笔记|强化学习(三):大模型对齐的另一条路:DPO (Direct Preference Optimization)
本文为系列第三篇。在上一篇中,我们提到 PPO 算法虽然稳定,但在百亿参数大模型微调时面临着极大的显存压力(需要同时维护 Actor 和 Critic 模型)。为了解决这一痛点,斯坦福大学在 2023 年提出了一条完全不同于在线 RL 的路线——DPO。本文将简要介绍 DPO 算法,作为后续回归 RL 路线(GRPO)的对比铺垫。
PPO 的繁琐与显存危机:大模型吃不消了
先看例子:假设我们要用 RLHF 微调一个大模型,让它学会写出更好的代码。传统流程分三步:
- SFT:用大量代码问答数据做监督微调——教模型"怎么写代码"。
- RM:给同一道编程题生成两份代码(A 和 B),让人类标注哪份更好,训练一个"代码评审员"(奖励模型)。
- RL:让模型自己去写代码,"评审员"给分,模型根据分数用 PPO 算法调整自己。
这个流程极其繁琐,且在 PPO 阶段,显存中需要同时驻留四个庞大的模型:
- Actor 模型(正在训练的策略网络,即写代码的学生)
- Critic 模型(价值网络,通常与 Actor 同等规模,估计代码题的"难度")
- Reference 模型(冻结的 SFT 模型,防止学生学偏)
- Reward 模型(冻结的奖励模型,即代码评审员)
四个大模型同台竞技,显存开销令人绝望。对于百亿参数(10B+)的模型,普通实验室根本玩不起。
DPO:绕过奖励模型与 RL
核心思考出发点:既然我们的最终目的是让模型符合人类偏好(生成好答案的概率大于坏答案),我们为什么非要绕个大弯子,先训练一个"评审员",再用 PPO 去教学生呢?能不能直接把"人类偏好"喂给学生,让他直接学?
用一个具体例子理解 DPO 的想法:
假设用户问:"用 Python 写一个排序函数。" 模型生成了两个回答:
| 回答 \(y_w\)(胜者) | 回答 \(y_l\)(败者) | |
|---|---|---|
| 代码 | def sort(arr): return sorted(arr) |
def sort(arr): arr.sort(); return arr |
| 人类评价 | 更好(纯函数,无副作用) | 较差(修改了原数组) |
在 PPO 流程中,你需要先训练一个奖励模型来给两个回答打分(比如 \(r(y_w) = 0.8\), \(r(y_l) = 0.3\)),然后再用 PPO 去优化策略。
DPO 的做法:跳过奖励模型,直接告诉语言模型——"\(y_w\) 比 \(y_l\) 好,请调整你的参数,让 \(y_w\) 的生成概率相对增大,\(y_l\) 的相对减小。" 整个过程变成了一个简单的监督学习问题。
意义:DPO 将复杂的强化学习问题,巧妙地转化为了一个监督学习分类问题——不需要奖励模型,不需要 Critic,不需要 PPO 采样。只需要 Actor 模型和一个冻结的 Reference 模型即可。
DPO 的数学推导
完整推导
推导目的:证明下面这个纯监督损失函数(只需偏好对 + 前向传播)的最优解,恰好等价于 RLHF 的 KL 约束奖励最大化的最优解——不需要奖励模型、不需要在线 RL,就能达到与 PPO 相同的理论最优策略。
为什么能推导:KL 约束 + 线性奖励的特殊结构使得最优策略有 Boltzmann 形式的闭式解(统计力学 / 变分推断中早已知晓)。DPO 的关键洞察是:Bradley-Terry 偏好模型只关心奖励之差,做差时不可计算的配分函数 \(Z(x)\) 自动消去,使最终损失只依赖于策略概率比——完全不含 \(r\)。
为什么之前不用:闭式解 \(\pi^*=\frac{1}{Z}\pi_{\text{ref}}e^{r/\beta}\) 早已知晓,但直接计算它需要先有 \(r\)(训练奖励模型)和 \(Z\)(不可计算)——所以之前仍走 PPO 路线。DPO (2023) 发现 BT 配对比较让 \(r\) 和 \(Z\) 同时消去,使得无需显式学习奖励就能直接优化策略。
约定:\(\pi\) 为策略,\(\pi_{\text{ref}}\) 为冻结参考策略,\(r(x,y)\) 为奖励,\(\beta>0\) 为 KL 系数,\(Z(x)=\sum_y \pi_{\text{ref}}(y|x)\exp\!\bigl(r(x,y)/\beta\bigr)\)。
\[ \max_{\pi}\; \mathbb{E}_{x,\,y\sim\pi}\!\left[ r(x,y) - \beta \log \frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)} \right] \]
\(\Longrightarrow\) 除以 \(\beta\),变号:
\[ \min_{\pi}\; \mathbb{E}_{y\sim\pi}\!\left[ \log \frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)\exp\!\bigl(r(x,y)/\beta\bigr)} \right] \]
\(\Longrightarrow\) 分母除以 \(Z(x)\) 归一化,定义 \(\pi^*(y|x)\triangleq\frac{1}{Z(x)}\pi_{\text{ref}}(y|x)\exp\!\bigl(r(x,y)/\beta\bigr)\):
\[ \min_{\pi}\; D_{\text{KL}}(\pi \| \pi^*) - \log Z(x) \]
\(\Longrightarrow\) \(D_{\text{KL}}\geq 0\),取等当且仅当 \(\pi=\pi^*\),故最优策略为:
\[ \pi^*(y|x) = \frac{1}{Z(x)}\,\pi_{\text{ref}}(y|x)\,\exp\!\left(\frac{r(x,y)}{\beta}\right) \]
\(\Longrightarrow\) 两边取 \(\log\),解出 \(r\):
\[ r(x,y) = \beta\log\frac{\pi^*(y|x)}{\pi_{\text{ref}}(y|x)} + \beta\log Z(x) \]
\(\Longrightarrow\) 代入 Bradley-Terry 模型 \(p(y_w\!\succ\!y_l|x)=\sigma(r_w-r_l)\),做差消去 \(\beta\log Z(x)\):
\[ p(y_w\!\succ\!y_l|x) = \sigma\!\left(\beta\log\frac{\pi^*(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta\log\frac{\pi^*(y_l|x)}{\pi_{\text{ref}}(y_l|x)}\right) \]
\(\Longrightarrow\) 若要直接计算 \(\pi^*\) 就必须先有显式的 \(r\)(回到 PPO 路线),但上式已不含 \(r\)——只有策略概率比。因此用可训练的 \(\pi_\theta\) 替代 \(\pi^*\),构造负对数似然作为损失(最小值恰在 \(\pi_\theta=\pi^*\) 时取到),完全绕过奖励模型:
\[ \boxed{\;\mathcal{L}_{\text{DPO}}(\theta) = -\mathbb{E}_{(x,y_w,y_l)}\!\left[\log\sigma\!\left(\beta\log\frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta\log\frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)}\right)\right]\;} \]
梯度:
\[ \nabla_\theta\mathcal{L} = -\beta\,\mathbb{E}\!\left[\sigma(-\hat{r}_\theta)\left(\nabla_\theta\log\pi_\theta(y_w|x) - \nabla_\theta\log\pi_\theta(y_l|x)\right)\right] \]
其中 \(\hat{r}_\theta = \beta\left(\log\frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \log\frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)}\right)\),权重 \(\sigma(-\hat{r}_\theta)\) 自动聚焦于未学好的样本。
分步详解
先看例子:在推导之前,先用直觉理解 DPO 损失函数的含义。
对于上面的排序函数例子,DPO 损失函数内部的核心量是隐式奖励边距(implicit reward margin)——直白地说,就是模型区分好坏答案的"信心分数":
\[\hat{r}_\theta(x, y_w) - \hat{r}_\theta(x, y_l) = \beta \left( \log \frac{\pi_\theta(y_w|x)}{\pi_\text{ref}(y_w|x)} - \log \frac{\pi_\theta(y_l|x)}{\pi_\text{ref}(y_l|x)} \right)\]
其中 \(\hat{r}_\theta(x, y) = \beta \log \frac{\pi_\theta(y|x)}{\pi_\text{ref}(y|x)}\) 是由当前策略 \(\pi_\theta\) 和参考策略 \(\pi_\text{ref}\) 隐式定义的奖励函数(原论文称 the reward implicitly defined by the language model)。
拆开来看:
- \(\hat{r}_\theta(x, y_w) = \beta \log \frac{\pi_\theta(y_w|x)}{\pi_\text{ref}(y_w|x)}\):当前模型相比参考模型,有多"偏爱"好答案 \(y_w\)(即好答案的隐式奖励)。
- \(\hat{r}_\theta(x, y_l) = \beta \log \frac{\pi_\theta(y_l|x)}{\pi_\text{ref}(y_l|x)}\):当前模型相比参考模型,有多"偏爱"坏答案 \(y_l\)(即坏答案的隐式奖励)。
- 两者之差(边距)越大,说明模型越能区分好坏——DPO 的目标就是最大化这个边距。
注意:隐式奖励边距本身不是损失函数。完整的 DPO 损失函数还在边距外面套了 \(-\log\sigma(\cdot)\),即 \(\mathcal{L}_\text{DPO} = -\mathbb{E}[\log\sigma(\hat{r}_\theta(x, y_w) - \hat{r}_\theta(x, y_l))]\)。这里先建立直觉,后面会完整推导。
假设训练前,当前模型就是参考模型(\(\pi_\theta = \pi_\text{ref}\)),那么两个隐式奖励都是 0,边距也是 0——模型还没学会区分好坏。训练之后,模型应该增大 \(\pi_\theta(y_w|x)\)、减小 \(\pi_\theta(y_l|x)\),使边距变大。
一般化的数学推导:
Step 1:RLHF 的 KL 约束优化目标
在传统的 RLHF 中(上一篇 PPO 的四模型架构),我们的目标可以用一句话概括:让模型回答得尽量好,但又不能跑偏太远。记 \(x\) 为用户问题(Prompt),\(y\) 为模型回答(Response),\(\pi(y|x)\) 为当前正在训练的策略,\(\pi_{\text{ref}}(y|x)\) 为冻结的参考模型(SFT 模型,用来"拴住"当前模型防止学偏),\(r(x,y)\) 为奖励函数,\(\beta\) 为 KL 惩罚系数(越大约束越强)。数学上写成:
\[ \max_{\pi} \underbrace{\mathbb{E}_{x \sim \mathcal{D}, y \sim \pi} \left[ r(x, y) \right]}_{\text{让回答质量尽量高}} - \underbrace{\beta \cdot D_{\text{KL}}(\pi \| \pi_{\text{ref}})}_{\text{别偏离参考模型太远}} \]
第一项好理解:从训练集 \(\mathcal{D}\) 中随机抽一道题 \(x\),让当前模型 \(\pi\) 生成回答 \(y\),用奖励函数 \(r(x,y)\) 打分,希望期望分数越高越好。
第二项是"缰绳":\(D_{\text{KL}}(\pi \| \pi_{\text{ref}})\) 衡量当前模型 \(\pi\) 和参考模型 \(\pi_{\text{ref}}\) 之间的"距离"。如果没有这条缰绳,模型为了拿高分会走捷径——比如对所有问题都输出同一个高分模板答案,完全丧失通用能力(这叫 reward hacking,奖励欺骗)。\(\beta\) 就是缰绳的松紧度:\(\beta\) 越大,缰绳越紧,模型越保守。
现在把 KL 散度展开。KL 散度的定义是:
\[ D_{\text{KL}}(\pi \| \pi_{\text{ref}}) = \mathbb{E}_{y \sim \pi(\cdot|x)} \left[ \log \frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)} \right] \]
直觉上,\(\log \frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)}\) 衡量的是:对于某个具体回答 \(y\),当前模型 \(\pi\) 给它的概率相比参考模型 \(\pi_{\text{ref}}\) 偏高了多少。如果 \(\pi\) 给某个回答的概率是 \(\pi_{\text{ref}}\) 的 10 倍,这项就是 \(\log 10 \approx 2.3\),说明模型在这个回答上"跑偏"了很多。KL 散度就是这个"跑偏程度"在所有可能回答上的期望值。
代入优化目标:
\[ \max_{\pi} \underbrace{\mathbb{E}_{x \sim \mathcal{D}, y \sim \pi} \left[ r(x, y) \right]}_{\text{第一项:期望奖励}} - \beta \cdot \underbrace{\mathbb{E}_{x \sim \mathcal{D}, y \sim \pi} \left[ \log \frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)} \right]}_{\text{第二项:KL 散度展开后}} \]
由于两项的期望都在同一分布 \(x \sim \mathcal{D}, y \sim \pi\) 下,根据期望的线性性(\(\mathbb{E}[A] - \beta \mathbb{E}[B] = \mathbb{E}[A - \beta B]\)),可以合并为一个期望:
\[ \max_{\pi} \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi} \left[ \underbrace{r(x, y)}_{\text{奖励}} - \underbrace{\beta \log \frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)}}_{\text{跑偏惩罚}} \right] \]
直觉上:对于每一个具体的回答 \(y\),模型获得的"净收益"= 奖励 \(r(x,y)\) 减去跑偏惩罚。模型需要在"拿高分"和"别跑偏"之间做平衡。
这正是上一篇 RLHF-PPO 中的奖励修正公式。PPO 用在线采样 + 裁剪来近似求解这个问题。DPO 的出发点是:这个问题是否有解析解(闭式解)?
Step 2:推导最优策略的闭式解
接下来我们从上面的目标函数出发,通过纯代数变换,一步步自然推出最优策略的形式。
Step 2.1:变号——从 max 到 min
上面的目标是:
\[ \max_{\pi} \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi} \left[ r(x, y) - \beta \log \frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)} \right] \]
为什么要变号? 我们接下来的目标是把这个式子凑成 KL 散度的形式(为什么?下一步 Step 2.2 会详细解释动机)。而 KL 散度的标准形式 \(\mathbb{E}\left[\log \frac{P}{Q}\right]\) 天然是一个最小化问题,所以我们先把 max 转成 min。
具体做法:固定一个 Prompt \(x\),只看内层关于 \(y\) 的优化。先除以 \(\beta\)(\(\beta > 0\),除正数不改变 \(\max\) 方向),再取反(\(\max\) 变 \(\min\)):
\[ \min_{\pi} \mathbb{E}_{y \sim \pi(y|x)} \left[ \underbrace{\log \frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)}}_{\text{跑偏程度}} - \underbrace{\frac{1}{\beta} r(x, y)}_{\text{缩放后的奖励}} \right] \]
现在的含义很清晰:我们要找一个策略 \(\pi\),使得"跑偏程度减去奖励收益"尽量小——即在尽量不跑偏的前提下,尽量拿高奖励。
Step 2.2:合并对数——把两项塞进一个 log 分数
为什么要凑成 KL 散度的形式? 因为 KL 散度有一个非常"好用"的性质:
\[ D_{\text{KL}}(P \| Q) \geq 0, \quad \text{当且仅当 } P = Q \text{ 时取等号} \]
如果我们能把优化目标写成 \(\min_\pi D_{\text{KL}}(\pi \| \text{某个分布})\) 的形式,那最优解就可以直接读出来——\(\pi\) 就等于那个分布!不需要梯度下降,不需要 PPO 采样,不需要任何迭代优化——这就是所谓的闭式解(解析解),也正是 DPO 追求的目标。
所以接下来的几步,我们的唯一目的就是:把优化目标凑成 KL 散度的标准形式 \(\mathbb{E}_P\left[\log \frac{P}{Q}\right]\)。
目前上式有两项(log 比值 - 奖励),如果能合并成一个 \(\log \frac{\text{分子}}{\text{分母}}\) 的形式,就离 KL 散度只差一步了。
技巧:把 \(\frac{1}{\beta} r(x,y)\) 也变成 log 形式。利用恒等式 \(a = \log e^a\)(取指数再取对数,值不变):
\[ \frac{1}{\beta} r(x,y) = \log \exp\left(\frac{1}{\beta} r(x,y)\right) \]
两项都是 log 了,就可以用 \(\log A - \log B = \log \frac{A}{B}\) 合并:
\[ \log \frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)} - \log \exp\left(\frac{1}{\beta} r(x, y)\right) = \log \frac{\pi(y|x)}{\pi_{\text{ref}}(y|x) \cdot \exp\left(\frac{1}{\beta} r(x, y)\right)} \]
优化目标变为:
\[ \min_{\pi} \mathbb{E}_{y \sim \pi(y|x)} \left[ \log \frac{\pi(y|x)}{\underbrace{\pi_{\text{ref}}(y|x) \cdot \exp\left(\frac{1}{\beta} r(x, y)\right)}_{\text{一个和 } \pi \text{ 无关的量}}} \right] \]
这已经非常像 KL 散度了!KL 散度的形式是 \(\mathbb{E}_{P}\left[\log \frac{P}{Q}\right]\)——分子是 \(\pi\)(采样分布),分母如果也是一个合法的概率分布,那这就是 KL 散度了。
Step 2.3:引入配分函数 \(Z(x)\)——让分母成为合法概率分布
现在的问题:分母 \(\pi_{\text{ref}}(y|x) \cdot \exp\left(\frac{1}{\beta} r(x, y)\right)\) 虽然对每个 \(y\) 都是正数,但它对所有 \(y\) 求和未必等于 1——也就是说,它还不是一个合法的概率分布,我们还不能直接说这是 KL 散度。
解决办法:给它做归一化,就像把一组正数除以它们的总和变成概率一样。这个总和就叫配分函数(Partition Function):
\[ Z(x) = \sum_{y} \pi_{\text{ref}}(y|x) \exp\left(\frac{1}{\beta} r(x, y)\right) \]
\(Z(x)\) 的含义:它是参考模型 \(\pi_{\text{ref}}\) 对所有可能回答的"奖励加权总和"。注意它只跟固定的 \(x\)、\(r\)、\(\pi_{\text{ref}}\) 有关,与我们要优化的 \(\pi\) 完全无关——这一点后面至关重要。
为了把 \(Z(x)\) 引入分母做归一化,我们在分母上乘以 \(\frac{Z(x)}{Z(x)} = 1\)(数值不变,纯粹是数学等价变换)。相应地,多出来的 \(Z(x)\) 项从 log 里提出来变成 \(-\log Z(x)\):
\[ \min_{\pi} \mathbb{E}_{y \sim \pi(y|x)} \left[ \log \frac{\pi(y|x)}{\frac{1}{Z(x)} \pi_{\text{ref}}(y|x) \exp\left(\frac{1}{\beta} r(x, y)\right)} - \log Z(x) \right] \]
这步的数学细节:原本分母是 \(A\),乘上 \(\frac{Z}{Z}\) 后分母变成 \(\frac{A}{Z} \cdot Z\)。log 里提出 \(Z\):\(\log \frac{\pi}{\frac{A}{Z} \cdot Z} = \log \frac{\pi}{\frac{A}{Z}} - \log Z\)。
Step 2.4:定义 \(\pi^*\)——最优策略自然浮现
现在看分母里的 \(\frac{1}{Z(x)} \pi_{\text{ref}}(y|x) \exp\left(\frac{1}{\beta} r(x, y)\right)\):
- 每个 \(y\) 对应的值都 \(> 0\)(概率和指数函数都是正数)。
- 对所有 \(y\) 求和恰好等于 1(因为 \(Z(x)\) 就是按这个定义的)。
所以它就是一个合法的概率分布! 我们给它一个名字 \(\pi^*\):
\[ \pi^*(y|x) \triangleq \frac{1}{Z(x)} \pi_{\text{ref}}(y|x) \exp\left(\frac{1}{\beta} r(x, y)\right) \]
代入优化目标,第一项就变成了标准的 KL 散度形式 \(\mathbb{E}_{\pi}\left[\log \frac{\pi}{\pi^*}\right] = D_{\text{KL}}(\pi \| \pi^*)\):
\[ \min_{\pi} \left[ \underbrace{D_{\text{KL}}(\pi \| \pi^*)}_{\geq 0, \text{ 当 } \pi = \pi^* \text{ 时}= 0} - \underbrace{\log Z(x)}_{\text{与 } \pi \text{ 无关的常数}} \right] \]
Step 2.5:得出结论
\(\log Z(x)\) 与 \(\pi\) 无关,在 \(\min_\pi\) 中是常数,可以忽略。所以最小化上式等价于最小化 \(D_{\text{KL}}(\pi \| \pi^*)\)。
KL 散度有一个关键性质:\(D_{\text{KL}}(\pi \| \pi^*) \geq 0\),当且仅当 \(\pi = \pi^*\) 时取到最小值 0。
因此,最优策略就是 \(\pi^*\):
\[ \boxed{\pi^*(y|x) = \frac{1}{Z(x)} \pi_{\text{ref}}(y|x) \exp\left(\frac{r(x, y)}{\beta}\right)} \]
\(\pi^*\) 不是我们凭空猜的,而是从目标函数经过代数变换自然推导出来的。
用例子理解 \(\pi^*\) 的含义:回到文章开头的排序函数例子(\(x\) = "用 Python 写一个排序函数"),假设参考模型 \(\pi_{\text{ref}}\) 对这个问题有三种可能回答:
- 纯函数版:
def sort(arr): return sorted(arr)(不修改原数组,文章开头的 \(y_w\)) - 副作用版:
def sort(arr): arr.sort(); return arr(修改了原数组,文章开头的 \(y_l\)) - 报错版:
def sort(arr): return arr.srot()(拼写错误,直接报错)
我们取 \(\beta = 1\)(缰绳较松),逐步计算最优策略 \(\pi^*\):
| 回答 \(y\) | \(\pi_{\text{ref}}(y\|x)\) | \(r(x,y)\) | \(\exp(r/\beta)\)(放大倍数) | \(\pi_{\text{ref}} \cdot \exp(r/\beta)\)(加权后) | \(\pi^*(y\|x)\)(归一化) |
|---|---|---|---|---|---|
| 纯函数版 | 0.3 | 2.0 | \(e^2 = 7.39\) | \(0.3 \times 7.39 = 2.22\) | \(2.22 / 3.11 =\) 0.71 |
| 副作用版 | 0.5 | 0.5 | \(e^{0.5} = 1.65\) | \(0.5 \times 1.65 = 0.82\) | \(0.82 / 3.11 = 0.26\) |
| 报错版 | 0.2 | -1.0 | \(e^{-1} = 0.37\) | \(0.2 \times 0.37 = 0.07\) | \(0.07 / 3.11 = 0.02\) |
其中 \(Z(x) = 2.22 + 0.82 + 0.07 = 3.11\)(配分函数,即最后一列除以的数)。
参考模型原本最偏好"副作用版"(概率 0.5),但它奖励不高。最优策略 \(\pi^*\) 把高奖励的"纯函数版"从 0.3 暴涨到 0.71,把低奖励的"报错版"从 0.2 压制到 0.02。这就是 \(\exp(r/\beta)\) 的作用:它像一个"奖励放大器",奖励越高放大倍数越大(\(e^2 = 7.39\) 倍 vs \(e^{-1} = 0.37\) 倍),让好答案的概率暴涨,坏答案的概率暴跌。
\(\beta\) 控制放大的激进程度:\(\beta\) 越小,\(\exp(r/\beta)\) 对奖励差异越敏感,最优策略越集中在最高分回答上;\(\beta\) 越大,放大效果越温和,\(\pi^*\) 越接近原始参考策略 \(\pi_{\text{ref}}\)。
Step 3:用策略反向表示奖励——"反解"
Step 2 告诉我们:给定奖励函数 \(r\),可以求出最优策略 \(\pi^*\)(正向:\(r \to \pi^*\))。现在我们做一件反过来的事:从 \(\pi^*\) 的公式中把 \(r\) 解出来(反向:\(\pi^* \to r\))。
从 \(\pi^*\) 的定义出发:
\[ \pi^*(y|x) = \frac{1}{Z(x)} \pi_{\text{ref}}(y|x) \exp\left( \frac{r(x, y)}{\beta} \right) \]
两边取对数(log 把乘法变加法,把指数变线性,方便移项):
\[ \log \pi^*(y|x) = \log \pi_{\text{ref}}(y|x) + \frac{r(x, y)}{\beta} - \log Z(x) \]
把 \(r(x,y)\) 移到左边,其余移到右边,再乘以 \(\beta\):
\[ r(x, y) = \beta \log \pi^*(y|x) - \beta \log \pi_{\text{ref}}(y|x) + \beta \log Z(x) = \beta \log \frac{\pi^*(y|x)}{\pi_{\text{ref}}(y|x)} + \beta \log Z(x) \]
这一步的意义:奖励函数 \(r\) 可以完全由两个概率分布的比值来表示。换句话说,奖励被隐式地编码在了策略的概率中——\(\pi^*\) 相比 \(\pi_{\text{ref}}\) 越偏好某个回答 \(y\)(即 \(\frac{\pi^*}{\pi_{\text{ref}}}\) 越大),这个回答的奖励就越高。如果我们能直接训练出 \(\pi^*\),就根本不需要显式的奖励模型了!
\(\beta \log Z(x)\) 是什么? 它只依赖于问题 \(x\),不依赖于具体回答 \(y\)。对于同一道题的不同回答,这一项都是一样的常数。后面 Step 5 会看到:在比较两个回答的奖励差时,这个常数会被完美消除。
Step 4:Bradley-Terry 偏好模型——给"谁更好"建模
到目前为止,我们一直假设有一个奖励函数 \(r(x,y)\) 来给回答打分。但在现实中,人类标注员不会给每个回答打一个精确的数字分("这个回答 7.3 分"),而是给出成对比较:在同一问题 \(x\) 下,从两个候选回答里指出哪一个更好。我们需要一个模型来连接"隐含分数"和"被选中的概率"——这就是 Bradley-Terry (BT) 模型。
符号约定(本节与 DPO 损失里都会出现):
| 符号 | 含义 |
|---|---|
| \(x\) | 用户问题(prompt) |
| \(y_w,\, y_l\) | 一次偏好数据里的胜 / 负回答(win / lose) |
| \(y_w \succ y_l\) | \(y_w\) 严格优于 \(y_l\)(序关系) |
| \(p(y_w \succ y_l \mid x)\) | 给定 \(x\) 时,人类选 \(y_w\) 而非 \(y_l\) 的概率。\(\mid x\) 作用于「\(y_w\) 优于 \(y_l\)」整句事件,不是只条件在单个 \(y\) 上 |
BT 模型的核心等式——我们要推导的结论:
\[ p(y_w \succ y_l \mid x) = \sigma\big(r(x, y_w) - r(x, y_l)\big), \quad \sigma(z) = \frac{1}{1 + e^{-z}} \]
这个 \(\sigma\) 从哪里来? 下面分四步推导。
效用 = 质量 + 噪声。 人类标注不完美——走神、偏好、手滑都会干扰判断。我们把标注员感知到的效用建模为: \[ u(x,y) = r(x,y) + \epsilon \] \(r\) 是真实质量(要学的确定量),\(\epsilon\) 是随机噪声。两个回答各有独立噪声 \(\epsilon_w\)、\(\epsilon_l\)。
「选谁」→ 不等式 → 概率。 标注员选 \(y_w\) 当且仅当 \(u(x,y_w) > u(x,y_l)\),代入并移项: \[ \underbrace{r(x,y_w) - r(x,y_l)}_{\triangleq\;\Delta\;\text{(质量差,确定数)}} \;>\; \underbrace{\epsilon_l - \epsilon_w}_{\triangleq\;\delta\;\text{(噪声差,随机变量)}} \] 质量差 \(\Delta\) 够大,噪声 \(\delta\) 就推翻不了它。选对的概率就是 \(\delta\) 的累积分布函数 (CDF) 在 \(\Delta\) 处的值: \[ p(y_w \succ y_l \mid x) = P(\delta < \Delta) = F_\delta(\Delta) \]
Gumbel 噪声 → Sigmoid。 BT 模型假设每个 \(\epsilon\) 独立服从标准 Gumbel 分布。在给出结论之前,先认识一下这两个分布。
PDF(概率密度函数) 描述随机变量在某个值附近出现的密集程度;CDF(累积分布函数) 描述随机变量 \(\le x\) 的概率,CDF 是 PDF 的积分:\(F(x) = \int_{-\infty}^{x} f(t)\,dt\)。在 BT 模型中,我们用的是 CDF(因为偏好概率 \(= F_\delta(\Delta)\))。
Gumbel 分布(极值分布) 描述的是「很多个随机变量取最大值」的分布。CDF:\(F_{\text{Gumbel}}(x) = e^{-e^{-x}}\),PDF:\(f_{\text{Gumbel}}(x) = e^{-(x + e^{-x})}\)。
Logistic 分布(逻辑分布) 的最大特点:CDF 恰好就是 Sigmoid 函数 \(F_{\text{Logistic}}(x) = \frac{1}{1 + e^{-x}} = \sigma(x)\)。
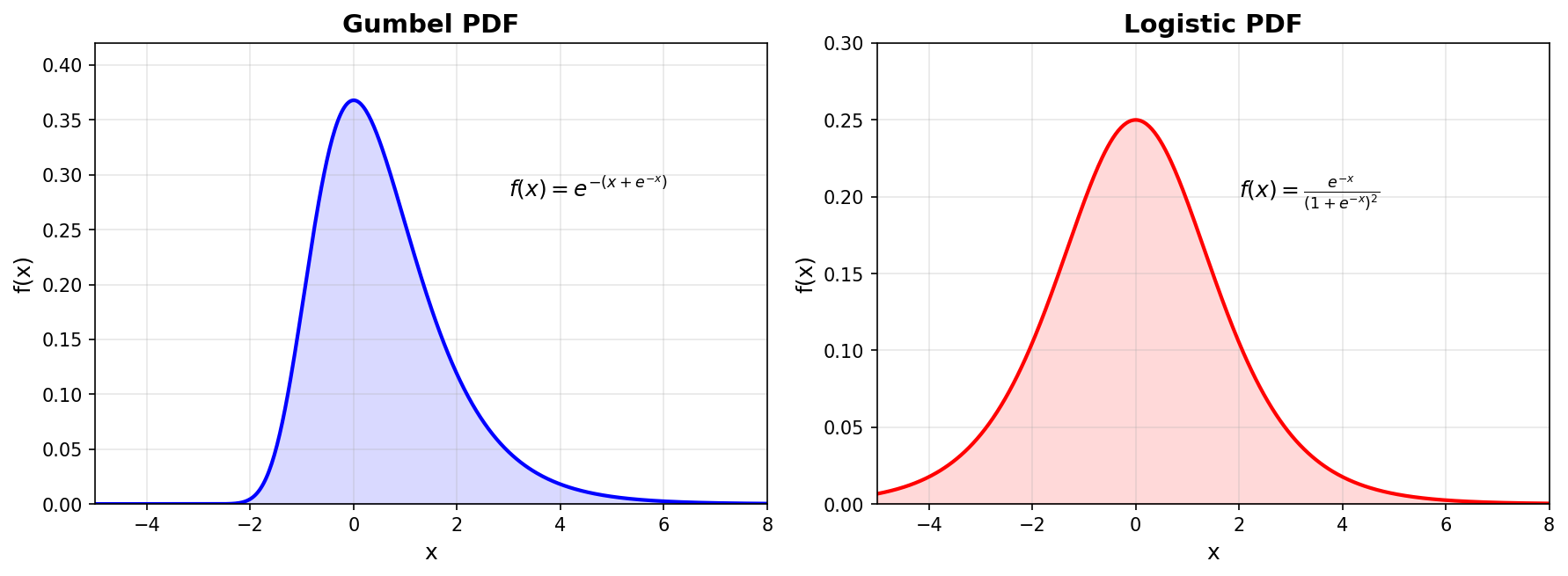
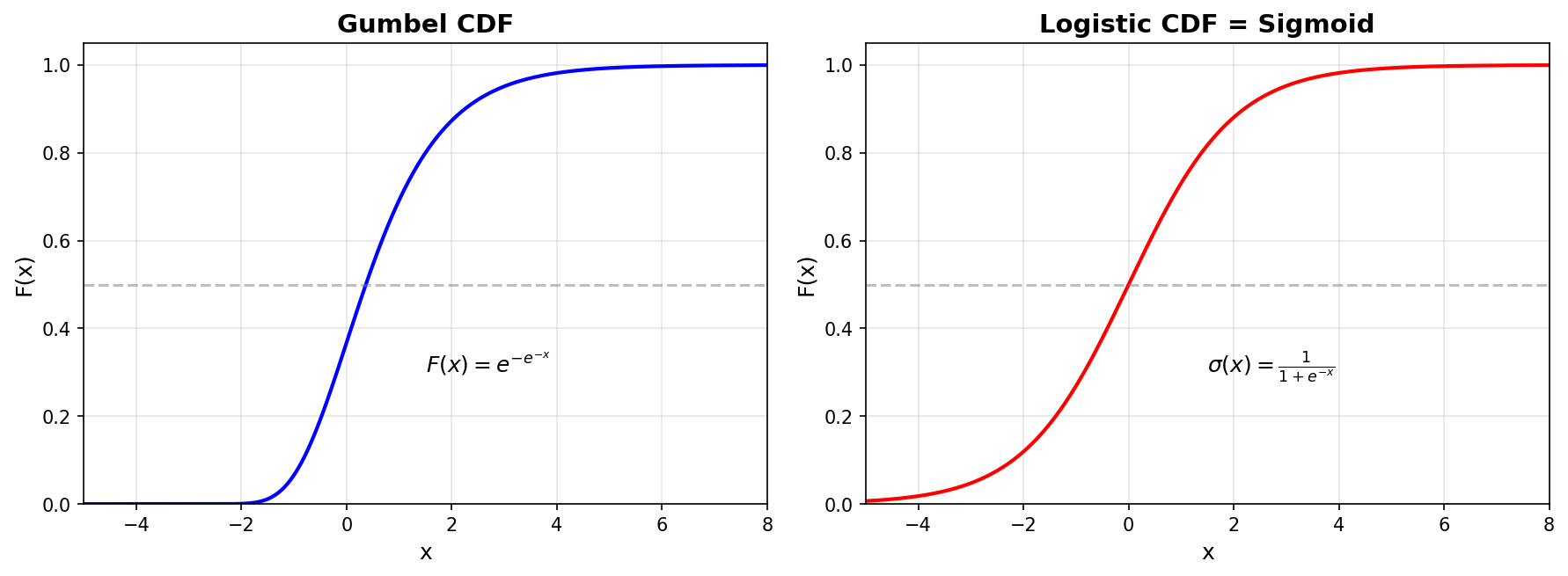
关键结论:若 \(\epsilon_w, \epsilon_l \stackrel{\text{iid}}{\sim} \text{Gumbel}(0,1)\),则它们的差 \(\delta = \epsilon_l - \epsilon_w\) 服从 Logistic 分布,CDF 恰好是 Sigmoid: \[ F_\delta(\Delta) = \frac{1}{1+e^{-\Delta}} = \sigma(\Delta) \]
代入得 BT 公式。 将第 2 步的 \(p = F_\delta(\Delta)\) 与第 3 步的 \(F_\delta = \sigma\) 结合,即得: \[ p(y_w \succ y_l \mid x) = \sigma\big(r(x,y_w) - r(x,y_l)\big) \]
一句话:评分 + Gumbel 噪声 → Logistic 差 → Sigmoid 概率。(若改用高斯噪声则得 probit 模型 \(\Phi(\cdot)\),但 RLHF 中几乎都用 Sigmoid。)
等价写法:\(p(y_w \succ y_l \mid x) = \frac{e^{r(x,y_w)}}{e^{r(x,y_w)} + e^{r(x,y_l)}}\),分子分母同除以 \(e^{r(x,y_l)}\) 就回到 Sigmoid。
用具体数字感受一下 Sigmoid 怎么把奖励差映射为概率:
| \(r(x, y_w) - r(x, y_l)\) | \(\sigma(\cdot)\) | 含义 |
|---|---|---|
| \(+5\) | \(0.993\) | 好答案奖励远高于坏答案 → 人类几乎一定选好答案 |
| \(+1\) | \(0.731\) | 有一定差距 → 人类大概率选好答案 |
| \(0\) | \(0.500\) | 奖励一样 → 人类掷硬币,五五开 |
| \(-2\) | \(0.119\) | 坏答案奖励反而更高 → 人类大概率选"坏答案"(标注可能有误) |
BT 模型正是传统 RLHF 中训练奖励模型的理论基础——用人类偏好数据最大化上式的似然来拟合 \(R_\psi\)。
Step 5:消除奖励模型——DPO 的关键一步
现在,DPO 论文的核心洞察来了:将 Step 3 的"奖励 = 策略概率"代入 Step 4 的 BT 模型。由于 BT 模型只关心两个回答的奖励之差 \(r(x,y_w) - r(x,y_l)\),我们来看看代入后会发生什么:
\[ \begin{aligned} r(x, y_w) - r(x, y_l) &= \left( \beta \log \frac{\pi^*(y_w|x)}{\pi_{\text{ref}}(y_w|x)} + \boxed{\beta \log Z(x)} \right) - \left( \beta \log \frac{\pi^*(y_l|x)}{\pi_{\text{ref}}(y_l|x)} + \boxed{\beta \log Z(x)} \right) \\ &= \beta \log \frac{\pi^*(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi^*(y_l|x)}{\pi_{\text{ref}}(y_l|x)} \end{aligned} \]
两个框中的 \(\beta \log Z(x)\) 完全相同,一减一加恰好抵消为零。
\(\beta \log Z(x)\) 在相减时被完全抵消了!
为什么这个消除如此重要? 回忆 \(Z(x) = \sum_y \pi_{\text{ref}}(y|x) \exp(r(x,y)/\beta)\)——它要对所有可能的回答 \(y\) 求和。语言模型的输出空间是所有可能的 token 序列,数量是天文数字级别(几万词汇表的几百次方),\(Z(x)\) 根本无法计算。但 DPO 通过配对对比(\(y_w\) vs \(y_l\)),让 \(Z(x)\) 在做差时自动消失了,优雅地绕过了这个计算难题。
现在奖励差里只剩下 \(\pi^*\) 和 \(\pi_{\text{ref}}\) 的概率比。在实际训练中,我们把理论上的最优策略 \(\pi^*\) 换成我们正在训练的策略 \(\pi_\theta\)(因为训练的目标就是让 \(\pi_\theta\) 逼近 \(\pi^*\))。
DPO 的最终损失函数
将上述奖励差代入 BT 模型的负对数似然(\(-\log p(y_w \succ y_l | x)\),越小说明模型越能正确区分好坏),我们得到 DPO 的损失函数:
\[ \mathcal{L}_{\text{DPO}}(\theta) = - \mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma \left( \underbrace{\beta \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)}}_{\text{模型对好答案的"偏爱度"}} - \underbrace{\beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)}}_{\text{模型对坏答案的"偏爱度"}} \right) \right] \]
逐层拆解这个公式的含义:
- \(\log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)}\):当前模型 \(\pi_\theta\) 相比参考模型 \(\pi_{\text{ref}}\),有多偏爱好答案 \(y_w\)。如果 \(\pi_\theta\) 把 \(y_w\) 的概率提高了 3 倍,这一项就是 \(\log 3 \approx 1.1\)。
- 两个"偏爱度"做差:如果模型学会了正确区分好坏(好答案偏爱度 > 坏答案偏爱度),差值为正。
- \(\sigma(\cdot)\):Sigmoid 把差值压到 \((0, 1)\) 区间,解释为"模型正确区分好坏的概率"。
- \(-\log\):负对数似然,差值越大 → \(\sigma\) 越接近 1 → \(-\log\) 越接近 0 → 损失越小。
回到排序函数的例子:如果训练后 \(\pi_\theta\) 把"纯函数版"的概率提高了 5 倍,"副作用版"只提高了 1.2 倍,那么 Sigmoid 内的差值就是 \(\beta(\log 5 - \log 1.2) \approx 1.43\beta > 0\),经过 \(\sigma\) 后接近 1,损失接近 0——说明模型学对了。
DPO 梯度分析:损失函数在做什么?
对 DPO 损失求梯度。先记 \(\hat{r}_\theta = \beta \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)}\)(隐式奖励差),则损失可以简写为:
\[ \mathcal{L}_{\text{DPO}} = -\mathbb{E}\left[\log \sigma(\hat{r}_\theta)\right] \]
对 \(\theta\) 求梯度,用链式法则拆成三层:
\[ \nabla_\theta \mathcal{L}_{\text{DPO}} = -\mathbb{E}\left[ \underbrace{\frac{1}{\sigma(\hat{r}_\theta)}}_{\text{外层:}\frac{d}{dz}\log z} \cdot \underbrace{\sigma'(\hat{r}_\theta)}_{\text{中层:Sigmoid 导数}} \cdot \underbrace{\nabla_\theta \hat{r}_\theta}_{\text{内层:}\hat{r}\text{ 对 }\theta} \right] \]
中层简化:Sigmoid 有一个好用的导数性质 \(\sigma'(z) = \sigma(z) \cdot \sigma(-z)\)。代入后外层和中层合并:
\[ \frac{\sigma'(\hat{r}_\theta)}{\sigma(\hat{r}_\theta)} = \frac{\sigma(\hat{r}_\theta) \cdot \sigma(-\hat{r}_\theta)}{\sigma(\hat{r}_\theta)} = \sigma(-\hat{r}_\theta) \]
内层简化:\(\hat{r}_\theta\) 中只有 \(\log \pi_\theta\) 项依赖 \(\theta\)(\(\pi_{\text{ref}}\) 是冻结的),所以:
\[ \nabla_\theta \hat{r}_\theta = \beta \left( \nabla_\theta \log \pi_\theta(y_w|x) - \nabla_\theta \log \pi_\theta(y_l|x) \right) \]
三层合并,就得到:
\[ \nabla_\theta \mathcal{L}_{\text{DPO}} = -\beta \mathbb{E}_{(x, y_w, y_l)} \left[ \underbrace{\sigma(-\hat{r}_\theta)}_{\text{权重}} \left( \underbrace{\nabla_\theta \log \pi_\theta(y_w|x)}_{\text{增大好答案概率}} - \underbrace{\nabla_\theta \log \pi_\theta(y_l|x)}_{\text{减小坏答案概率}} \right) \right] \]
梯度揭示了 DPO 的自适应学习机制:
- \(\sigma(-\hat{r}_\theta)\) 是一个自动调节的权重。当模型已经学得很好(\(\hat{r}_\theta\) 很大),\(\sigma(-\hat{r}_\theta) \to 0\),梯度变小——模型不再在"已学会"的样本上浪费力气。
- 当模型还没学好(\(\hat{r}_\theta\) 接近 0 或为负),\(\sigma(-\hat{r}_\theta) \to 1\),梯度很大——模型集中火力攻克"还没学会"的样本。
- 这相当于一种自动课程学习(Curriculum Learning),模型自动聚焦于最需要改进的偏好对。
DPO 的完整实现
以下是 DPO 的完整 PyTorch 实现伪代码,包括数据加载、模型定义和完整的训练循环。
Step 1: 数据格式 — 偏好对数据集
与 PPO 不同,DPO 不需要在线采样,直接使用预先收集好的偏好对数据集:
"""
DPO 数据格式:每条数据是一个三元组 (prompt, chosen, rejected)
例如(来自 Anthropic HH-RLHF 数据集):
{
"prompt": "用 Python 写一个排序函数。",
"chosen": "def sort(arr): return sorted(arr) # 纯函数,不修改原数组",
"rejected": "def sort(arr): arr.sort(); return arr # 有副作用,修改了原数组"
}
"""
# DPO 为离线对齐:无需环境交互,直接用人类标注的 (x, y_w, y_l) 做对比学习
preference_dataset = load_dataset("preference_pairs") # List of (prompt, chosen, rejected);每条对应一次“胜者 vs 败者”的 BT 似然项Step 2: 模型定义 — 只需要两个模型!
DPO 最大的优势:相比 RLHF-PPO 的四模型架构,DPO 只需要两个模型:
import torch # 张量与自动求导:DPO 损失只对 π_θ 反传
import torch.nn.functional as F # log_softmax / logsigmoid:实现序列 log π 与 BT 负对数似然
from transformers import AutoModelForCausalLM, AutoTokenizer # 因果 LM:拟合策略分布 π(y|x)
# 模型 1: 待训练的策略模型 (Actor)
actor = AutoModelForCausalLM.from_pretrained("sft_checkpoint") # 当前策略 π_θ,对齐要更新的对象
# 模型 2: 冻结的参考模型 (Reference) — 就是 SFT 后的快照
ref_model = AutoModelForCausalLM.from_pretrained("sft_checkpoint") # 冻结的 π_ref,作 KL 正则锚点
ref_model.requires_grad_(False) # 不训练参考模型,仅前向计算 log π_ref 以构造隐式奖励差
# 对比 RLHF-PPO:不需要 Critic 模型,不需要 Reward 模型!
# PPO 需要 4 个模型 → DPO 只需要 2 个,显存节省约 50%
tokenizer = AutoTokenizer.from_pretrained("sft_checkpoint") # 将 prompt 与回答编成 token 序列,才能逐 token 累加 log π
optimizer = torch.optim.AdamW(actor.parameters(), lr=1e-6) # 仅优化 Actor;DPO 等价于对偏好对的监督目标做一阶梯度下降
beta = 0.1 # KL 惩罚系数,控制偏离参考模型的程度Step 3: 完整训练循环
for epoch in range(num_epochs):
for batch in dataloader(preference_dataset, batch_size=4):
prompts, chosen_responses, rejected_responses = batch
# ---- 1. Tokenize: 拼接 prompt + response ----
# tokenize 把文本变成 token id 序列, 返回三样东西:
# ids: (B, L) [prompt tokens | response tokens] 完整 token 序列
# mask: (B, L) [0 0 ... 0 | 1 1 ... 1 ] 只在 response 部分为 1
# labels: (B, L) 和 ids 相同的 token id(内容相同), 用于 next-token prediction 时
# 做 gather (取出真实 token 的 log 概率)
chosen_ids, chosen_mask, chosen_labels = tokenize(prompts, chosen_responses)
rejected_ids, rejected_mask, rejected_labels = tokenize(prompts, rejected_responses)
# ---- 2. 前向传播: 计算四组 log π ----
# π_θ 对好/坏回答的对数概率 (需要梯度)
pi_w = compute_log_probs(actor, chosen_ids, chosen_labels, chosen_mask)
pi_l = compute_log_probs(actor, rejected_ids, rejected_labels, rejected_mask)
# pi_w, pi_l: (B,)
# π_ref 对好/坏回答的对数概率 (冻结, 无梯度)
with torch.no_grad():
ref_w = compute_log_probs(ref_model, chosen_ids, chosen_labels, chosen_mask)
ref_l = compute_log_probs(ref_model, rejected_ids, rejected_labels, rejected_mask)
# ref_w, ref_l: (B,)
# ---- 3. 计算 DPO 损失 ----
# log-ratio: 当前策略相对参考策略的偏好程度
chosen_logratios = pi_w - ref_w # (B,)
rejected_logratios = pi_l - ref_l # (B,)
# 隐式奖励差 r̂ = β · (log-ratio差)
reward_diff = beta * (chosen_logratios - rejected_logratios) # (B,)
# DPO 损失 = -log σ(r̂)
# 用 logsigmoid 代替 log(sigmoid(x)),避免数值下溢
loss = -F.logsigmoid(reward_diff).mean() # scalar
# ---- 4. 反向传播 ----
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(actor.parameters(), max_norm=1.0)
optimizer.step()
# ---- 5. 监控指标 ----
with torch.no_grad():
# 隐式奖励差 (越大说明 y_w 和 y_l 区分度越高)
reward_margin = reward_diff.mean().item()
# 偏好分类准确率 (好答案得分 > 坏答案 的比例)
accuracy = (reward_diff > 0).float().mean().item()Step 4: 辅助函数 — 计算序列的对数概率
语言模型中,一个回答的对数概率是所有 token 对数概率之和:
\[ \log \pi_\theta(y|x) = \sum_{t=1}^{T} \log \pi_\theta(y_t | x, y_{<t}) \]
def compute_log_probs(model, input_ids, labels, attention_mask):
"""
计算模型对给定序列的 log π(y|x)
Args:
input_ids: (B, L) prompt + response 的 token id
labels: (B, L) 和 input_ids 相同的 token id, 用作
next-token prediction 的"答案"——
位置 t 的 logits 预测 labels[t+1]
attention_mask: (B, L) 1 = 回答部分, 0 = prompt 部分
Returns:
(B,) 每条样本的序列级对数概率
"""
# ref 模型不需要梯度; actor 需要保留计算图以回传 DPO 梯度
ctx = torch.no_grad() if not model.training else torch.enable_grad()
with ctx:
# 前向传播, 得到每个位置对词表的打分
logits = model(
input_ids=input_ids,
attention_mask=attention_mask
).logits
# logits: (B, L, V) V=vocab_size
# 因果 LM: 位置 t 的 logits 预测位置 t+1 的 token, 所以要错一位对齐:
# logits[:, :-1, :] → 去掉最后一位, 保留位置 0 ~ L-2 (共 L-1 个)
# labels[:, 1:] → 去掉第一位, 保留位置 1 ~ L-1 (共 L-1 个)
# 这样 logits[t] 对应 labels[t+1], 即"位置 t 预测下一个 token"
log_probs = F.log_softmax(logits[:, :-1, :], dim=-1)
# log_probs: (B, L-1, V)
# gather: 从词表维度 V 中, 按 labels 给的 token id 取出对应的 log 概率
# 举例: log_probs[b, t, :] 是长度 V 的向量 (词表里每个 token 的 log 概率),
# labels[b, t+1] = 42, 则 gather 取出 log_probs[b, t, 42]
token_log_probs = torch.gather(
log_probs, # (B, L-1, V)
dim=-1, # 沿词表维度取
index=labels[:, 1:].unsqueeze(-1) # (B, L-1, 1) 指定要取哪个 token
).squeeze(-1)
# token_log_probs: (B, L-1) 每个位置上真实 token 的 log π
# mask 掉 prompt 部分, 只对回答 token 求和
return (token_log_probs * attention_mask[:, 1:]).sum(dim=-1)
# return: (B,)与 PPO 实现的关键对比:
- PPO 需要在线采样(用 Actor 生成回答 → Reward Model 打分 → GAE 估计优势 → 多 epoch 裁剪更新),代码约 100 行。
- DPO 只需要前向传播 + 交叉引用四个对数概率 + 一行损失计算,代码不到 30 行。
- PPO 涉及重要性采样比 \(r(\theta)\)、裁剪区间 \([1-\epsilon, 1+\epsilon]\)、GAE \(\lambda\) 等超参数;DPO 只有一个超参数 \(\beta\)。
开源代码参考: Hugging Face TRL 库
(trl.DPOTrainer)
提供了生产级别的 DPO 实现,支持 LoRA、多 GPU 训练、梯度累积等。
DPO 的优势与局限
优势
极其简单:DPO 将 RL 问题转化为二元分类问题。整个训练流程与 SFT 几乎一致——加载数据、前向传播、反向传播、更新参数。不需要训练奖励模型,不需要 Critic 网络,不需要 PPO 的在线采样、GAE、多 epoch 裁剪更新。
显存友好:DPO 只需要 2 个模型(Actor + Reference),而 PPO 需要 4 个(Actor + Critic + Reference + Reward Model)。对于 70B 参数模型(FP16 约 140GB),PPO 需要 4 × 140GB = 560GB 显存,DPO 只需要 2 × 140GB = 280GB——差距巨大。
训练稳定:DPO 的损失函数是平滑的(Sigmoid + 对数),梯度有良好的数学性质(自适应加权,见梯度分析)。而 PPO 涉及多个相互耦合的组件(Actor 更新 → Critic 更新 → 优势估计变化 → Actor 目标变化),任何一个环节不稳定都会导致训练崩溃。
超参数少:DPO 核心超参数只有 \(\beta\)(KL 惩罚系数)。PPO 则有裁剪区间 \(\epsilon\)、GAE 参数 \(\lambda\)、value function coefficient、entropy coefficient、mini-batch size、epoch 数等大量需要调优的参数。
局限
- 离线学习的分布偏移问题 (Distribution Shift)
DPO 依赖于预先收集好的静态偏好数据集,而这些偏好对通常是由参考策略 \(\pi_{\text{ref}}\)(或另一个模型)生成的。随着训练的进行,\(\pi_\theta\) 逐渐偏离 \(\pi_{\text{ref}}\),训练数据对当前策略而言越来越"过时"——这就是分布偏移问题。
数学上看,DPO 损失中的 \(\log \pi_\theta(y_w|x)\) 和 \(\log \pi_\theta(y_l|x)\) 是在固定的 \((y_w, y_l)\) 上计算的。这些 \((y_w, y_l)\) 是训练前由 \(\pi_{\text{ref}}\) 生成的——它们是 \(\pi_{\text{ref}}\) 大概率会说的话。但随着训练推进,\(\pi_\theta\) 的分布会发生变化:它学会了新的表达方式,原来 \(\pi_{\text{ref}}\) 爱说的那些回答,现在 \(\pi_\theta\) 可能觉得"我根本不会这么说"——即 \(\pi_\theta(y_w|x)\) 和 \(\pi_\theta(y_l|x)\) 都变得很小。在低概率区域,\(\log \pi_\theta\) 的梯度信号极弱,模型几乎学不到有用信息。这类似于上一篇中重要性采样权重方差爆炸的问题——数据来自"旧分布",用来更新"新分布"时效率急剧下降。
改进尝试:Iterative DPO / Online DPO 通过定期用当前策略重新生成偏好对来缓解分布偏移,但这本质上又引入了在线采样的开销。
- 探索能力有限,难以产生涌现
在线 RL(如 PPO)允许模型在探索中发现比人类标注更好的答案(例如 AlphaGo 发现新定式,DeepSeek-R1 涌现出长思维链"顿悟")。DPO 只能模仿数据集中已有的偏好,难以产生真正的"涌现"和"超越"。
用例子理解:假设一道很难的数学推理题,人类标注员自己都做不出来,无法提供正确的偏好标注。DPO 就束手无策了。而在线 RL 可以让模型自己反复尝试,一旦碰巧写出正确答案,就立刻强化它——这就是 DeepSeek-R1 中"顿悟时刻"的由来。
- 隐式奖励的局限性
DPO 假设最优策略和奖励之间存在精确的双射关系(Step 2-3 的推导)。但实际中这个假设并不总是成立——当偏好数据有噪声、标注不一致、或存在多种同样好的回答风格时,DPO 可能学到一个扭曲的隐式奖励函数。PPO 的显式奖励模型可以单独训练和评估,更容易发现和修正奖励建模的问题。
全景对比
| 维度 | PPO (RLHF) | DPO |
|---|---|---|
| 模型数量 | 4 (Actor + Critic + Ref + RM) | 2 (Actor + Ref) |
| 训练方式 | 在线 RL(采样 → 评分 → 更新) | 离线监督学习(直接从偏好对学习) |
| 核心优化 | 裁剪后的策略梯度 + GAE | 负对数似然 (交叉熵变体) |
| 超参数 | 多 (\(\epsilon\), \(\lambda\), \(\gamma\), lr, ...) | 少 (\(\beta\), lr) |
| 探索能力 | 强(在线采样发现新解) | 弱(受限于离线数据集) |
| 稳定性 | 低(多组件耦合,易崩溃) | 高(标准监督学习) |
| 适用场景 | 推理型模型(数学、代码、长思维链) | 通用对齐(对话质量、安全性) |
因此,虽然 DPO 在开源社区大火,但在追求极致推理能力的最前沿大模型中,在线强化学习(Online RL)仍然是不可替代的王者。
那么,如何解决在线 RL(PPO)的显存危机呢?这就引出了我们下一篇的主角:GRPO。
参考资料:
- Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., & Finn, C. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. NeurIPS 2023.
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., ... & Lowe, R. (2022). Training language models to follow instructions with human feedback. NeurIPS 2022.
- Bradley, R. A., & Terry, M. E. (1952). Rank analysis of incomplete block designs: I. The method of paired comparisons. Biometrika.