笔记|生成模型(八):SDE统一DDPM和SMLD
⬅️ 上一篇:笔记|生成模型(七):Score-Based理论
随机微分方程简介
首先介绍常微分方程和随机微分方程的基本知识,为后续讨论奠定基础。我们先从一个常微分方程(ODE)例子开始:
\[ \frac{\mathrm{d}x}{\mathrm{d}t}=f(x,t)\quad\mathrm{or}\quad\mathrm{d}x=f(x,t)\mathrm{d}t \]
其中 \(f(x,t)\) 是关于 \(x\) 和 \(t\) 的函数,描述了 \(x\) 随时间的变化趋势,如下图左侧所示。
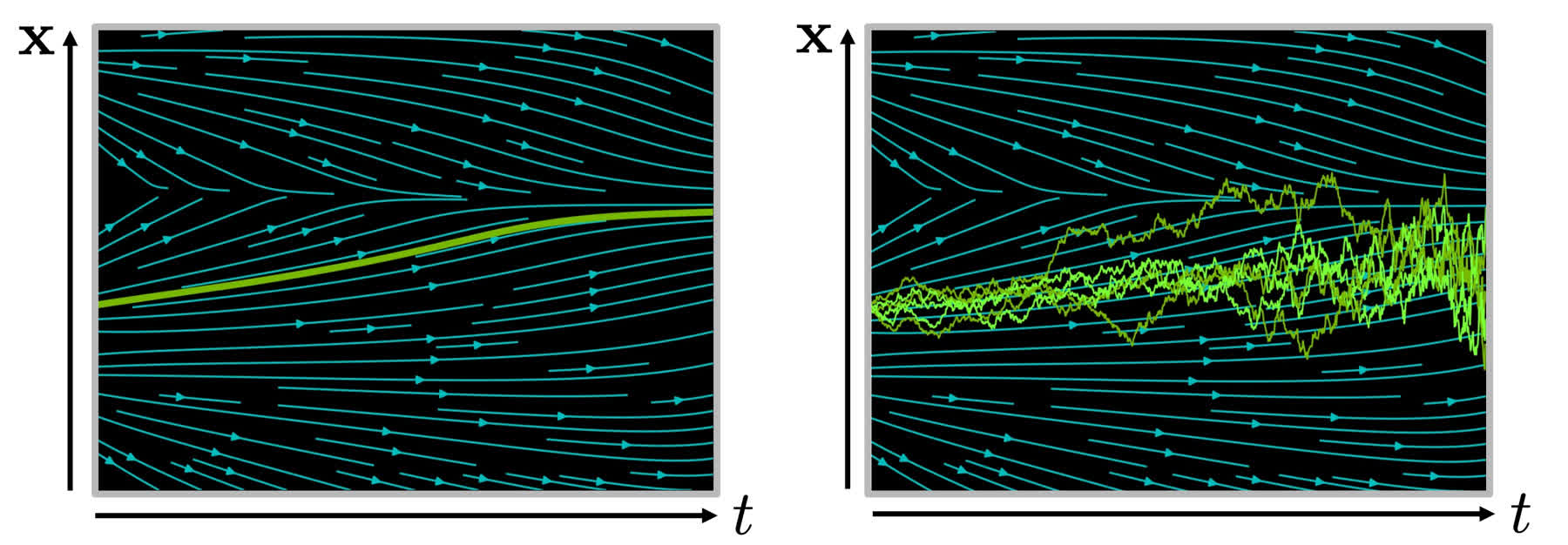
直观地讲,\(f(x,t)\) 对应于图中的青色箭头,确定某一时刻的 \(x(t)\) 后,沿着箭头方向可以找到下一时刻的 \(x(t+\Delta t)\)。这个常微分方程的解析解为:
\[ x(t)=x(0)+\int_0^t f(x,\tau)\mathrm{d}\tau \]
然而,实际应用中我们使用的 \(f(x,t)\) 通常是比较复杂的函数(如神经网络),求解析解往往不切实际。因此,通常采用迭代法求数值解:
\[ x(t+\Delta t)\approx x(t)+f(x(t),t)\Delta t \]
在迭代过程中,每次沿箭头方向线性移动一小段距离,经多次迭代得到解析解的近似,如上图左侧绿色曲线所示。
从上述描述可知,常微分方程描述了一个确定性过程。对于非确定性过程(如从分布中采样),则需要使用随机微分方程(SDE)描述。SDE 相比 ODE 形式上增加了一个高斯噪声项:
\[ \frac{\mathrm{d}x}{\mathrm{d}t}=\underbrace{f(x,t)}_{漂移系数}+\underbrace{\sigma(x,t)}_{扩散系数}\omega_t\quad\mathrm{or}\quad\mathrm{d}x=f(x,t)\mathrm{d}t+\sigma(x,t)\mathrm{d}\omega_t \]
采样时类似 ODE,可进行迭代采样:
\[ x(t+\Delta t)\approx x(t)+f(x(t),t)\Delta t+\sigma(x(t),t)\sqrt{\Delta t}\mathcal{N}(0,I) \]
由于采样过程中存在高斯噪声,多次采样会得到不同轨迹,如上图右侧的一系列绿色折线所示。
基于 SDE 的 Score-based Models
在上一篇文章中,我们介绍了基于分数的生成模型(Score-based Models)的基本思想:通过在不同噪声尺度下学习 Score Function,然后用朗之万动力学(Langevin MCMC)从噪声中逐步恢复数据。
但那里的噪声尺度是离散的有限个(\(\sigma_1, \sigma_2, \ldots, \sigma_L\)),步与步之间是突变的。一个自然的想法是:如果把噪声尺度推广到连续的无穷多个呢? 这就引出了 SDE 框架——用一个连续的随机微分方程来描述加噪过程。这种连续化带来了三个重要好处:更高质量的生成样本、精确的对数似然计算,以及统一 DDPM 和 SMLD 两大流派的理论视角。
使用 SDE 描述扰动过程
当离散的噪声尺度推广为连续时间后,扰动过程变成了一个连续时间的随机过程,如下图所示:
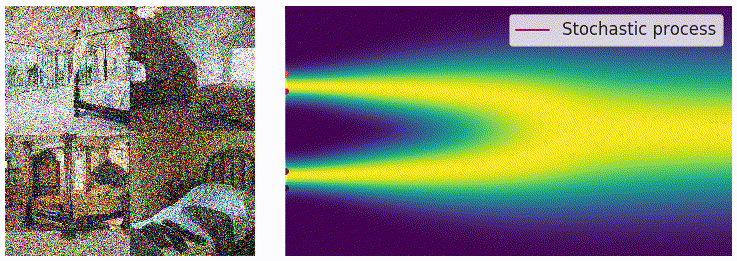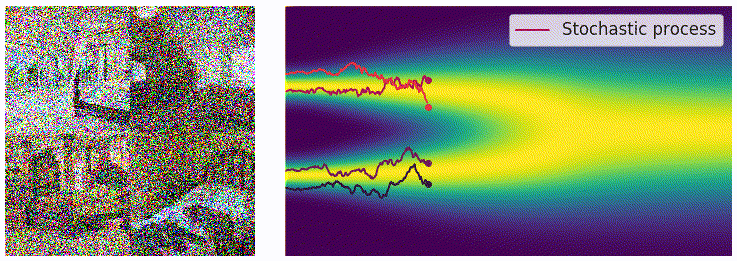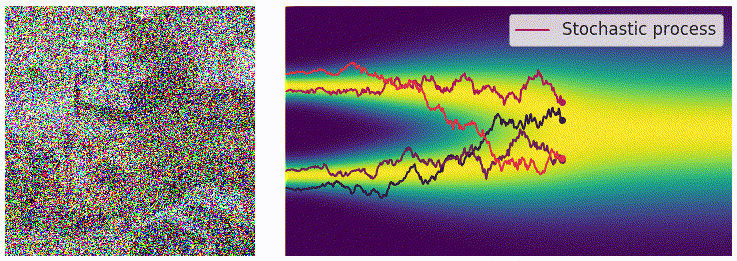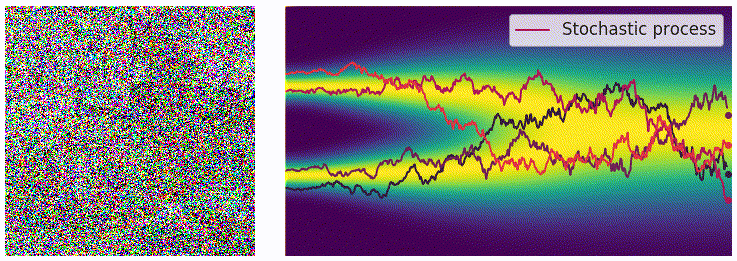
为表示上述随机过程,可用随机微分方程描述:
\[ \mathrm{d}x=f(x,t)\mathrm{d}t+g(t)\mathrm{d}w \]
用 \(p_t(x)\) 表示 \(x(t)\) 的概率密度函数,可知 \(p_0(x)=p(x)\) 是未加噪时的真实数据分布,经过足够多时间步 \(T\) 的扰动后,\(p_T(x)\) 接近先验分布 \(\pi(x)\)。从这一角度看,扰动过程与扩散模型的扩散过程本质上是一致的。
扰动随机过程可采用多种形式的 SDE,例如:
\[ \mathrm{d}x=e^t\mathrm{d}w \]
这表示用均值为 0、方差呈指数增长的高斯噪声对分布进行扰动。
使用反向 SDE 进行采样
正向过程用 SDE 描述加噪后,逆向过程(从噪声恢复数据)同样可以用一个 SDE 来表达。Anderson (1982) 证明了:对于前向 SDE
\[\mathrm{d}x = f(x,t)\mathrm{d}t + g(t)\mathrm{d}w\]
其逆向过程为:
\[ \mathrm{d}x=\left[f(x,t)-g^2(t){\color{green}\nabla_x\log p_t(x)}\right]\mathrm{d}t+g(t)\mathrm{d}\bar{w} \]
此处 \(\mathrm{d}t\) 表示反向时间方向(从 \(t=T\) 到 \(t=0\)),\(\mathrm{d}\bar{w}\) 是逆向布朗运动。
直觉理解:逆向 SDE 相比前向多出了绿色的 \(-g^2(t)\nabla_x\log p_t(x)\) 项——这就是 Score Function。在前向过程中,\(g(t)\mathrm{d}w\) 不断注入噪声让分布发散;在逆向过程中,Score 项扮演"纠偏力",将发散的分布重新拉回数据流形,实现从噪声到数据的生成。
简明推导:将前向 SDE 离散化后,\(x_{t+\Delta t} | x_t \sim \mathcal{N}(x_t + f\Delta t, \; g^2\Delta t \cdot I)\)。利用贝叶斯公式求逆向分布 \(p(x_t | x_{t+\Delta t})\),再对 \(\log p(x_t)\) 做一阶泰勒展开并配方,可以得到逆向分布的均值中自然出现 \(-g^2 \nabla_x \log p_t\) 项。当 \(\Delta t \to 0\) 时即得到上式。完整的离散化推导可参见笔记|强化学习(五):Flow-GRPO 中 Anderson 定理部分。
上式的核心启示是:无论前向 SDE 的形式如何,逆向过程的学习目标都归结为同一件事——用网络学习分布的 Score Function \(\nabla_x\log p_t(x)\)。
获得 score function 后,可从反向 SDE 中采样,最简单的方法是欧拉–丸山方法(Euler-Maruyama) 方法: \[ \begin{aligned} \Delta x &\leftarrow[f(x,t)-g^2(t)s_\theta(x,t)]\Delta t+g(t)\sqrt{|\Delta t|}z_t\\ x &\leftarrow x+\Delta x\\ t &\leftarrow t+\Delta t \end{aligned} \]
其中 \(z\sim\mathcal{N}(0,I)\),可通过直接对高斯噪声采样得到。上式中 \(f(x,t)\) 和 \(g(t)\) 均有解析形式,\(\Delta t\) 可选取较小值,仅 \(s_\theta(x,t)\) 为参数模型。采样过程可通过下图直观感受:
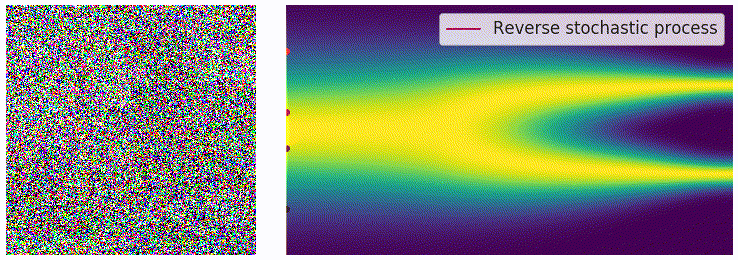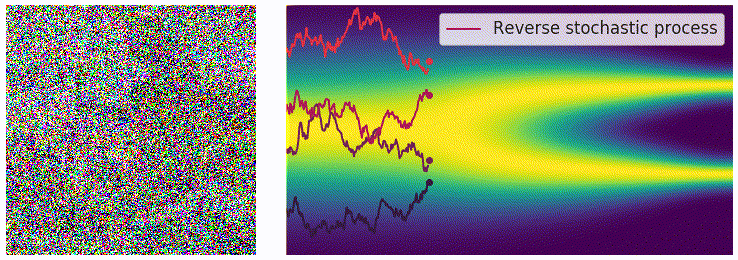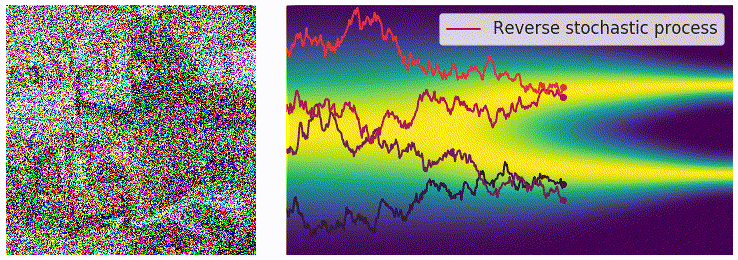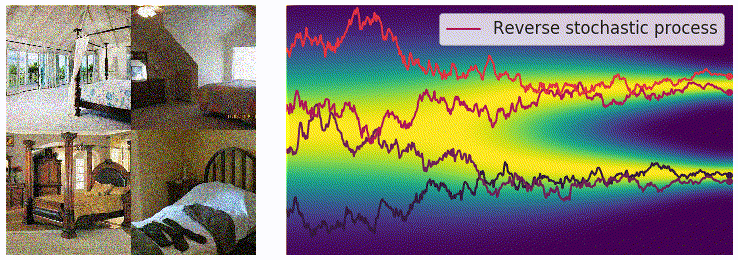
使用 score matching 进行训练
逆向采样的关键在于 Score Function \(\nabla_x\log p_t(x)\),我们需要用一个参数化网络 \(s_\theta(x,t)\) 来近似它。训练目标仍然是 score matching——让网络输出逼近真实 Score。
回顾离散情况(上篇文章),我们在有限个噪声尺度 \(\{\sigma_i\}\) 下分别计算 L2 损失并求和。连续化后,求和变为对时间 \(t\) 的积分(或等价地,取均匀时间分布 \(\mathcal{U}(0,T)\) 的期望):
\[ \mathbb{E}_{t\in\mathcal{U}(0,T)}\mathbb{E}_{p_t(x)}\left[\lambda(t)||\nabla_x\log p_t(x)-s_\theta(x,t)||_2^2\right] \]
其中权重函数 \(\lambda(t)\) 控制不同时刻的学习力度,通常取 \(\lambda(t)\propto 1/\mathbb{E}[\|\nabla_{x(t)}\log p(x(t)|x(0))\|_2^2]\),确保各时间步的梯度量级一致,避免某些时刻的损失主导整个优化过程。
值得讨论的是,在离散情况下,\(\lambda(t)\) 的选取为 \(\lambda(t)=\sigma_t^2\)。若此处也使用类似形式 \(\lambda(t)=g^2(t)\),可推导出 \(p_0(x)\) 和 \(p_\theta(x)\) 之间的 KL 散度与上述损失间的关系:
\[ \mathrm{KL}(p_0(x)||p_\theta(x))\le\frac{T}{2}\mathbb{E}_{t\in\mathcal{U}(0,T)}\mathbb{E}_{p_t(x)}\left[\lambda(t)||\nabla_x\log p_t(x)-s_\theta(x,t)||_2^2\right]+\mathrm{KL}(p_T||\pi) \]
这个不等式的直觉:左侧是我们关心的"生成分布与真实分布之间的差距";右侧第一项是 score matching 损失(用 \(g^2(t)\) 加权),第二项是先验分布的近似误差(通常可忽略)。也就是说,只要 Score 学得足够准,生成的分布就会逼近真实分布。权重 \(\lambda(t) = g^2(t)\) 被称为 likelihood weighting function——它让模型在噪声较大的时间步投入更多学习精力,因为那些时刻的 Score 更难估计。
Score 的另一种计算方式:去噪即 Score
除了用独立网络 \(s_\theta(x,t)\) 直接拟合 Score,还有一种更优雅的方式——从去噪模型中反推 Score。
如果模型学会了从噪声图 \(x_t\) 预测干净数据 \(\hat{x}_0\)(即去噪任务),那么通过 Tweedie 公式,可以直接从预测结果算出 Score:
\[\nabla_{x_t}\log p(x_t | x_0) = -\frac{x_t - \hat{\mu}_t}{\sigma_t^2}\]
其中 \(\hat{\mu}_t\) 由模型预测的 \(\hat{x}_0\) 确定。这意味着去噪模型天然就包含了 Score 信息,不需要单独的 Score 网络。这一思路在后续的 Flow Matching 和 Flow-GRPO 中被广泛使用——速度场模型 \(v_\theta\) 可以反推 \(\hat{x}_0\),进而获得 Score(详见笔记|强化学习(五):Flow-GRPO 中 Tweedie 公式推导)。
讨论
到这里,我们已经建立了完整的 SDE-based 生成模型框架:用前向 SDE 描述加噪、用反向 SDE + Score Function 进行采样、用 Score Matching 训练模型。一个自然的问题是:这个框架与之前学过的模型有什么关系? 下面从三个角度展开:
- 与 DDPM 的联系:SDE 框架是 DDPM 的连续极限推广
- SDE 与 ODE 的等价转换:同一个生成过程可以有确定性和随机性两种描述
- 条件生成:SDE 框架如何自然地支持条件生成
和 DDPM 的联系
通过上文介绍,我们发现用 SDE 描述的 score-based model 与扩散模型有许多相似之处。在 DDPM 中,前向过程描述为:
\[ x_{t}=\sqrt{1-\beta_t}x_{t-1}+\sqrt{\beta_t}\epsilon_{t-1},\quad\epsilon_{t-1}\sim\mathcal{N}(0,I) \]
这是一个离散过程,\(t\in\{0,1,\cdots,T\}\)。为将 DDPM 转变为连续形式,可将所有时间步除以 \(T\),即 \(t\in\{0,\frac{1}{T},\cdots,\frac{T-1}{T},1\}\)。当 \(T\rightarrow\infty\),DDPM 变为连续过程。代入上式:
\[ x(t+\Delta t)=\sqrt{1-\beta(t+\Delta t)\Delta t}~x(t)+\sqrt{\beta(t+\Delta t)\Delta t}~\epsilon(t) \]
泰勒展开后近似得到:
\[ \begin{aligned} x(t+\Delta t)&=\sqrt{1-\beta(t+\Delta t)\Delta t}~x(t)+\sqrt{\beta(t+\Delta t)\Delta t}~\epsilon(t)\\ &\approx x(t)-\frac{1}{2}\beta(t+\Delta t)\Delta t~x(t)+\sqrt{\beta(t+\Delta t)\Delta t}~\epsilon(t)\\ &\approx x(t)-\frac{1}{2}\beta(t)\Delta t x(t)+\sqrt{\beta(t)\Delta t}\epsilon(t) \end{aligned} \]
当 \(T\rightarrow\infty\),即 \(\Delta t\rightarrow0\) 时,有:
\[ \mathrm{d}x=-\frac{\beta(t)x}{2}\mathrm{d}t+\sqrt{\beta(t)}\mathrm{d}w \]
推导表明,从 DDPM 前向过程出发,可得到与 score-based model 形式相符的 SDE 方程,因此也可使用 score matching、Langevin MCMC 等策略进行学习和采样。详细推导可参见 Score-Based Generative Modeling through Stochastic Differential Equations 附录 B。
SDE 与 ODE 的等价转换
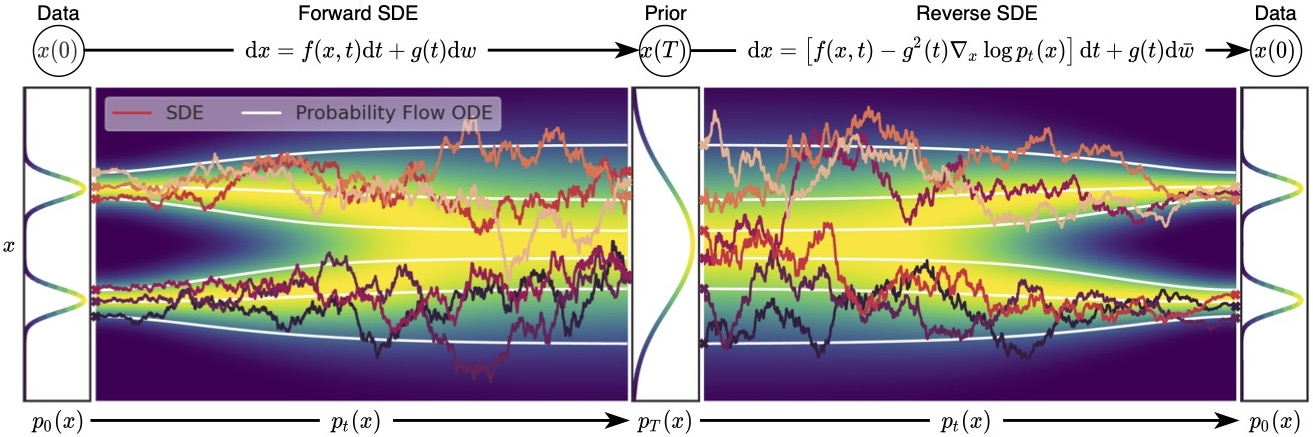
SDE 和 ODE 之间存在一个深刻的对偶关系:对于同一个数据生成过程,存在一个 SDE 和一个 ODE,它们在每个时刻 \(t\) 的边缘分布 \(p_t(x)\) 完全相同,但轨迹不同。
SDE → ODE(去掉随机性)
对于反向 SDE:
\[\mathrm{d}x = [f(x,t) - g^2(t)\nabla_x\log p_t(x)]\mathrm{d}t + g(t)\mathrm{d}\bar{w}\]
如果去掉噪声项 \(g(t)\mathrm{d}\bar{w}\),并将 Score 系数从 \(g^2\) 减半为 \(\frac{1}{2}g^2\),就得到与之边缘分布相同的 ODE(称为 Probability Flow ODE):
\[\mathrm{d}x = \left[f(x,t) - \frac{1}{2}g^2(t)\nabla_x\log p_t(x)\right]\mathrm{d}t\]
直觉理解:在 SDE 中,噪声 \(g\mathrm{d}\bar{w}\) 让分布扩散,而 \(-g^2 \cdot \text{Score}\) 把扩散拉回来,两者相互抵消后的"净效果"等价于 \(-\frac{1}{2}g^2 \cdot \text{Score}\) 的确定性修正。ODE 直接用这个净效果来移动粒子,不需要噪声。
由于 ODE 是确定性的,前向和反向过程都可逆,因此可精确计算 log-likelihood(类似 DDPM 和 DDIM 的关系),并与 normalizing flow 有相似之处。
ODE → SDE(注入随机性)
反过来,如果我们已经有一个 ODE(如 Flow Matching 中学到的速度场 \(v_\theta\)),也可以将其转换为 SDE——在 ODE 的基础上注入噪声 \(g(t)\mathrm{d}\bar{w}\),同时添加 Score 修正 \(-\frac{1}{2}g^2 \nabla_x\log p_t\) 来抵消噪声带来的分布偏移:
\[\mathrm{d}x = \left[v_\theta(x,t) - \frac{1}{2}g^2(t)\nabla_x\log p_t(x)\right]\mathrm{d}t + g(t)\mathrm{d}\bar{w}\]
这种 ODE→SDE 转换在后续的 Flow-GRPO 框架中至关重要——它让确定性的 Flow Matching 模型获得了随机采样能力,为强化学习的"探索"提供了基础(详见笔记|强化学习(五):Flow-GRPO)。
两者关系如下图所示,ODE 概率流比 SDE 更平滑,但两者最终得到的分布相同:
条件生成
生成模型的一个常见需求是条件生成:不是随机生成图像,而是在给定条件 \(y\)(如类别标签、文本描述)下生成特定的 \(x\)。在 DDPM 框架中,条件生成需要额外的技巧(如 Classifier Guidance),无法从理论上直接推导。而 SDE 框架提供了一个优雅的显式解法。
核心思路:利用贝叶斯公式将条件分布的 Score 分解为两部分。从贝叶斯公式出发:
\[ p(x|y)=\frac{p(x)p(y|x)}{\int p(x)p(y|x)\mathrm{d}x} \]
两侧取对数再对 \(x\) 求梯度(分母是关于 \(x\) 的积分常数,梯度为零),得到:
\[ \underbrace{\nabla_x\log p(x|y)}_{\text{条件 Score}} = \underbrace{\nabla_x\log p(x)}_{\text{无条件 Score}} + \underbrace{\nabla_x\log p(y|x)}_{\text{似然梯度}} \]
这个分解告诉我们:条件生成的 Score = 无条件 Score + 似然的梯度方向修正。
- 第一项 \(\nabla_x\log p(x)\):就是我们已经用 score matching 学好的无条件 Score 网络
- 第二项 \(\nabla_x\log p(y|x)\):在已知条件 \(y\) 和当前样本 \(x\) 的情况下,似然 \(p(y|x)\) 的梯度指向"让 \(x\) 更符合条件 \(y\)"的方向
两者结合后代入反向 SDE,即可实现条件生成。这一分解思路直接启发了后续的 Classifier Guidance 方法(详见下一篇文章)。
总结
本文将离散的 Score-based Models 推广为连续的 SDE 框架,核心结论可归纳为以下几点:
- 统一描述:前向加噪 = SDE,逆向生成 = 反向 SDE + Score Function。通过指定不同的 \(f(x,t)\) 和 \(g(t)\),可以统一 DDPM 和 SMLD 两大流派。
- SDE ↔︎ ODE 对偶:同一个生成过程既可以用 SDE(随机采样)表示,也可以用 Probability Flow ODE(确定性采样)表示,两者共享相同的边缘分布 \(p_t(x)\)。反过来,ODE 也可以通过注入噪声 + Score 修正转化为 SDE,这一思路在后续 Flow-GRPO 中被广泛使用。
- 去噪即 Score:通过 Tweedie 公式,去噪模型天然包含了 Score 信息,不需要单独训练 Score 网络。
- 条件生成:贝叶斯分解使条件 Score = 无条件 Score + 似然梯度,直接启发了 Classifier Guidance。
SDE 是一个强大的统一框架——它不仅连接了已有的生成模型流派,也为后续的 Flow Matching、Classifier-Free Guidance 等方法提供了理论基础。
参考资料:
- Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., & Poole, B. (2020). Score-Based Generative Modeling through Stochastic Differential Equations. ICLR 2021.
- Anderson, B. D. O. (1982). Reverse-time diffusion equation models. Stochastic Processes and their Applications, 12(3), 313-326.
- Generative Modeling by Estimating Gradients of the Data Distribution
- CVPR 2022 Tutorial: Denoising Diffusion-based Generative Modeling: Foundations and Applications
- 一文解释 Diffusion Model (二) Score-based SDE 理论推导
- 基于 SDE 的模型