笔记|强化学习(六):DAPO:从 GRPO 到大规模推理 RL 的工程实践
本文为 RL 系列的第六篇。在上几篇中我们推导了 GRPO(组相对策略优化,Group Relative Policy Optimization)的核心思想并将其应用于图像生成。本文将介绍 GRPO 的工程增强版——DAPO(解耦裁剪与动态采样策略优化,Decoupled clip and dynAmic samPling policy Optimization),它是字节跳动 Seed 团队与清华 AIR 联合提出的大规模 LLM 强化学习算法,用 Qwen2.5-32B 基座模型在 AIME 2024 上达到 50 分(超过 DeepSeek-R1-Zero 的 47 分),且训练步数减少 50%。
论文:DAPO: An Open-Source LLM Reinforcement Learning System at Scale(2025.03)
先看问题:GRPO 在大规模训练中遇到了什么?
还是用上一篇的数学题例子开场。 假设我们用 GRPO 训练一个推理模型解数学竞赛题(AIME 级别),每道题让模型生成 \(G = 16\) 个回答,然后用规则判题:对了奖励 \(+1\),错了奖励 \(-1\)。
先看一组理想情况下的训练数据:
| 题目 | 回答数 | 正确/错误 | 奖励分布 | \(\sigma_R\) |
|---|---|---|---|---|
| 竞赛题 A(模型完全不会) | 16 | 0/16 | 全是 \(-1\) | \(0\) |
| 竞赛题 B(模型基本掌握) | 16 | 12/4 | 12 个 \(+1\),4 个 \(-1\) | \(>0\) |
| 竞赛题 C(模型轻松拿下) | 16 | 16/0 | 全是 \(+1\) | \(0\) |
问题暴露了:
题 A 和题 C 的 \(\sigma_R = 0\)(所有回答的奖励完全相同),GRPO 的优势公式 \(\hat{A}_i = \frac{r_i - \mu_R}{\sigma_R + \varepsilon}\) 中分子 \(r_i - \mu_R = 0\)(每个回答的奖励都等于组均值),因此所有优势 \(\hat{A}_i = 0\),梯度信号为零。单个 Prompt 的优势为零本身是合理的(确实没有区分信号),但随着训练推进,模型逐渐"两极化"——简单题全对、困难题全错——导致一个 batch 中大部分 Prompt 的 \(\sigma_R = 0\)。有效参与梯度更新的样本越来越少,梯度估计方差增大,训练不稳定;同时大量生成的轨迹被浪费,计算效率极低。
熵崩溃(Entropy Collapse):在 PPO 一文中,经典 PPO 的损失函数包含一个熵奖励(Entropy Bonus)项 \(c_2 \cdot S[\pi_\theta](s_t)\),其中策略熵定义为:
\[S[\pi_\theta](s_t) = -\sum_{v=1}^{|V|} \pi_\theta(v \mid s_t) \log \pi_\theta(v \mid s_t)\]
\(|V|\) 是词表大小,\(\pi_\theta(v \mid s_t)\) 是策略在状态 \(s_t\)(当前已生成的上下文)下选择 token \(v\) 的概率。熵衡量的是每个生成位置上策略对整个词表的概率分布的不确定性,取值范围 \([0,\;\log|V|]\)——均匀分布时取上限 \(\log|V|\),确定性策略时取下限 \(0\)(详细推导见 PPO 一文中熵奖励部分)。PPO 以负号引入熵(\(-c_2 \cdot S\)),等价于鼓励策略保持高熵、避免坍缩到确定性策略。
然而研究表明(Shen et al., arXiv:2509.03493),这种熵奖励在 LLM-RL 中几乎无效。直觉是:LLM 每一步的动作空间是整个词表(3~13 万 token),但在任何给定位置只有少数 token 语义相关。熵奖励的梯度 \(\nabla_\theta S[\pi_\theta]\) 试图拉平全词表概率分布——它会同时推高成千上万个毫不相关的 token(如在英文语境下推高中文标点的概率),噪声梯度淹没了对少数有意义探索 token 的鼓励信号。
GRPO 因此未采用熵奖励,而裁剪机制本身才是导致熵崩溃的直接原因:对称裁剪 \([1-\varepsilon, 1+\varepsilon]\) 对低概率探索 Token 极不利——概率仅 0.01 的 Token 每步最多涨到 \(0.01 \times 1.2 = 0.012\),几乎无法增长;高概率 Token(0.5)却可轻松涨到 \(0.5 \times 1.2 = 0.6\)。对称裁剪系统性地压制低概率路径,策略熵持续下降,最终模型只会生成少数固定模式的回答。
长回答的奖励噪声:数学推理的回答长度差异极大(50 Token 到 5000+ Token)。传统 \(+1/-1\) 奖励只看最终答案是否正确,不区分长短——50 Token 的简洁解法和 5000 Token 的循环推理(碰巧答对)都得 \(+1\)。而 GRPO 使用按回答归一化(per-response normalization,也称序列级归一化):先对每个回答内部的 Token 损失求平均,再对 \(G\) 个回答求平均——\(\frac{1}{G}\sum_i \frac{1}{|o_i|}\sum_t L_{i,t}\)。注意 GRPO 的裁剪和 IS ratio 在 token 级逐位计算(\(\rho_{i,t}\)),此处"序列级"仅指聚合方式——每条回答不论长短权重都是 \(\frac{1}{G}\),5000 Token 的回答中每个 Token 只分到 50 Token 回答的 \(\frac{1}{100}\) 的梯度信号。当 batch 中混杂着大量超长低质回答时,有效的梯度信号被稀释,训练方向被噪声主导。
用原始 GRPO 训练 Qwen2.5-32B,团队在 AIME 2024 上只拿到了 30 分——远低于 DeepSeek-R1-Zero 的 47 分。DAPO 的四个技术正是为解决以上三个问题而生。
DAPO 的四大核心技术
技术一:Clip-Higher(非对称裁剪)
问题复盘:对称裁剪 \([1-\varepsilon, 1+\varepsilon]\) 在抑制概率下降和鼓励概率上升时使用相同的力度。但"探索"需要让小概率 Token 涨上去,而"维稳"需要限制大概率 Token 不要突变。这两件事不应该用同一个阈值。
用例子理解:模型解题时正确用了"换元法"(概率仅 0.01),而"直接暴力展开"(概率 0.8)虽然也对但不够优雅。对称裁剪下,"换元法"的概率上界只能到 \(0.01 \times 1.2 = 0.012\)(增长 20%),而"暴力展开"的概率上界可到 \(0.8 \times 1.2 = 0.96\)(绝对增量 0.16)。低概率探索路径几乎无法获得实质性增长。
Clip-Higher 的解决方案:将裁剪范围解耦为两个独立参数 \(\varepsilon_{\text{low}}\) 和 \(\varepsilon_{\text{high}}\):
\[ \mathcal{J}_{\text{DAPO}}(\theta) = \mathbb{E}\left[\frac{1}{\sum_{i=1}^{G}|o_i|} \sum_{i=1}^{G}\sum_{t=1}^{|o_i|} \min\Big(r_{i,t}(\theta)\hat{A}_{i,t},\ \text{clip}\big(r_{i,t}(\theta),\, 1-\varepsilon_{\text{low}},\, 1+\varepsilon_{\text{high}}\big)\hat{A}_{i,t}\Big)\right] \]
其中 \(r_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t} | q, o_{<t})}{\pi_{\theta_{\text{old}}}(o_{i,t} | q, o_{<t})}\) 是 Token 级别的重要性采样比率。
关键参数选择:DAPO 论文中使用 \(\varepsilon_{\text{low}} = 0.2\),\(\varepsilon_{\text{high}} = 0.28\)。
为什么这能防止熵崩溃? 用一个具体例子走一遍。假设 Token \(o_t\)("换元法"的关键 Token)出现在一个正确回答中,优势 \(\hat{A}_t > 0\),旧策略概率 \(\pi_{\text{old}}(o_t) = 0.01\)。
PPO 裁剪目标的梯度行为取决于概率比 \(r_t = \frac{\pi_\theta(o_t)}{\pi_\text{old}(o_t)}\):
\[ \nabla_\theta J \propto \begin{cases} \hat{A}_t \cdot \nabla_\theta \log \pi_\theta(o_t) & \text{if } r_t(\theta) < 1 + \varepsilon_{\text{high}} \quad \text{(未触顶:正常更新)} \\ 0 & \text{if } r_t(\theta) \geq 1 + \varepsilon_{\text{high}} \quad \text{(触顶:梯度被截断)} \end{cases} \]
也就是说:只要 \(r_t\) 没超过上界,梯度正常流过、概率继续涨;一旦 \(r_t\) 触顶,梯度变成零,概率就涨不动了。裁剪上界就是给概率增长设了一个"天花板"。
天花板在哪里? \(r_t \leq 1 + \varepsilon_{\text{high}}\) 意味着 \(\pi_\theta(o_t) \leq \pi_\text{old}(o_t) \times (1 + \varepsilon_{\text{high}})\):
| 裁剪方式 | \(\varepsilon_{\text{high}}\) | 天花板 \(\pi_{\text{max}}\) | 含义 |
|---|---|---|---|
| 对称裁剪(GRPO) | 0.2 | \(0.01 \times 1.2 = 0.012\) | 概率最多涨 20%,从 1% 到 1.2% |
| Clip-Higher(DAPO) | 0.28 | \(0.01 \times 1.28 = 0.0128\) | 概率最多涨 28%,从 1% 到 1.28% |
单步差距看起来不大,但 PPO 是多 epoch 迭代的——每轮的"终点"是下一轮的"起点"。经过 \(n\) 轮更新后累积效果如下:
| 更新轮次 | 对称裁剪 (\(\times 1.2\)) | Clip-Higher (\(\times 1.28\)) |
|---|---|---|
| 0(初始) | 0.010 | 0.010 |
| 1 | 0.012 | 0.013 |
| 5 | 0.025 | 0.034 |
| 10 | 0.062 | 0.112 |
| 15 | 0.154 | 0.365 |
10 轮后差距接近 2 倍,15 轮后差距超过 2 倍。 GRPO 的"换元法"Token 始终趴在低概率区域无法突围,而 DAPO 允许它逐步成长为一个有竞争力的选项。
对于 \(\hat{A}_t < 0\) 的情况(Token 出现在坏回答中,应该被抑制),裁剪下界仍由 \(\varepsilon_{\text{low}} = 0.2\) 控制——惩罚力度不变。不对称设计的本质是:给好的探索更多增长空间,对错误保持同等惩罚。
直觉对比:
| 对称裁剪(PPO/GRPO) | Clip-Higher(DAPO) | |
|---|---|---|
| 裁剪范围 | \([1-\varepsilon, 1+\varepsilon] = [0.8, 1.2]\) | \([1-\varepsilon_{\text{low}}, 1+\varepsilon_{\text{high}}] = [0.8, 1.28]\) |
| 概率 0.01 的 Token 可涨到 | \(0.012\) | \(0.0128\) |
| 经过 10 次更新后 | \(0.01 \times 1.2^{10} \approx 0.062\) | \(0.01 \times 1.28^{10} \approx 0.112\) |
| 效果 | 探索被压制,熵崩溃 | 探索空间更大,策略保持多样性 |
为什么 DAPO 能移除 KL 惩罚? GRPO 中 KL 惩罚 \(\beta \cdot D_{\text{KL}}(\pi_\theta \| \pi_{\text{ref}})\) 的职责是防止 reward hacking——策略可能利用奖励模型的漏洞骗取高分,KL 约束使策略不至于偏离参考模型太远。但 KL 惩罚是全局性的:它惩罚所有概率变化,包括有益的探索,反而加剧了熵崩溃。Clip-Higher 是局部性的约束:只在概率比率超出裁剪范围时截断梯度,范围内的更新完全自由。DAPO 论文发现,裁剪机制本身已足够约束单步策略变化幅度,KL 惩罚的防护因此多余,移除它还能省掉一个冻结参考模型的显存。
技术二:Dynamic Sampling(动态采样)
问题复盘:回到开头的例子——题 A(全错)和题 C(全对)的 16 个回答没有产生任何梯度信号。在大规模训练中,这种"零方差"样本可能占到 batch 的一大半,导致有效训练数据大幅缩水。
Dynamic Sampling 的解决方案:只保留组内奖励方差大于零(\(\sigma_R > 0\))的 Prompt 组,过滤掉全对或全错的无效样本,然后累积有效样本直到达到目标 batch size。
用例子理解:假设目标 batch 需要 512 个
Prompt,每轮我们采样 \(512 \times 3 =
1536\) 个 Prompt(batch_multiplier = 3):
| 步骤 | 操作 | 结果 |
|---|---|---|
| 1 | 采样 1536 个 Prompt,每个生成 16 个回答 | 共 24576 个回答 |
| 2 | 对每组计算 \(\sigma_R\) | 发现 400 组 \(\sigma_R > 0\),1136 组 \(\sigma_R = 0\) |
| 3 | 只保留 \(\sigma_R > 0\) 的 400 组存入缓存 | 缓存有 400 组 |
| 4 | 缓存不足 512 组,继续采样新一批 Prompt | 新增 150 组有效样本 |
| 5 | 缓存达到 550 组(≥ 512),截取 512 组训练 | 开始梯度更新 |
核心约束:DAPO 同时要求每个保留的 Prompt 组中必须同时包含正确和错误的回答:
\[ 0 < \left\lvert\{o_i \mid \text{is}\_\text{correct}(a, o_i)\}\right\rvert < G \]
其中 \(\text{is}\_\text{correct}(a, o_i)\) 是判定函数,表示"给定标准答案 \(a\),第 \(i\) 个回答 \(o_i\) 是否正确";\(\left\lvert\{\cdot\}\right\rvert\) 表示集合的基数(元素个数)。整个不等式的含义是:\(G\) 个采样回答中,正确回答的数量必须严格大于 0 且严格小于 \(G\)——即每组样本中必须同时存在正确和错误的回答。这确保了每个 Prompt 都能提供"做对了的回答应该被鼓励、做错了的回答应该被抑制"的双向梯度信号。
伪代码:
# 缓存通过动态采样筛选后的有效 Prompt 组(含 G 条回答与奖励)
cache = []
# 有效组数未达目标前持续过采样
while len(cache) < target_batch_size:
# 一次采多倍题目,为过滤零方差组留余量
prompts = sample_prompts(batch_multiplier * target_batch_size)
# 遍历本批中的每一道题目(或对话上下文)
for prompt in prompts:
# 对每题并行采样 G 条推理轨迹供组内对比
responses = model.generate(prompt, num_return=G)
# 规则判题等得到序列级标量奖励,用于后续优势估计
rewards = judge(responses)
# 论文约束:正确回答数 ∈ (0, G),即必须同时有正确和错误回答
num_correct = sum(is_correct(a, o) for o in responses)
if 0 < num_correct < G:
cache.append((prompt, responses, rewards))
# 超过最大采样轮次仍凑不齐 batch 则中止,避免训练挂死
if generation_rounds >= max_gen_batches:
# 动态采样失败时显式报错,便于调大 multiplier 或 max_rounds
raise RuntimeError("无法累积足够的有效样本")
# 取前 target_batch_size 组作为本步训练 batch
train_batch = cache[:target_batch_size]技术三:Token-Level Policy Gradient Loss(Token 级损失)
问题复盘:标准 GRPO 使用序列级(Sequence-Level)的损失归一化——每个回答的贡献权重相同,不论长短。但在数学推理场景中,不同回答的长度差异极大(短回答 50 Token,长回答 5000 Token)。如果按序列级归一化,一个 5000 Token 的长回答和一个 50 Token 的短回答对损失的贡献一样大,但长回答中每个 Token 分到的梯度只有短回答的 1/100。
用例子理解:
| 回答 | Token 数 | 正确性 | 序列级权重(GRPO) | Token 级权重(DAPO) |
|---|---|---|---|---|
| \(o_1\)(简洁解法) | 50 | 正确 | \(\frac{1}{2}\) | \(\frac{50}{5050} \approx 1\%\) |
| \(o_2\)(长推导) | 5000 | 正确 | \(\frac{1}{2}\) | \(\frac{5000}{5050} \approx 99\%\) |
GRPO 给了两个回答相同的权重,这意味着长回答的 5000 个 Token 平均每个只分到 \(\frac{1}{2 \times 5000} = 0.0001\) 的梯度——信号太弱了。
Token-Level Loss 的解决方案:归一化因子从"回答数"改为"总 Token 数":
\[ \text{GRPO 归一化因子} = \frac{1}{G} \sum_{i=1}^{G} \left(\frac{1}{|o_i|}\sum_{t=1}^{|o_i|} L_{i,t}\right) \quad \xrightarrow{\text{DAPO}} \quad \text{DAPO 归一化因子} = \frac{1}{\sum_{i=1}^{G} |o_i|} \sum_{i=1}^{G} \sum_{t=1}^{|o_i|} L_{i,t} \]
其中 \(L_{i,t} = \min\big(r_{i,t}\hat{A}_{i,t},\ \text{clip}(r_{i,t},\, 1-\varepsilon_{\text{low}},\, 1+\varepsilon_{\text{high}})\hat{A}_{i,t}\big)\)。
直觉:GRPO 先求每个回答的"平均 Token 损失",再求回答间平均——长短回答贡献相同。DAPO 直接对所有 Token 做全局平均——每个 Token 的贡献相同,长回答中的推理步骤得到了应有的梯度信号。
技术四:Overlong Reward Shaping(超长回答奖励塑形)
问题复盘:推理模型有时会陷入"循环推理"(重复验证或反复改写),生成远超必要长度的回答。在纯粹的 \(+1/-1\) 二值奖励下,一个 500 Token 的正确解和一个 15000 Token 的正确解获得相同的 \(+1\) 奖励——模型没有任何动力去简洁作答,甚至可能越来越啰嗦(因为长回答中"凑巧"碰到正确答案的概率更高)。
Overlong Reward Shaping 的解决方案:对超过超长阈值 \(L_{\text{thresh}} = L_{\text{max}} - L_{\text{buffer}}\) 的回答施加长度惩罚:
\[ r_{\text{shaped}} = \begin{cases} r_{\text{original}} & \text{if } |o| \leq L_{\text{max}} - L_{\text{buffer}} \\ \min\left(r_{\text{original}},\ -\frac{|o| - (L_{\text{max}} - L_{\text{buffer}})}{L_{\text{buffer}}} \cdot p\right) & \text{if } |o| > L_{\text{max}} - L_{\text{buffer}} \end{cases} \]
其中 \(L_{\text{max}}\) 是模型最大允许生成长度(论文中设为 20480),\(L_{\text{buffer}}\) 是惩罚生效的缓冲区长度(设为 4096),\(p\) 是惩罚系数(设为 1.0)。设超长阈值 \(L_{\text{thresh}} = L_{\text{max}} - L_{\text{buffer}} = 16384\),整个长度空间被划分为三个区域:
| 区域 | 回答长度 \(\|o\|\) | 奖励处理 | 惩罚值 |
|---|---|---|---|
| 安全区 | \(\leq 16384\) | 奖励不变,模型自由发挥 | \(0\) |
| 缓冲区 | \(16384 \sim 20480\) | 惩罚随超出长度线性增长 | \(0 \to -p\) |
| 截断 | \(> 20480\) | 生成被强制终止 | — |
公式拆解:当回答长度 \(|o|\) 超过阈值时,惩罚值为:
\[ \text{penalty} = -\underbrace{\frac{|o| - L_{\text{thresh}}}{L_{\text{buffer}}}}_{\text{超出部分占缓冲区的比例}} \times p \]
- 安全区(\(|o| \leq 16384\)):奖励不变,模型可以自由发挥。
- 缓冲区(\(16384 < |o| \leq 20480\)):展开公式可以看到惩罚是 \(|o|\) 的线性函数:
\[\text{penalty} = -\frac{p}{L_{\text{buffer}}} \cdot |o| + \underbrace{\frac{L_{\text{thresh}} \cdot p}{L_{\text{buffer}}}}_{\text{常数(所有超参都是训练前确定的)}} = -\frac{1}{4096} \cdot |o| + 4\]
斜率 \(= -\frac{1}{4096}\) 恒定,即每多超出一个 Token,惩罚增加 \(\frac{1}{4096} \approx 0.000244\)。从 \(|o| = 16384\) 时的 \(0\) 增长到 \(|o| = 20480\) 时的 \(-1.0\)。 - 最终取 \(\min(r_{\text{original}},\, \text{penalty})\),确保超长回答的奖励不会高于惩罚值——即使答案正确,过长也会被惩罚。
用例子理解(\(L_{\text{max}} = 20480\),\(L_{\text{buffer}} = 4096\)):
| 回答 | Token 数 | 原始奖励 | 是否超阈值(\(20480 - 4096 = 16384\)) | 塑形后奖励 |
|---|---|---|---|---|
| \(o_1\)(简洁正确) | 500 | \(+1\) | 否 | \(+1\) |
| \(o_2\)(长但正确) | 10000 | \(+1\) | 否 | \(+1\) |
| \(o_3\)(超长正确) | 18000 | \(+1\) | 是(超出 1616) | \(\min(+1, -0.395) = -0.395\) |
| \(o_4\)(超长错误) | 19000 | \(-1\) | 是(超出 2616) | \(\min(-1, -0.639) = -1\) |
效果:超长且正确的回答反而被惩罚,迫使模型学习更简洁高效的推理路径。
完整 DAPO 算法与代码实现
算法全貌
将四项技术整合起来,DAPO 的完整训练目标为:
\[ \mathcal{J}_{\text{DAPO}}(\theta) = \mathbb{E}\left[\frac{1}{\sum_{i=1}^{G}|o_i|} \sum_{i=1}^{G}\sum_{t=1}^{|o_i|} \min\Big(r_{i,t}(\theta)\hat{A}_{i,t},\ \text{clip}\big(r_{i,t}(\theta),\, 1-\varepsilon_{\text{low}},\, 1+\varepsilon_{\text{high}}\big)\hat{A}_{i,t}\Big)\right] \]
\[ \text{s.t.} \quad 0 < \left\lvert\{o_i \mid \text{is}\_\text{correct}(a, o_i)\}\right\rvert < G \]
约束条件要求每组 \(G\) 个采样中正确回答数严格介于 \(0\) 和 \(G\) 之间(动态采样保证),使得组内标准化后的优势 \(\hat{A}_i\) 同时包含正、负信号。优势函数仍然使用 GRPO 的组内相对计算:\(\hat{A}_i = \frac{r_i - \mu_R}{\sigma_R + \epsilon}\),不依赖 Critic 网络。
符号说明:公式中 \(\hat{A}_{i,t}\) 的下标 \(t\) 仅表示该 token 位置对应的优势值。在 GRPO/DAPO 中,优势是序列级标量(由整条回答的奖励 \(r_i\) 计算),对同一回答 \(o_i\) 内的所有 token 取相同的值,即 \(\hat{A}_{i,t} = \hat{A}_i, \forall t\)。写作 \(\hat{A}_{i,t}\) 是为了与 token 级的 \(r_{i,t}\) 记号对齐。
DAPO 与 GRPO 的差异对比
| 特性 | GRPO | DAPO |
|---|---|---|
| 裁剪方式 | 对称 \([1-\varepsilon, 1+\varepsilon]\) | 非对称 \([1-\varepsilon_{\text{low}}, 1+\varepsilon_{\text{high}}]\) |
| 采样策略 | 固定 batch,包含零方差组 | 动态采样,过滤零方差组 |
| 损失归一化 | 序列级(每个回答等权) | Token 级(每个 Token 等权) |
| 长度控制 | 无 | 超长奖励惩罚 |
| KL 正则 | \(\beta \cdot \text{KL}(\pi_\theta \| \pi_{\text{ref}})\) | 移除 KL(依赖裁剪约束策略) |
DAPO 移除了 KL 散度正则项和参考模型——原因见上文 Clip-Higher 部分的分析。
完整实现代码
以下是 DAPO 的完整 PyTorch 实现,将四个技术组合为一个端到端的训练流程。
Step 1: 模型定义与超参数
DAPO 只需维护一个 Actor 模型。GRPO 额外需要一个冻结的 Reference Model 来计算 KL 惩罚;而 DAPO 的裁剪机制(Clip-Higher)已经足够约束策略更新幅度,KL 惩罚变得多余(原因详见上文 Clip-Higher 部分),移除它还能省出一个大模型的显存。
import torch
import torch.nn.functional as F
from transformers import AutoModelForCausalLM, AutoTokenizer
# DAPO 只需要 Actor,不需要参考模型(对比 GRPO: actor + ref_model)
actor = AutoModelForCausalLM.from_pretrained("Qwen2.5-32B-SFT")
tokenizer = AutoTokenizer.from_pretrained("Qwen2.5-32B-SFT")
optimizer = torch.optim.AdamW(actor.parameters(), lr=1e-6)
# ── DAPO 超参数 ──
G = 16 # 每个 Prompt 的采样数(GRPO 组大小)
eps_low = 0.2 # 裁剪下界(与标准 PPO 相同)
eps_high = 0.28 # 裁剪上界(Clip-Higher:比 PPO 更宽,促进探索)
K_epochs = 2 # 每批数据的 PPO 更新轮数
target_batch_size = 512 # 目标有效 Prompt 数
batch_multiplier = 3 # 动态采样过采样倍率
max_len = 20480 # 最大回答长度 L_max
buffer_len = 4096 # 超长惩罚缓冲区 L_bufferStep 2: 四大核心函数
def overlong_reward_shaping(rewards, response_lengths, max_len=20480,
buffer_len=4096, penalty=1.0):
"""技术四: 超长奖励塑形。超过 L_thresh 的回答线性惩罚。
Args:
rewards: [N] 原始奖励(+1 正确 / -1 错误)
response_lengths: [N] 每条回答的 token 数
max_len: 生成截断长度 L_max(默认 20480)
buffer_len: 惩罚缓冲区长度 L_buffer(默认 4096)
penalty: 最大惩罚系数 p(默认 1.0)
Returns:
shaped: [N] 塑形后的奖励
"""
threshold = max_len - buffer_len # 超长阈值 L_thresh = 20480 - 4096 = 16384
shaped = rewards.clone() # 拷贝原始奖励,避免就地修改
over_mask = response_lengths > threshold # 布尔掩码:哪些回答超过了阈值
excess = (response_lengths[over_mask] - threshold).float() # 超出阈值的 token 数(如 18000 - 16384 = 1616)
penalty_values = -(excess / buffer_len) * penalty # 线性惩罚 = -(超出量 / 缓冲区长度) × p
shaped[over_mask] = torch.min(rewards[over_mask], penalty_values) # 取 min:确保超长回答奖励不高于惩罚值
return shaped # 安全区内的回答奖励不变,超长回答被惩罚
def dynamic_sampling(model, dataset, target_size, G, batch_multiplier=3,
max_rounds=10):
"""技术二: 动态采样 — 只保留有区分度的 Prompt 组.
Args:
model: 策略模型,用于 generate。
dataset: 可 sample 的数据集。
target_size: 目标有效 Prompt 组数。
G: 每组 rollout 条数。
batch_multiplier: 过采样倍率。
max_rounds: 最大采样轮数。
Returns:
cache[:target_size]: 有效轨迹字典列表,长度 ≤ target_size。
"""
# 累积满足方差与对错混合约束的轨迹,供后续 PPO 式更新
cache = []
# 多轮过采样直到凑够有效 batch 或达到轮次上限
for round_idx in range(max_rounds):
# 一次采 multiplier 倍,抵消被过滤的零方差组
prompts = dataset.sample(target_size * batch_multiplier)
# 题目与标准答案(或用于判分的元信息)
for prompt, answer in prompts:
# 组内 G 条独立样本,估计相对优势
responses = model.generate(
prompt,
num_return_sequences=G,
max_new_tokens=max_len,
do_sample=True,
)
# 任务奖励(如对错 ±1),尚未含长度塑形
raw_rewards = judge_responses(responses, answer) # (G,)
# 各条回答长度,用于超长惩罚
lengths = torch.tensor([len(r) for r in responses]) # (G,)
# 技术四:把过长正确回答拉低奖励
rewards = overlong_reward_shaping(raw_rewards, lengths)
# 塑形后仍用 >0 区分“有效正确”条数,满足混合约束
n_correct = (rewards > 0).sum().item()
# 约束:组内既有正例也有负例,GRPO 优势分母 σ_R 非零
if 0 < n_correct < G:
# 采样时策略 π_old 的 token 对数概率,算比率用
old_logps = compute_token_log_probs(
model, prompt, responses
) # (*, T)
# 存整条轨迹,供多 epoch 重算新策略下 log π_θ
cache.append({
"prompt": prompt,
"responses": responses,
"rewards": rewards,
"old_log_probs": old_logps,
"lengths": lengths,
})
if len(cache) >= target_size:
# 已收集足够有效组,提前返回避免无效开销
return cache[:target_size]
# 未凑满时返回已有部分(工程上可配合告警或丢弃该步)
return cache[:target_size]
def compute_group_advantages(rewards_list, G):
"""GRPO 组内相对优势(与 GRPO 完全相同)。"""
rewards = torch.stack(rewards_list).reshape(-1, G) # (batch, G)
mean_r = rewards.mean(dim=1, keepdim=True)
std_r = rewards.std(dim=1, keepdim=True)
advantages = (rewards - mean_r) / (std_r + 1e-8) # z-score
return advantages.reshape(-1) # (batch*G,)
def dapo_loss(log_probs, old_log_probs, advantages, loss_mask,
eps_low=0.2, eps_high=0.28):
"""技术一 + 技术三: Clip-Higher + Token-Level 归一化。"""
ratio = torch.exp(log_probs - old_log_probs) # r_t(θ)
# 技术一: 非对称裁剪
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1.0 - eps_low, 1.0 + eps_high) * advantages
token_loss = -torch.min(surr1, surr2) # PPO 悲观下界
# 技术三: Token-Level 归一化——除以有效 Token 总数而非回答数
loss = (token_loss * loss_mask).sum() / loss_mask.sum()
return lossStep 3: 完整训练循环
for step in range(total_steps):
# ══════════ 阶段 1: 动态采样(技术二 + 技术四)══════════
batch = dynamic_sampling(
actor, dataset, target_batch_size, G, batch_multiplier
)
# ══════════ 阶段 2: 计算组内相对优势 ══════════
all_rewards = [item["rewards"] for item in batch]
advantages = compute_group_advantages(all_rewards, G) # (batch*G,)
# ══════════ 阶段 3: 多 Epoch PPO 式更新(技术一 + 技术三)══════════
for epoch in range(K_epochs):
for mini_batch in create_minibatches(batch, minibatch_size=64):
new_log_probs = compute_token_log_probs(
actor, mini_batch["prompts"], mini_batch["responses"],
) # (*, T)
old_log_probs = mini_batch["old_log_probs"] # (*, T)
adv = mini_batch["advantages"].unsqueeze(-1).expand_as(
new_log_probs
) # (*, T)
mask = mini_batch["loss_mask"] # (*, T)
# DAPO 损失(注意:没有 KL 惩罚项!)
loss = dapo_loss(
new_log_probs, old_log_probs, adv, mask,
eps_low=eps_low, eps_high=eps_high,
)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(actor.parameters(), max_norm=1.0)
optimizer.step()
# ══════════ 阶段 4: 监控(可选)══════════
with torch.no_grad():
mean_reward = torch.stack(all_rewards).mean().item()
entropy = compute_policy_entropy(actor, batch)与 GRPO 训练循环的关键区别:
动态采样替代了固定采样——过滤无效组,每次更新都有充分的梯度信号。
dapo_loss使用非对称裁剪 + Token 级归一化——不再是torch.clamp(ratio, 1-ε, 1+ε)。没有 KL 惩罚项——
loss = policy_loss而不是loss = policy_loss + β * kl_penalty。这是 DAPO 与 GRPO 最显著的差异。奖励在采样时就经过了超长塑形——长回答在进入优势计算前已被惩罚。
开源代码参考: DAPO 的官方实现基于 verl 框架,NVIDIA NeMo RL 也提供了 DAPO 训练指南。
DAPO 的训练效果
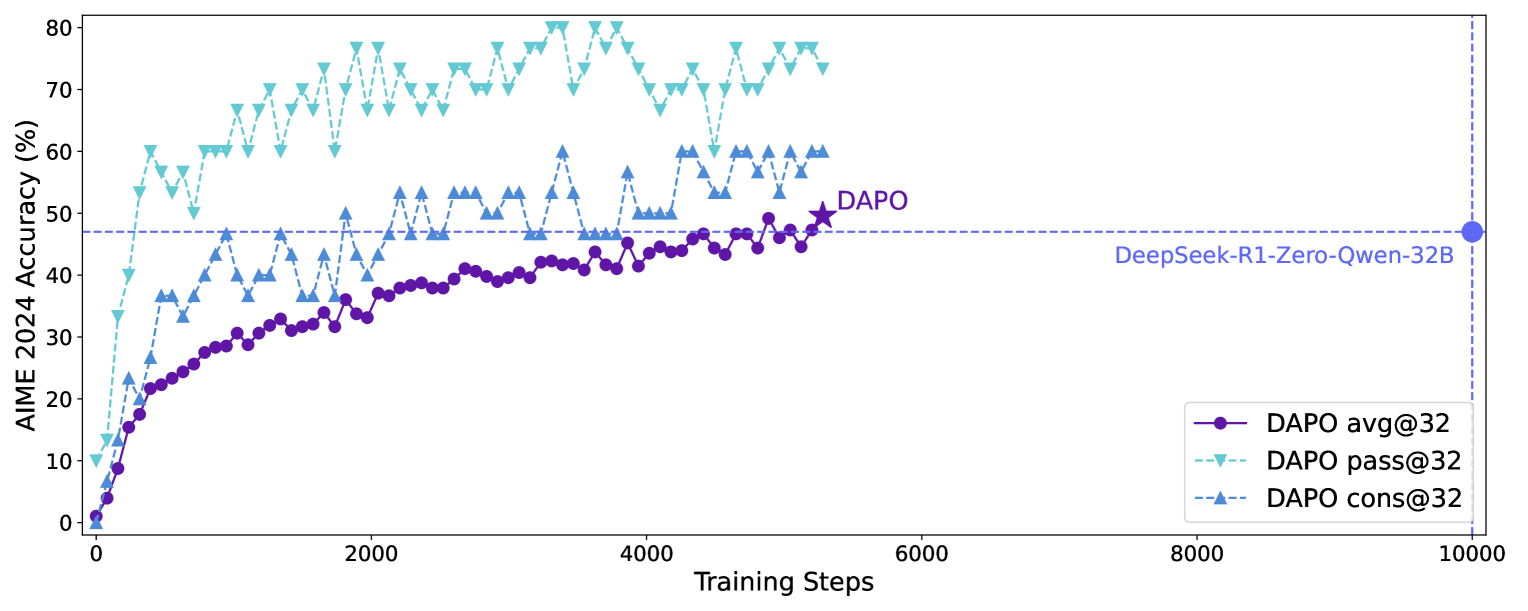
DAPO 在 Qwen2.5-32B 基座模型上的 AIME 2024 成绩:
| 方法 | AIME 2024 分数 | 训练步数 |
|---|---|---|
| 原始 GRPO | 30 | ~10000 |
| DeepSeek-R1-Zero-Qwen-32B | 47 | ~10000 |
| DAPO | 50 | ~5000 |
四项技术的消融实验(Ablation)显示每项技术都有独立贡献,其中 Clip-Higher 和 Dynamic Sampling 对性能提升最为显著。
更远的视野:2026 年 RL 前沿
DAPO 之后,强化学习领域仍在快速演进:
f-GRPO:将 GRPO 推广到通用 f-散度框架,不局限于 KL 散度,适用于安全对齐等更广泛的任务。
2-GRPO:研究发现仅用 2 个 rollout(而非 16 个)就能保留 GRPO 98.1% 的性能,训练时间降至 21%。
GIFT:融合 GRPO 的在线采样和 DPO 的隐式奖励,将优化转化为稳定的 MSE 损失。
SuperFlow:将 DAPO 类似的思想引入图像生成,使用方差感知采样和步级优势,在 SD3.5 上取得 4.6%-47.2% 的性能提升。
Flow-Factory / GenRL:统一的图像/视频生成 RL 框架,支持 T2I、T2V、I2V 多种模态。
TRL v1.0(Hugging Face, 2026.04):生产级 RL 框架,统一 SFT → Reward Modeling → Alignment(DPO/GRPO/KTO)流水线。
强化学习已经从一个"理论优美但工程复杂"的技术,演变为大模型训练不可或缺的核心环节。从 REINFORCE 的简单直觉,到 PPO 的步长控制,到 GRPO 的去 Critic 化,再到 DAPO 的工程最佳实践——每一步都在让 RL 变得更简单、更高效、更可规模化。
参考资料:
- Yu, H., Chen, X., Zhang, Y., ... & Li, Y. (2025). DAPO: An Open-Source LLM Reinforcement Learning System at Scale. arXiv:2503.14476.
- Shen, J., Wang, Z., Li, X., ... & Chen, Y. (2025). Entropy Collapse in Large Language Model Reinforcement Learning. arXiv:2509.03493.
- NVIDIA NeMo RL DAPO Guide
- Hugging Face TRL v1.0