笔记|生成模型(十三):Flow Matching理论与实现
论文链接:Flow Matching for Generative Modeling
在 Stable Diffusion 3 中,模型是通过 Flow Matching 的方法训练的。从这个方法的名字来看,就知道它和 Flow-based Model 有比较强的关联,因此在正式开始介绍这个方法之前先交代一些 Flow-based Model 相关的背景知识。
Flow-based Models
Normalizing Flow
Normalizing Flow 是一种基于变换对概率分布进行建模的模型,其通过一系列离散且可逆的变换实现任意分布与先验分布(例如标准高斯分布)之间的相互转换。在 Normalizing Flow 训练完成后,就可以直接从高斯分布中进行采样,并通过逆变换得到原始分布中的样本,实现生成的过程。
从这个角度看,Normalizing Flow 和 Diffusion Model 是有一些相通的,其做法的对比如下表所示。从表中可以看到,两者大致的过程是非常类似的,尽管依然有些地方不一样,但这两者应该可以通过一定的方法得到一个比较统一的表示。
| 模型 | 前向过程 | 反向过程 |
|---|---|---|
| Normalizing Flow | 通过显式的可学习变换将样本分布变换为标准高斯分布 | 从标准高斯分布采样,并通过上述变换的逆变换得到生成的样本 |
| Diffusion Model | 通过不可学习的 schedule 对样本进行加噪,多次加噪变换为标准高斯分布 | 从标准高斯分布采样,通过模型隐式地学习反向过程的噪声,去噪得到生成样本 |
Continuous Normalizing Flow
Continuous Normalizing Flow(CNF),也就是连续标准化流,可以看作 Normalizing Flow 的一般形式。CNF 将原本 Normalizing Flow 中离散的变换替换为连续的变换,并用常微分方程(ODE)来表示,可以写成以下的形式: \[ \frac{\mathrm{d}\mathbf{z}_t}{\mathrm{d}t}=v(\mathbf{z}_t,t) \] 其中 \(t\in[0,1]\),\(\mathbf{z}_t\) 可以看作时间 \(t\) 下的数据点,\(v(\mathbf{z}_t,t)\) 是一个向量场,定义了数据点在每个时间下的变化大小与方向,这个向量场通常由神经网络来学习。当这个向量场完成了学习后,就可以用迭代法来求解: \[ \mathbf{z}_{t+\Delta t}=\mathbf{z}_t+\Delta t\cdot v(\mathbf{z}_t,t) \] 也就是说,一旦我们得知从标准高斯分布到目标分布的变换向量场,就可以从标准高斯分布采样,然后通过上述迭代过程得到目标分布中的一个近似解,完成生成的过程。这和离散的 Normalizing Flow 是一致的。
在 Normalizing Flow 中存在 Change of Variable Theory,这个定理是用来保证概率分布在进行变化时,概率密度在全体分布上的积分始终为 1 的一个式子,其形式为: \[ p(\mathbf{x})=\pi(\mathbf{z})\left|\mathrm{det}\ \frac{\mathrm{d}\mathbf{z}}{\mathrm{d}\mathbf{x}}\right|=\pi(\mathbf{f}^{-1}(\mathbf{x}))\left|\mathrm{det}\ \mathbf{J}(\mathbf{f}^{-1}(\mathbf{x}))\right| \] 在 Flow Matching 的论文中,也给出了形式类似的公式,称为 push-forward equation,定义为: \[ p_t=[\phi_t]_*p_0 \] 其中的 push-forward 运算符,也就是星号,定义为: \[ [\phi_t]_*p_0(x)=p_0(\phi_t^{-1}(x))\mathrm{det}\left[\frac{\partial\phi_t^{-1}}{\partial x}(x)\right] \] 可以看出形式也是类似的。
Flow Matching
图像生成任务的核心在于建模样本如何从简单的先验分布(如标准高斯分布 \(\mathcal{N}(0, \mathbf{I})\))转换到复杂的数据分布 \(p_{\text{data}}(x)\)。与基于去噪的扩散模型通过学习逐步去噪过程不同,Flow Matching 直接建模样本在两个分布之间的连续时间传输过程。从数学角度来看,Flow Matching 学习一个时间相关的向量场 \(v_t(x)\),该向量场定义了从先验分布 \(p_0\) 到目标分布 \(p_1\) 的概率路径 \(\{p_t\}_{t \in [0,1]}\)。这种方法将图像生成问题转化为最优传输问题:如何找到一个连续的概率流,使得 \(p_0 = \mathcal{N}(0, \mathbf{I})\) 和 \(p_1 = p_{\text{data}}(x)\)。因此,Flow Matching 的核心思想是在已知源分布 \(p_0\) 和目标分布 \(p_1\) 之间构造一条时间参数化的概率路径 \(\{p_t\}_{t \in [0,1]}\),并学习生成该概率路径的速度场 \(v_t(x)\)。
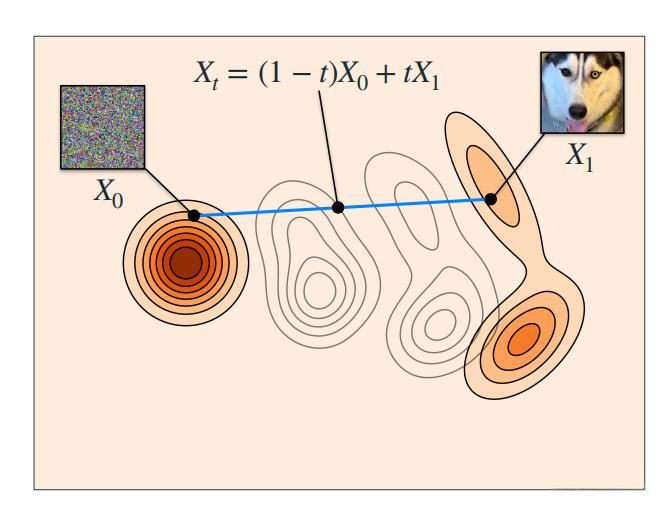
下图展示了 Flow Matching 中关键变量的定义:\(x_0\) 表示初始噪声,\(x_1\) 表示目标数据,\(x_t\) 表示时间 \(t\) 处的中间状态。 \(x_t = (1-t)x_0 + tx_1 = x_0 + t(x_1-x_0)\),其中t一般定义为采样时间步的方差,在代码中一般用sigma表示,sigma的范围是从0到1。(一般用采样时间步的归一化表示)。\(x_0 + t(x_1-x_0)\)可以理解成从\(x_0\)的起点开始,朝着\(x_{0->1}\)的方向步进了t的长度。
具体的实现步骤包括:
建模过程首先从每个分布中采样一个点,然后用路径连接它们。最常用的连接方式是直线路径:\(x(t) = (1-t)x_0 + tx_1\)。这种线性插值方法在\(x_0\)和\(x_1\)之间建立了最直接的连接路径。虽然也可以使用其他插值方法如球面插值,但线性插值因其简单性和良好的实际效果而被广泛采用。
目标是学习一个时间相关的速度场\(v(x,t)\),该速度场描述轨迹上每个点的瞬时速度。由于我们已经从路径定义中知道了真实速度,神经网络的任务是近似\(v(x,t) = x_1 - x_0\)。
训练过程就是使模型的预测速度与真实速度匹配。
\[\mathcal{L} = \mathbb{E}_{x_0,x_1,t}\left[\left\|f_\theta(x(t),t) - \frac{d}{dt}x(t)\right\|^2\right]\]
• \(x(t) = (1-t)x_0 + tx_1\): 噪声和数据的插值点
• \(f_\theta(x(t),t)\): 神经网络预测的速度
• \(\frac{d}{dt}x(t) = x_1 - x_0\): 真实速度
• \(\mathbb{E}_{x_0,x_1,t}\): 随机噪声/数据对和插值时间的期望
开源代码参考: 在实际的 PyTorch 实现中(例如 Stable Diffusion 3 或 Flux 的训练代码),Flow Matching 的 Loss 计算极其简单直观:
# x_1: 真实图片 (目标)
# x_0: 纯高斯噪声 (起点)
# t: 随机采样的时间步 [0, 1]
# 1. 线性插值得到当前时刻的 x_t
x_t = (1 - t) * x_0 + t * x_1
# 2. 计算真实的速度场 (目标速度)
target_velocity = x_1 - x_0
# 3. 神经网络预测速度场
predicted_velocity = model(x_t, t)
# 4. 计算 MSE Loss
loss = F.mse_loss(predicted_velocity, target_velocity)Flow Matching采样过程
在训练阶段,网络学习了将点从噪声移动到数据的速度场\(v(x,t)\)。训练结束后同时访问\(x_0\)和\(x_1\),但在生成阶段只有\(x_0\)。采样的目标是取一个噪声点并将其推进到\(p_1\)分布,最终获得类似自然图像的结果。
采样过程从样本\(x_0 \sim p_0\)(例如标准高斯噪声)开始,然后定义从\(t = 0\)到\(t = 1\)的时间网格,将其均分割成一系列步骤。在每个时间步,我们向前求解ODE来更新样本,采样过程一般使用欧拉积分进行迭代,欧拉积分是一阶离散的近似数值积分,为了更加精确,也会有人使用4阶龙格库塔积分进行更精细的数值积分。
\[x_{t+\Delta t} = x_t + \Delta t \cdot f_\theta(x_t, t)\]
• \(x_t\): 时间 \(t\) 处的当前样本
• \(\Delta t\): 步长(例如对于 \(N\) 步采样,\(\Delta t = \frac{1}{N}\))
• \(f_\theta(x_t, t)\): 学习到的速度场——指示在此时间点如何更新样本
• \(x_{t+\Delta t}\): 使用预测速度前进一步后轨迹上的下一个样本
速度场\(v(x,t)\)在每个步骤中与当前的\(x\)和\(t\)一起使用,以获得\(v(t)\)的估计。一旦到达\(t = 1\),就得到了一个完整看起来像自然图像的样本。这个过程类似于跟随流场,我们沿着学习的速度路径将样本"推向"数据方向。
上述的不管是欧拉数值积分,还是龙格库塔积分,他们都是一种确定性积分,所以是一条确定性路径。最终的生成样本的随机性只来源于0时刻的随机采样的高斯白噪声。 所以SD3的实现中给出了另一种形式,即随机路径。通过估计与终点图像配对的起点噪声,构建新的随机噪声作为方向向前随机步进一步(详细见推导代码实现)。
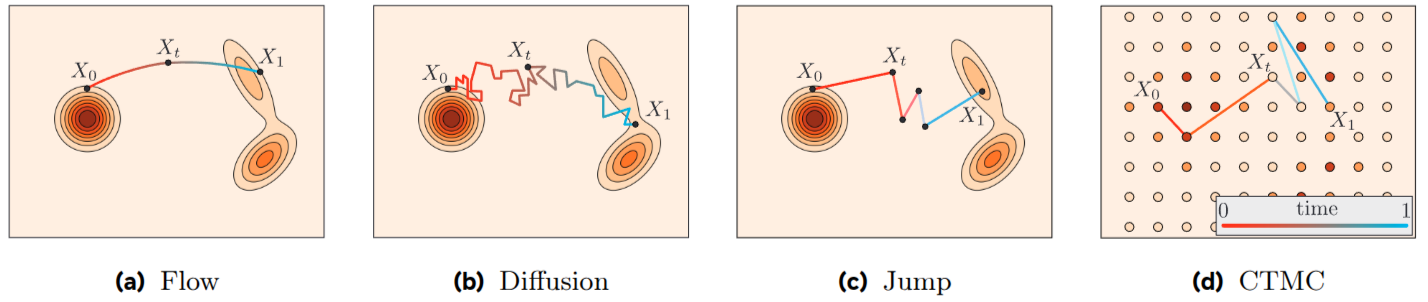
最后,在这里我们直观的展现出Flow Matching和其他方法在不同分布寻找路径的区别,四种时间连续过程 \((x_t)_{0≤t≤1}\),将源样本 \(x_0\) 传输到目标样本 \(x_1\)。这些过程分别是连续状态空间中的流、连续状态空间中的扩散、连续状态空间中的跳跃过程(密度用等高线可视化),以及离散状态空间中的跳跃过程(状态用圆盘表示,概率用颜色可视化)。
代码
时间步调度器初始化
Flow Matching的时间步调度器控制采样过程中的时间分布。通过非线性映射可以调整采样密度,让模型在关键区域有更密集的采样。
# 时间步初始化
timesteps = np.linspace(1, num_train_timesteps, num_train_timesteps, dtype=np.float32)[::-1].copy()
timesteps = torch.from_numpy(timesteps).to(dtype=torch.float32)
sigmas = timesteps / num_train_timesteps
if not use_dynamic_shifting:
sigmas = shift * sigmas / (1 + (shift - 1) * sigmas)
self.timesteps = sigmas * num_train_timestepsshift参数通过公式 \(\sigma' = \frac{\text{shift} \cdot \sigma}{1 + (\text{shift} - 1) \cdot \sigma}\) 对时间轴进行非线性变换。当shift > 1时,采样会偏向早期时间步;当shift < 1时,采样会偏向后期时间步。
时间步采样策略
训练时需要为每个batch采样不同的时间步,提供了三种采样策略:
def compute_density_for_timestep_sampling(
weighting_scheme: str, batch_size: int,
logit_mean: float = None, logit_std: float = None,
mode_scale: float = None, device = "cpu", generator = None
):
if weighting_scheme == "logit_normal":
u = torch.normal(mean=logit_mean, std=logit_std, size=(batch_size,), device=device, generator=generator)
u = torch.nn.functional.sigmoid(u)
elif weighting_scheme == "mode":
u = torch.rand(size=(batch_size,), device=device, generator=generator)
u = 1 - u - mode_scale * (torch.cos(math.pi * u / 2) ** 2 - 1 + u)
else:
u = torch.rand(size=(batch_size,), device=device, generator=generator)
return u- logit_normal: 通过sigmoid函数将正态分布映射到[0,1]区间,可以控制采样集中在特定时间段
- mode: 使用余弦变换 \(u' = 1 - u - \text{mode_scale} \cdot (\cos^2(\frac{\pi u}{2}) - 1 + u)\) 创建偏向特定模式的分布
- uniform: 标准均匀分布
训练循环核心
Flow Matching的训练目标是学习速度场 \(v_t(x_t)\),使得模型能够预测从噪声到数据的最优传输路径。
# 训练步骤
for step, batch in enumerate(train_dataloader):
# VAE编码
pixel_values = batch["pixel_values"].to(dtype=vae.dtype)
model_input = vae.encode(pixel_values).latent_dist.sample()
model_input = (model_input - vae.config.shift_factor) * vae.config.scaling_factor
noise = torch.randn_like(model_input)
bsz = model_input.shape[0]
# 时间步采样
u = compute_density_for_timestep_sampling(
weighting_scheme=args.weighting_scheme,
batch_size=bsz,
logit_mean=args.logit_mean,
logit_std=args.logit_std,
mode_scale=args.mode_scale,
)
indices = (u * noise_scheduler.config.num_train_timesteps).long()
timesteps = noise_scheduler.timesteps[indices]Flow Matching前向过程
根据线性插值公式 \(x_t = (1-\sigma_t)x_1 + \sigma_t x_0\) 构造噪声样本,其中 \(x_0\) 是噪声,\(x_1\) 是数据:
# 构造噪声样本
sigmas = get_sigmas(timesteps, n_dim=model_input.ndim, dtype=model_input.dtype)
noisy_model_input = (1.0 - sigmas) * model_input + sigmas * noise
# 模型预测
prompt_embeds = batch["prompt_embeds"].to(dtype=weight_dtype)
model_pred = transformer(
hidden_states=noisy_model_input,
timestep=timesteps,
encoder_hidden_states=prompt_embeds,
return_dict=False,
)[0]
# 计算损失
target = noise - model_input
loss = torch.mean((model_pred - target) ** 2)
def get_sigmas(timesteps, n_dim=4, dtype=torch.float32):
# 从 noise_scheduler 中取出所有预定义的 sigma 序列,
# 并将其移动到与当前加速器(如 GPU)一致的 device 和 dtype。
# 这些 sigma 通常是噪声调度表,用来控制不同时间步的噪声强度。
sigmas = noise_scheduler.sigmas.to(device=accelerator.device, dtype=dtype)
# 同样,从调度器中取出完整的时间步表(通常是从大到小的整数序列,如 [999, 998, ..., 0])。
schedule_timesteps = noise_scheduler.timesteps.to(accelerator.device)
# 将传入的 timesteps 也放到相同的 device 上,以保证比较时不会出错。
timesteps = timesteps.to(accelerator.device)
# 遍历传入的每一个时间步 t,在 schedule_timesteps 中找到它对应的索引位置。
# (schedule_timesteps == t) 会返回一个布尔张量,nonzero() 找到为 True 的索引位置。
# .item() 提取成 Python 标量。
# 最终 step_indices 是一个 Python 列表,表示每个输入 timestep 在调度表中的索引。
step_indices = [(schedule_timesteps == t).nonzero().item() for t in timesteps]
# 根据这些索引,从 sigmas 表中取出对应的 sigma 值。
# flatten() 保证 sigma 是一维的,例如形状为 [batch_size]。
sigma = sigmas[step_indices].flatten()
# 为了让 sigma 可以和 model_input (如 [B, C, H, W]) 正确广播,
# 需要不断扩展维度直到它与输入的维度数 n_dim 相同。
# 例如原来 [B] → [B, 1] → [B, 1, 1] → [B, 1, 1, 1]
while len(sigma.shape) < n_dim:
sigma = sigma.unsqueeze(-1)
# 返回最终形状的 sigma 张量,例如 [B, 1, 1, 1]
return sigma
class FlowMatchEulerDiscreteScheduler(SchedulerMixin, ConfigMixin):
_compatibles = []
order = 1
@register_to_config
def __init__(
self,
num_train_timesteps: int = 1000,
shift: float = 1.0,
use_dynamic_shifting=False,
base_shift: Optional[float] = 0.5,
max_shift: Optional[float] = 1.15,
base_image_seq_len: Optional[int] = 256,
max_image_seq_len: Optional[int] = 4096,
invert_sigmas: bool = False,
):
timesteps = np.linspace(1, num_train_timesteps, num_train_timesteps, dtype=np.float32)[::-1].copy()
timesteps = torch.from_numpy(timesteps).to(dtype=torch.float32)
sigmas = timesteps / num_train_timesteps
if not use_dynamic_shifting:
# when use_dynamic_shifting is True, we apply the timestep shifting on the fly based on the image resolution
sigmas = shift * sigmas / (1 + (shift - 1) * sigmas)
self.timesteps = sigmas * num_train_timesteps
....
速度场的真实值为 \(v_t = x_0 - x_1 = \text{noise} - \text{data}\),模型通过最小化预测速度场与真实速度场的MSE损失来学习。
推理过程
推理时从纯噪声开始,通过求解ODE逐步生成图像:
# 初始化
latents = torch.randn(shape, generator=generator, device=device, dtype=dtype)
timesteps = scheduler.timesteps
for i, t in enumerate(timesteps):
# 条件引导
if self.do_classifier_free_guidance:
latent_model_input = torch.cat([latents] * 2)
else:
latent_model_input = latents
# 预测速度场
noise_pred = transformer(
hidden_states=latent_model_input,
timestep=t.expand(latent_model_input.shape[0]),
encoder_hidden_states=prompt_embeds,
return_dict=False,
)[0]
# CFG引导
if self.do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
# 更新样本
latents = scheduler.step(noise_pred, t, latents, return_dict=False)[0]调度器步进函数
调度器的step函数实现了两种采样模式:
def step(self, model_output, timestep, sample, return_dict=True):
# 获取当前和下一个sigma
sigma_idx = self.step_index
current_sigma = self.sigmas[sigma_idx]
next_sigma = self.sigmas[sigma_idx + 1]
dt = next_sigma - current_sigma
if self.config.stochastic_sampling:
# 随机采样:估计起点并构造新路径
x0 = sample - current_sigma * model_output
noise = torch.randn_like(sample)
prev_sample = (1.0 - next_sigma) * x0 + next_sigma * noise
else:
# 确定性采样:欧拉方法
prev_sample = sample + dt * model_output
self._step_index += 1
return prev_sample确定性采样使用欧拉方法求解ODE:\(x_{t+\Delta t} = x_t + \Delta t \cdot v_t(x_t)\)
随机采样通过以下步骤引入随机性:
- 估计起点噪声:\(x_0 = x_t - \sigma_t \cdot v_t\)
- 生成新的随机噪声
- 从新路径采样:\(x_{t+\Delta t} = (1-\sigma_{t+\Delta t})x_0 + \sigma_{t+\Delta t}\cdot\text{noise}\)
这种设计让Flow Matching既可以确定性生成(保证质量),也可以随机生成(增加多样性)。
Rectified Flow 与 Optimal Transport (OT-CFM)
在 Flow Matching 的框架下,Rectified Flow (RF) 是最著名、最简单的一个具体实现。它的核心特征是强制规定从数据 \(x_0\) 到噪声 \(x_1 \sim \mathcal{N}(0, I)\) 的概率路径必须是最简单的直线:\(x_t = (1-t)x_0 + t x_1\)。
然而,在最初训练 RF 时(称为 1-Rectified Flow),由于噪声 \(x_1\) 和图像 \(x_0\) 是独立随机配对的,这会导致不同图像的生成轨迹在空间中发生严重交叉。一旦轨迹交叉,速度场就会变得极度非线性,ODE 求解器必须用非常小的步长(很多步)才能准确积分。
为了解决这个问题,原论文提出了一种叫做 Reflow 的迭代微调技术:
- 先用训练好的 1-RF 模型生成一批图像,记录下每个噪声 \(x_1\) 和它最终生成的图像 \(x_0\) 的确定性映射对。
- 用这些已经绑定好的数据对去训练一个新的模型(2-Rectified Flow)。 这个过程在数学上等价于在寻找最优传输(Optimal Transport)的解,能把交叉的轨迹彻底“拉直”成互不交叉的平行直线。轨迹越直,ODE 积分误差越小,最终甚至只需要 1 步 Euler 步进就能生成高质量图像。
工程实践中的演进(如 FLUX / SD3) 虽然理论上的 Reflow 很优美,但在工业界训练大模型时,先生成几十亿张图片再去训练 2-RF 的成本太高了。因此,当前最前沿的开源大模型(如 Stable Diffusion 3、FLUX)在实践中并没有使用多阶段的迭代 Reflow。
相反,它们在第一阶段训练(1-RF)时,直接在每个 Batch 内部使用最优传输(Optimal Transport, OT)算法对噪声和图像进行配对,这种方法被称为 OT-CFM (Optimal Transport Conditional Flow Matching)。通过在训练源头上强制让每个噪声点去寻找离它“最近”的真实图像,模型在单阶段训练中就能直接学到几乎不交叉的直线轨迹,从而实现极少步数的高质量生成。
总结与算法对比
算法对比:Flow Matching vs DDPM
- 路径:DDPM 的加噪路径是弯曲且充满随机性的(马尔可夫链),而 Flow Matching(特别是 Rectified Flow)的路径是两点之间的直线。
- 速度:因为直线路径更平滑,ODE 求解器可以用更大的步长(更少的步数)进行采样,这使得 Flow Matching 的生成速度远快于传统的 DDPM。
- 实现:Flow Matching 的 Loss 计算极其简单(预测速度与真实速度的 MSE),不需要像 DDPM 那样推导复杂的变分下界(ELBO)和各时间步的权重。
开源代码参考: 目前最前沿的开源图像大模型,如
Stable Diffusion 3 和
Flux,都已经全面抛弃了 DDPM,转而采用 Flow
Matching(Rectified Flow)作为其核心的生成机制。你可以在
diffusers 库的 FlowMatchEulerDiscreteScheduler
中看到其采样过程的实现。
参考资料:
- Lipman, Y., Chen, R. T., Ben-Hamu, H., Nickel, D. H., & Le, M. (2022). Flow Matching for Generative Modeling. ICLR 2023.
- 深入解析Flow Matching技术
- 【AI知识分享】你一定能听懂的扩散模型Flow Matching基本原理深度解析
- flow_matching
- Normalizing Flow