360 | 1.632 | ImageReward 最优 |
Progressive 一致优于 Random,验证了课程学习优于随机抽样。即使 Frozen 也超过 DanceGRPO(NFE=4 时 1.335),说明定向优化前几步比全轨迹 SDE + 随机抽样更有效。
MixGRPO 还提出指数衰减调度:\(\tau(l) = \tau_0 \cdot \exp(-k \cdot \text{ReLU}(l - \lambda_\text{thr}))\),让模型在影响最大的构图阶段停留更久。
关键贡献三:MixGRPO-Flash 高阶求解器加速
MixGRPO 的混合策略带来了一个巨大的工程收益:窗口外的 ODE 步可以用高阶求解器(如 DPM-Solver++)来加速!
在 Flow-GRPO 和 DanceGRPO 中,由于全轨迹都注入了 SDE 噪声,模型必须老老实实地走完几十步(比如 25 步),无法使用任何加速算法。而在 MixGRPO 中,只有滑动窗口 \(W\) 内是 SDE 随机探索,窗口外都是确定性的 ODE。
MixGRPO 将 DPM-Solver++ 适配到 Flow Matching 框架。关键约束:只加速窗口后(post-window)的 ODE 步——窗口前的 ODE 大步长误差会被后续 SDE 随机性放大,窗口后结构已定,误差影响可忽略。
两种加速变体:MixGRPO-Flash(Progressive 滑动 + 窗口后加速)与 MixGRPO-Flash*(Frozen 固定开头 + 后续全加速)。
| 方法 | NFE(采样步数) | 单图耗时 (s) | HPS-v2.1 | ImageReward |
|---|---|---|---|---|
| DanceGRPO (基线) | 25 | 9.30 | 0.334 | 1.335 |
| MixGRPO-Flash | 16 (平均) | 6.43 | 0.362 | 1.578 |
| MixGRPO-Flash* | 8 | 3.79 | 0.357 | 1.624 |
反直觉地,MixGRPO-Flash* 整体更优:窗口固定开头可最大化高阶求解器收益(NFE 25→8,耗时降 60%);代理 RM 对早期语义/构图更敏感,将 SDE 探索集中在低 SNR 阶段、后期 ODE 快速滑过是更优的算力分配。Flash 在 HPS-v2.1 略高(0.362 vs 0.357),但 Flash* 综合性价比最高。
补充发展:Flow-CPS 采样替代标准 SDE
在 MixGRPO 提出后不久,另一篇独立工作 Flow-CPS (arXiv:2509.05952) 专门针对标准 SDE 采样的伪影问题提出了 Coefficients-Preserving Sampling (CPS,系数保持采样)。这一技术由于效果极佳,随后被快速集成到了 MixGRPO 等各大开源代码库中。
从直觉上看,CPS 公式与之前的 SDE 似乎都在路径上注入了噪声 \(\epsilon_i\)(以提供 RL 所需的探索空间)。但两者的核心差异在于:在注入噪声后,如何保证生成轨迹的概率分布不被破坏?
标准 SDE 的做法(强行叠加 + 估算补丁): 标准 SDE(Euler-Maruyama 离散化)是在确定性步进上强行叠加一个独立的噪声: \[x_{t_{i-1}} = x_{t_i} - v_{t_i} \Delta t + \underbrace{\sqrt{2\sigma^2 \Delta t} \epsilon_i}_{\text{强行加噪}} - \underbrace{\frac{1}{2}\sigma^2 s_{t_i}(x_{t_i}) \Delta t}_{\text{Score 修正项}}\] 由于强行加噪会让总方差变大(图像变糊),SDE 必须引入基于 Score Function 的漂移修正项。但 Score 靠 Tweedie 公式估算(\(s_t \approx -(x_t - \hat{x}_0)/\sigma_t^2\)),存在后验均值坍缩、模型低频偏好和大步长离散化误差,导致高频噪声残留→颗粒感伪影,进而欺骗对纹理敏感的代理 RM(Reward Hacking)。
CPS 的做法(系数守恒,重新分配): Flow-CPS 借鉴 DDIM 的待定系数法,绕开显式 Score 估算。
如何求出系数? 在 Flow Matching 中,理论路径为 \(x_t = (1-t)x_0 + t\epsilon\)。假设下一步状态是当前状态 \(x_{t_i}\)、模型预测速度场 \(v_{t_i}\) 和新注入噪声 \(\epsilon_i\) 的线性组合: \[x_{t_{i-1}} = A \cdot x_{t_i} + B \cdot v_{t_i} + C \cdot \epsilon_i\] 将 \(x_{t_i}\) 和 \(v_{t_i}\) 展开为 \(x_0\) 和 \(\epsilon\) 的形式并代回上述方程,强制要求生成的 \(x_{t_{i-1}}\) 必须精确服从目标时刻的边缘分布 \(x_{t_{i-1}} = (1-t_{i-1})x_0 + t_{i-1}\epsilon\)。通过对比等式两边 \(x_0\) 和 \(\epsilon\) 的系数(设定 \(C = \sigma_{t_i}\)),我们可以解出严格保证均值和方差一致的系数 \(A\) 和 \(B\)。
解出系数后,我们得到最终的 CPS 采样公式:
\[x_{t_{i-1}} = (x_{t_i} - v_{t_i} \Delta t) + (\sqrt{t_{i-1}^2 - \sigma_{t_i}^2} - t_{i-1})\hat{\epsilon} + \sigma_{t_i} \epsilon_i\]
如何把这个公式变成代码?
为了方便在代码里计算,我们先定义出模型预测的两个"锚点":
- 预测的干净图:\(\hat{x}_0 = x_{t_i} - t_i \cdot v_{t_i}\)
- 预测的噪声:\(\hat{\epsilon} = x_{t_i} + (1-t_i) v_{t_i}\)
如果我们把上面长长的采样公式的前两项合并,经过简单的代数化简,它恰好等价于 \(\hat{x}_0\) 和 \(\hat{\epsilon}\) 的加权和: \[(x_{t_i} - v_{t_i} \Delta t) + (\sqrt{t_{i-1}^2 - \sigma_{t_i}^2} - t_{i-1})\hat{\epsilon} = (1-t_{i-1})\hat{x}_0 + \sqrt{t_{i-1}^2 - \sigma_{t_i}^2} \cdot \hat{\epsilon}\]
这就是我们在代码中需要计算的均值 \(\mu\)。 而公式最后一项 \(\sigma_{t_i} \epsilon_i\),就是我们需要加的噪声。
所以,复杂的公式被拆解为了极简的两步: \[x_{t_{i-1}} = \mu + \text{加的噪声}\]
这与底层的代码实现完全对应:
python# 1. 计算 μ (即代码中的 prev_sample_mean) # μ = (1 - sigma_prev) * x̂_0 + √(sigma_prev² - std²) * ε̂ prev_sample_mean = pred_original_sample * (1 - sigma_prev) + noise_estimate * math.sqrt(sigma_prev**2 - std_dev_t**2) # 2. 加上噪声 (即代码中的 μ + 加的噪声) # x_next = μ + std * ε_new prev_sample = prev_sample_mean + std_dev_t * variance_noise
MixGRPO 的实验成果

- 极致加速:在同样只优化 4 步的条件下,MixGRPO 的核心奖励(ImageReward)比 DanceGRPO 高出 22%。若启用高阶加速(MixGRPO-Flash*),训练时间可降至 DanceGRPO 的 29%(83s vs 291s),且性能依然更优。
- 图像更干净:使用 CPS 替代标准 SDE 后,所有评价指标均有提升,成功缓解了由于 Score 估算不准带来的颗粒感伪影。
- 视频更稳定:在 HunyuanVideo-1.5 视频生成任务中,如果直接使用前代方法(Flow-GRPO),由于高维空间的随机性难以控制,训练会出现“指标越训越差”的性能退化。而 MixGRPO 成功克服了这一问题,在四个评价维度上均实现了稳定的单调上升(进步)。
Part III: 核心伪代码实现
1. 采样阶段 (Rollout)
# 初始化滑动窗口 (MixGRPO)
window = [t_start, t_end]
for t in reversed(range(T)):
# 模型预测速度场
v_t = model(x_t, t)
if t in window:
# ─── 窗口内:SDE 探索 (使用 CPS 采样) ───
x_0_pred = x_t - t * v_t
eps_pred = x_t + (1 - t) * v_t
# 1. 计算均值 μ (待定系数法的解)
μ = (1 - t_prev) * x_0_pred + sqrt(t_prev**2 - σ**2) * eps_pred
# 2. 注入新噪声
x_prev = μ + σ * noise
# 记录当前步动作概率 (用于后续 PPO)
log_probs[t] = calc_gaussian_logprob(x_prev, μ, σ)
elif use_flash_acceleration and t < window[0]:
# ─── 窗口后 (接近 t=0):高阶 ODE 加速 (MixGRPO-Flash) ───
# 利用历史速度场进行大步长跨越
x_prev = DPM_Solver_Step(x_t, v_t, history_v)
else:
# ─── 窗口外常规步:ODE 确定性步进 ───
x_prev = x_t - v_t * dt
x_t = x_prev2. 训练阶段 (PPO Update)
# 确定需要优化的时间步
if is_DanceGRPO:
# 打乱全轨迹时间步,随机抽取 K 步 (易导致策略偏移)
train_steps = random_sample(all_steps, K)
elif is_MixGRPO:
# 仅优化滑动窗口内的步 (定向课程学习)
train_steps = window
for t in train_steps:
# 用最新策略重新计算动作概率
new_log_prob = current_model.calc_logprob(x_t, x_prev)
ratio = exp(new_log_prob - old_log_probs[t])
# 视频生成的分维度 PPO 裁剪 (防止 VQ 和 MQ 尺度淹没)
loss_VQ = PPO_Clip(ratio, adv_VQ)
loss_MQ = PPO_Clip(ratio, adv_MQ)
# 融合损失
loss = alpha * loss_VQ + beta * loss_MQ
# 单步独立反向传播 (极致省显存!)
loss.backward()
# 随着训练进行,更新滑动窗口向高信噪比区域 (t=0) 滑动
window = slide_window(window)Part IV: 2026 年最新前沿——从稀疏奖励到密集奖励(Dense Reward)
DanceGRPO 和 MixGRPO 之后,2026 年初的研究聚焦信用分配(Credit Assignment):标准 GRPO 只在 \(t=0\) 给出稀疏奖励并平摊给所有步,但早期步决定全局结构、后期步负责纹理——某步破坏结构却可能被错误奖励。
为实现步级信用分配,2026 年涌现三篇代表性工作:
DenseGRPO (arXiv:2601.20218):用 ODE 在中间步预测 \(\hat{x}_0\) 并打分,以相邻步得分差 \(g_t = r_{t-1} - r_t\) 作为密集奖励;同时根据步级表现自适应调整 SDE 随机性大小。
Stepwise-Flow-GRPO (arXiv:2603.28718):同样计算奖励增益 \(g_t = r_{t-1} - r_t\),利用 Tweedie 公式高效获得中间步 \(\hat{x}_0\);引入 DDIM 启发的改进 SDE,在保持策略梯度随机性的同时提高中间步图像质量,使 RM 打分更准确。
TempFlow-GRPO (ICLR 2026):在中间步进行轨迹分支采样获取过程奖励;提出噪声感知加权,让模型在早期高噪声阶段集中学习——与 MixGRPO 滑动窗口思想类似,但通过显式损失加权实现。
这些工作标志着视觉生成 RL 从"结果监督(ORM)"转向"过程监督(PRM)",与 LLM 推理(o1、DeepSeek-R1)的演进方向一致。
总结:三代方法的技术演进
| 维度 | Flow-GRPO | DanceGRPO | MixGRPO |
|---|---|---|---|
| 核心出发点 | 将 GRPO 引入 Flow Matching | 统一 Diffusion + Flow Matching,推广到视频 | 缩短 MDP,混合 ODE-SDE |
| 适用范式 | Flow Matching(含 Rectified Flow) | Diffusion + Flow Matching(统一 SDE) | 通用概率流 ODE(理论),Flow Matching(实验) |
| SDE 范围 | 全轨迹 | 全轨迹 | 仅窗口内 |
| 训练步选择 | 全部 | 随机子集 | 滑动窗口(课程学习) |
| 高阶求解器 | 不可用 | 不可用 | 窗口后可用 |
| 任务范围 | T2I | T2I + T2V + I2V | T2I + T2V |
| 收敛性证明 | Fokker-Planck | Stochastic Interpolant | 分段 Fokker-Planck(通用 ODE 形式) |
| 训练时间基线 | — | 291s/iter | 83s/iter(Flash*) |
从 Flow-GRPO 到 DanceGRPO 是广度的扩展(统一 Diffusion 与 Flow Matching 范式、拓展到视频模态);从 DanceGRPO 到 MixGRPO 是深度的优化(更好的 MDP 建模、更聪明的采样策略)。三者共同构成了概率流模型 + GRPO 方向的完整技术图谱。
这两项工作彻底打通了“如何高效训练视觉大模型”的路径。然而,当模型训练完成并部署到线上时,如何在大规模并发请求下高效地“生成轨迹并打分”,则是另一个维度的挑战。
参考资料:
- Xue, Z., et al. (2025). DanceGRPO: Unleashing GRPO on Visual Generation. arXiv:2505.07818.
- Li, J., et al. (2025). MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE. arXiv:2507.21802.
- Liu, J., et al. (2025). Flow-GRPO: Training Flow Matching Models via Online RL. arXiv:2505.05470.
- Wang, F., Yu, Z. (2025). Coefficients-Preserving Sampling for RL with Flow Matching. arXiv:2509.05952.
- DenseGRPO: From Sparse to Dense Reward for Flow Matching Model Alignment. arXiv:2601.20218.
- Stepwise Credit Assignment for GRPO on Flow-Matching Models. arXiv:2603.28718.