笔记|强化学习(七):GRPO 的三重面孔——从 2-GRPO 到 f-GRPO 与 GIFT
本文为 RL 系列第七篇。上一篇介绍了 DAPO 的四大工程改进。本文从理论角度出发,剖析 GRPO 的数学本质:为什么 GRPO 其实是在做 DPO?为什么 2 个 rollout 就够了?如何从 KL 散度推广到任意 f-散度?最后介绍融合了 GRPO 和 DPO 优势的 GIFT 算法。
论文:
从一个令人意外的实验结果说起
在前几篇中,我们强调"组越大(\(G = 16\) 或 \(64\)),优势估计越准确,训练效果越好"。但 2025 年 10 月的论文 "It Takes Two" 给出了一个反直觉的结果:
性能方面:仅用 \(G = 2\)(两个 rollout)的 GRPO(记为 2-GRPO),在多项数学推理基准上保留了 16-GRPO 约 98.1% 的平均性能。
效率方面:2-GRPO 的总 rollout 生成量仅为 16-GRPO 的 12.5%,实际训练时间缩短约 79%。
| 方法 | 每 Prompt 的 rollout 数 \(G\) | 总 rollout 生成量 | 墙钟时间(Qwen-1.5B / MATH) | 平均性能保留率 |
|---|---|---|---|---|
| 16-GRPO | 16 | 100%(约 1.2M) | 100%(8.53 h) | 基准 |
| 2-GRPO | 2 | 12.5%(约 0.15M) | 24.0%(2.05 h) | 98.1% |
这说明 GRPO 的核心力量不在于"大组 → 精确基线估计",而在于别的什么东西。那到底是什么?
第一重面孔:GRPO 即在线 DPO(2-GRPO 的视角)
GRPO 梯度的对比学习本质
用数学积分题的例子。让模型用 \(G = 4\) 个方式解 \(\int_0^1 x^2 dx\),得到 2 个正确(\(r = 1\))和 2 个错误(\(r = 0\))。经 z-score 标准化后:正确回答优势 \(\hat{A}_i = +1\)(鼓励),错误回答优势 \(\hat{A}_i = -1\)(抑制)。
GRPO 完整目标函数的推导见第四篇。这里我们省略裁剪和 KL 项,直接看在每次更新起点(\(\theta = \theta_{\text{old}}\))时的策略梯度:
\[ \hat{g}_{\text{GRPO}} = \frac{1}{G}\sum_{i=1}^{G} \hat{A}_i \nabla_\theta \log \pi_\theta(o_i | q) \]
将回答分为正确组 \(\mathcal{G}^+\)(\(G^+\) 个)和错误组 \(\mathcal{G}^-\)(\(G^-\) 个),上式改写为:
\[ \hat{g}_{\text{GRPO}} \propto \underbrace{\frac{1}{G^+}\sum_{o \in \mathcal{G}^+} \nabla_\theta \log \pi_\theta(o | q)}_{\text{增加正确回答的概率}} - \underbrace{\frac{1}{G^-}\sum_{o \in \mathcal{G}^-} \nabla_\theta \log \pi_\theta(o | q)}_{\text{减少错误回答的概率}} \]
这与 DPO 的对比学习结构在形式上是一致的。 主要区别在于:
| DPO | GRPO | |
|---|---|---|
| 正负对来源 | 人类标注的固定偏好对 \((y_w, y_l)\) | 模型在线采样 + 奖励判题动态划分 |
| 对比结构 | 固定 1-vs-1 | 动态 \(N\)-vs-\(M\)(\(N = G^+\),\(M = G^-\)) |
| 学习方式 | 离线 | 在线 |
为什么对比配对能缩减方差?
仅使用正样本梯度(即 REINFORCE 的做法)当然可以,但方差会很大。GRPO 减去负样本梯度的做法,本质上是蒙特卡罗估计中经典的控制变量法(control variate method):
因为正样本 \(o^+\) 和负样本 \(o^-\) 都是同一模型对同一 Prompt 生成的回答,它们共享 Prompt 的上下文信息,梯度之间存在正相关性。根据控制变量理论,配对估计 \(\boldsymbol{g}^+ - c \cdot \boldsymbol{g}^-\) 的方差为 \((1 - \rho^2) \cdot \text{Var}(\boldsymbol{g}^+)\),其中 \(\rho\) 是二者的相关系数。只要 \(\rho > 0\),方差就严格小于仅用正样本的方差。
这解释了 GRPO 为什么要在同一 Prompt 的同一组内做对比——目的不是为了更精确的均值估计,而是利用同源配对的正相关性来降低策略梯度估计量的方差。
2-GRPO:最小对比单元
既然 GRPO 的核心是对比,那对比的最小单元就是 2 个 rollout。当 \(G = 2\) 且 \(r_1 \neq r_2\) 时(一对一错),经 z-score 标准化后优势退化为 \(\hat{A}_1 = +1, \hat{A}_2 = -1\)——其梯度结构与在线版的 DPO 更新一致。
2-GRPO 的核心优势:在相同总 rollout 预算下,2-GRPO 可覆盖更多 Prompt(如 256 个 vs 标准 GRPO 的 32 个),Prompt 多样性提升 8 倍。论文的核心论点是:GRPO 的有效性源于其隐含的对比学习机制(正负样本配对),而非大组带来的优势估计精度。
2-GRPO 的核心实现非常简洁——与标准 GRPO 的唯一区别在于 \(G = 2\) 以及用更多 Prompt 补偿:
actor = AutoModelForCausalLM.from_pretrained("sft_checkpoint")
ref_model = AutoModelForCausalLM.from_pretrained("sft_checkpoint")
ref_model.requires_grad_(False)
optimizer = torch.optim.AdamW(actor.parameters(), lr=1e-6)
G, clip_eps, beta = 2, 0.2, 0.04
for step in range(total_steps):
# 2-GRPO 用更多 Prompt 补偿 G 的减少,保持总 rollout 预算不变
# 标准 GRPO: 32 prompts × 16 rollouts = 512; 2-GRPO: 256 × 2 = 512
prompts = sample_prompts(dataset, batch_size=256)
# ---- 阶段 1: 采样(无梯度) ----
with torch.no_grad():
all_resp, all_rewards, all_old_logps, all_ref_logps = [], [], [], []
for prompt in prompts:
for _ in range(G):
resp = actor.generate(prompt, do_sample=True)
all_resp.append(resp)
all_rewards.append(reward_fn(prompt, resp))
all_old_logps.append(compute_token_log_probs(actor, prompt, resp))
all_ref_logps.append(compute_token_log_probs(ref_model, prompt, resp))
# ---- 阶段 2: 计算优势 ----
rewards = torch.tensor(all_rewards).reshape(-1, G) # (B, 2)
valid = rewards[:, 0] != rewards[:, 1] # 只保留一对一错的组
if valid.sum() == 0:
continue
mean_r = rewards[valid].mean(dim=1, keepdim=True)
std_r = rewards[valid].std(dim=1, keepdim=True) + 1e-8
advantages = ((rewards[valid] - mean_r) / std_r).reshape(-1) # G=2 → 恒为 ±1
# ---- 阶段 3: PPO 式裁剪更新(多 epoch) ----
for epoch in range(K_epochs):
new_logps = compute_token_log_probs(actor, prompts_valid, responses_valid)
ratio = torch.exp(new_logps - old_logps_valid) # π_θ / π_old
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - clip_eps, 1 + clip_eps) * advantages
policy_loss = -torch.min(surr1, surr2).mean()
kl_penalty = beta * (new_logps - ref_logps_valid).mean() # KL(π_θ || π_ref)
loss = policy_loss + kl_penalty
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(actor.parameters(), max_norm=1.0)
optimizer.step()2-GRPO 的局限性
"硬币的另一面"是:当奖励函数存在系统性偏差时,\(G = 2\) 的 pairwise 结构会将偏差放大。
核心问题是 符号放大:\(G = 2\) 时 z-score 标准化恒为 \(\pm 1\),RM 的微小评分误差(如 \(0.8\) vs \(0.6\))被映射为最大强度的训练信号。而 \(G = 16\) 时,优势值保持连续且不等(如 \(+1.5, +0.8, -0.3, -1.2, \ldots\)),单个评分错误只会略微扭曲优势分布。
要点:2-GRPO 的效率优势在 RLVR(可验证奖励)场景下最为显著且安全,因为二值奖励(对/错)消除了 RM 偏差风险。在依赖学习型 RM 的场景(如开放式对话),需要注意偏差放大问题,可考虑置信度阈值过滤、软优势替代硬符号等缓解策略。
第二重面孔:从 KL 到任意 f-散度(f-GRPO)
为什么要超越 KL 散度?
标准 GRPO 使用 KL 散度 \(D_{\text{KL}}(\pi_\theta \| \pi_{\text{ref}})\) 来限制策略偏离参考模型。但 KL 散度有其"偏心":
在 \(D_{\text{KL}}(\pi_\theta \| \pi_{\text{ref}})\) 中,\(\pi_\theta\) 在第一个参数位置,对应的是反向 KL(Mode-Seeking / 模式专精)——模型倾向于只精通一种最高分的解法,完全放弃其他解法。这种特性虽然能快速拿高分,但容易导致模型过早"塌缩"到某一种回答模式。
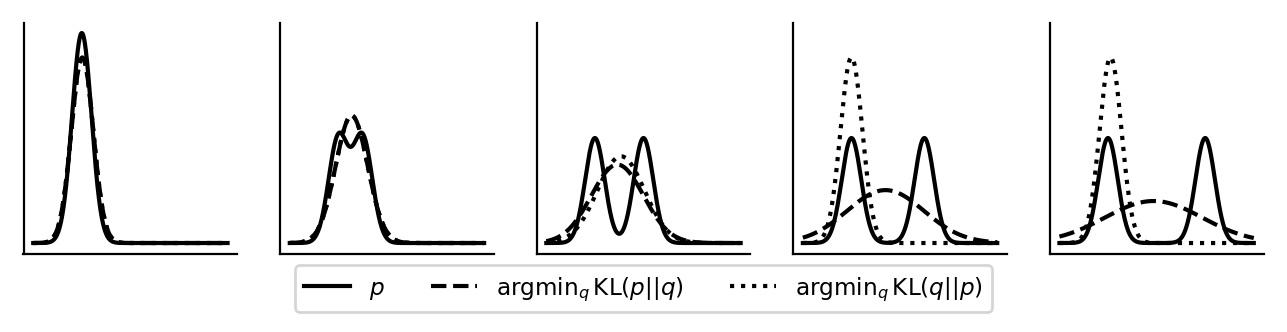
不同的散度衡量"两个模型差多远"的尺子不同,换一把尺子能让训练过程的梯度方向更高效、更稳定:
| 散度类型 | 在 GRPO 中的通俗表现 |
|---|---|
| KL(反向) | 专精型(可丢弃其他解法),标准 GRPO 的默认选择 |
| 逆 KL(前向) | 全能型(必须覆盖老模型的所有解法) |
| Pearson \(\chi^2\) | 严打型(对离谱的错误回答给予二次方暴击惩罚),实验中表现最优 |
| Hellinger | 温和型(惩罚有上限,防止梯度爆炸,训练极稳) |
| Jensen–Shannon (JS) | 对称型(有界且平滑,不偏心) |
f-GRPO 的核心思想
标准 GRPO 对好回答(正优势)和坏回答(负优势)使用相同的
clip 裁剪规则(只是符号相反)。f-GRPO
提出一个核心洞察:鼓励好回答和抑制坏回答,应该使用两套完全不同的数学规则。
f-GRPO 的损失函数对正组和负组施加不同形式的处理:
\[ \mathcal{L}_{\text{f-GRPO}}(\theta) = \mathbb{E} \left[ \frac{1}{\sum_{i=1}^{G} |y_i|} \sum_{i=1}^G \sum_{t=1}^{|y_i|} |a_i| \cdot \begin{cases} -g(r_{\theta,i,t}) & \text{if } a_i > 0 \quad \text{(好回答)} \\[4pt] +f^* \circ g(r_{\theta,i,t}) & \text{if } a_i \le 0 \quad \text{(坏回答)} \end{cases} \right] \]
其中:
- \(r_{\theta,i,t} = \beta \ln \frac{\pi_\theta}{\pi_{\text{ref}}}\):隐式奖励,模型越倾向于输出该回答,值越高
- \(a_i = \hat{A}_i\):优势值,正数归入正组,负数归入负组
- \(g(\cdot)\):链接函数,将隐式奖励转换到 \(f^*\) 可接受的定义域
- \(f^*(\cdot)\):Fenchel 共轭,不同的 f-散度推导出不同的 \(f^*\),决定了如何惩罚坏回答
不同散度对应的正/负组规则:
| f-散度 | 正组(好回答) | 负组(坏回答) | 通俗特点 |
|---|---|---|---|
| Pearson \(\chi^2\) | \(-r_\theta\) | \(r_\theta + r_\theta^2/4\) | 二次暴击:坏回答越自信,惩罚呈平方级爆炸 |
| Hellinger | \(-(1 - e^{-r_\theta})\) | \(\frac{1-e^{-r_\theta}}{e^{-r_\theta}}\) | 见好就收:正侧奖励有上限,防过度自信 |
| 逆 KL | \(-r_\theta\) | \(-1 - \ln(-r_\theta)\) | 对数惩罚:比较温和的常规惩罚 |
f-GRPO 与标准 GRPO 的关系
f-GRPO 并不是对 GRPO 损失函数的微调——它重写了整个优化框架,只保留了 GRPO 的采样与分组策略:
| 标准 GRPO | f-GRPO | |
|---|---|---|
| 继承 | 每个 Prompt 采 \(G\) 个回答,按优势分正/负组 | 相同 |
| 策略比率 | PPO 风格 \(\rho = \pi_\theta / \pi_{\theta_\text{old}}\) | 隐式奖励 \(r_\theta = \beta \log(\pi_\theta / \pi_{\text{ref}})\) |
| 裁剪 | \(\text{clip}(\rho, 1\!-\!\varepsilon, 1\!+\!\varepsilon)\) | 无 |
| 正/负组处理 | 相同函数,仅由 \(\hat{A}_i\) 符号区分 | 不同函数:正组 \(g\),负组 \(f^* \circ g\) |
| KL 惩罚 | 显式 \(\beta D_{\text{KL}}\) 项 | 隐含在 \(r_\theta\) 的定义中 |
| 理论根基 | 策略梯度 + PPO 代理目标 | f-散度变分表示 |
实验结果
f-GRPO 在 Qwen2.5-Math 1.5B 上的数学推理实验中,所有测试的 f-散度变体都优于标准 GRPO(数据摘自论文 Table 2,LIMR 数据集):
| f-散度 | Relative Overall \(\uparrow\) | 与 GRPO 差值 | 平均排名 \(\downarrow\) |
|---|---|---|---|
| GRPO(KL baseline) | 74.26 | — | 5.2 |
| Pearson \(\chi^2\) | 86.49 | +12.23 | 2.6 |
| Total Variation | 83.11 | +8.85 | 3.8 |
| 逆 KL | 82.47 | +8.21 | 3.0 |
| KL(前向) | 81.83 | +7.57 | 4.4 |
| Hellinger | 81.11 | +6.85 | 4.2 |
| JS | 78.99 | +4.73 | 4.2 |
指标说明:Relative Overall 定义为各基准(GSM8K、MATH-500、AMC 2023、AIME 2024、AIME 2025)上 Pass@1 准确率分别做 min-max 归一化至 \([0, 100]\) 后的算术平均。Pearson \(\chi^2\) 在此设定下表现最优,但论文也指出不同数据集和模型规模下最优散度并不一致。
注意表格中的"KL(前向)"行:它比标准 GRPO 高出 7.57 分。同样是 KL 散度,效果不同是因为两者用法不同——标准 GRPO 将 KL 用作 PPO 裁剪损失后的惩罚项,而 f-GRPO 用 KL 的变分表示来设计损失函数本身。
以表现最好的 Pearson \(\chi^2\) 为例,f-GRPO 的核心损失计算:
def f_grpo_loss(log_probs, ref_log_probs, advantages, loss_mask, beta=0.1):
"""f-GRPO 损失(Pearson χ² 散度):对坏回答的过度自信给予二次方暴击。"""
implicit_reward = beta * (log_probs - ref_log_probs) # r_θ = β·log(π_θ/π_ref)
pos_mask = (advantages > 0).float().unsqueeze(-1) * loss_mask
neg_mask = (advantages <= 0).float().unsqueeze(-1) * loss_mask
pos_loss = -implicit_reward # 正侧: 常规鼓励
neg_loss = implicit_reward + implicit_reward ** 2 / 4 # 负侧: 二次方暴击
abs_adv = advantages.abs().unsqueeze(-1)
loss = pos_loss * pos_mask * abs_adv + neg_loss * neg_mask * abs_adv
return loss.sum() / loss_mask.sum()
# ---- 训练循环(采样阶段与 GRPO 完全一致,只替换损失函数) ----
actor = AutoModelForCausalLM.from_pretrained("sft_checkpoint")
ref_model = AutoModelForCausalLM.from_pretrained("sft_checkpoint")
ref_model.requires_grad_(False)
optimizer = torch.optim.AdamW(actor.parameters(), lr=1e-6)
for step in range(total_steps):
# 采样 + 计算优势(与标准 GRPO 完全相同,此处省略)
# ...得到 prompts, responses, advantages, ref_log_probs, loss_mask
# f-GRPO 不需要 old_logps 和重要性采样,直接前向计算
new_log_probs = compute_token_log_probs(actor, prompts, responses)
loss = f_grpo_loss(new_log_probs, ref_log_probs, advantages, loss_mask)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(actor.parameters(), max_norm=1.0)
optimizer.step()第三重面孔:隐式奖励回归(GIFT)
GRPO 和 DPO 各自的不足
| GRPO | DPO | |
|---|---|---|
| 优势 | 在线采样,能探索新回答 | 稳定,MSE 式损失 |
| 不足 | 裁剪超参数敏感,易过拟合 | 离线,无法探索 |
有没有办法结合两者的优点?GIFT 给出了一个优雅的方案:大模型的对齐训练其实可以变得非常简单——它不过是在做均方误差(MSE)回归。
GIFT 的核心洞察:消灭 \(Z(x)\)
DPO 证明了模型内部隐藏着一个"隐式奖励":
\[ r_\theta(x, y) = \beta \log \frac{\pi_\theta(y | x)}{\pi_{\text{ref}}(y | x)} + \beta \log Z(x) \]
其中 \(Z(x)\) 是配分函数——需要把模型对问题 \(x\) 所有可能回答的概率都加起来,计算上不可能完成。正是因为这个"拦路虎",DPO 只能让两个回答"打擂台"(相减时 \(Z(x)\) 被抵消)。
GIFT 的发现:只要对同一问题的一组回答做组内标准化,\(Z(x)\) 和 \(\beta\) 就会依次消失!
先回顾 \(\beta\) 的来源。在 KL 约束的 RL 问题 \(\max_\theta \mathbb{E}[r(x,y)] - \beta \cdot D_{\text{KL}}(\pi_\theta \| \pi_{\text{ref}})\) 中,\(\beta\) 是控制策略偏离参考模型程度的温度系数。DPO 证明了该问题的最优策略满足:
\[ r(x, y) = \beta \log \frac{\pi^*(y|x)}{\pi_{\text{ref}}(y|x)} + \beta \log Z(x) \]
因此隐式奖励 \(r_\theta(x, y_i)\) 的每一项都带有 \(\beta\) 这个公因子。下面的标准化分两步消除 \(Z(x)\) 和 \(\beta\):
第一步:减去均值 → 消除 \(Z(x)\)
将 \(G\) 个回答的隐式奖励展开:
\[ r_\theta(x, y_i) = \underbrace{\beta \log \frac{\pi_\theta(y_i|x)}{\pi_{\text{ref}}(y_i|x)}}_{\text{因回答 } y_i \text{ 而不同}} + \underbrace{\beta \log Z(x)}_{\text{对同一 prompt 为常数}} \]
对 \(G\) 个回答求均值时,变化部分被平均,而常数 \(\beta \log Z(x)\) 原样保留:
\[ \mu_\theta = \frac{1}{G}\sum_{i=1}^G \beta \log \frac{\pi_\theta(y_i|x)}{\pi_{\text{ref}}(y_i|x)} + \beta \log Z(x) \]
相减后,两边共享的 \(\beta \log Z(x)\) 被抵消,只剩下变化部分的去均值:
\[ r_\theta(x, y_i) - \mu_\theta = \beta \underbrace{\left[\log \frac{\pi_\theta(y_i|x)}{\pi_{\text{ref}}(y_i|x)} - \frac{1}{G}\sum_{j=1}^G \log \frac{\pi_\theta(y_j|x)}{\pi_{\text{ref}}(y_j|x)}\right]}_{\triangleq\; \Delta_i \;\text{(去均值后的对数概率比)}} \]
第二步:除以标准差 → 消除 \(\beta\)
减均值后的结果是 \(\beta \cdot \Delta_i\),整体都乘以 \(\beta\)。标准差的基本性质是 \(\text{std}(c \cdot X) = |c| \cdot \text{std}(X)\)(常数提到外面),因此:
\[ \sigma_\theta = \text{std}\!\left(\{r_\theta(x, y_i)\}_{i=1}^G\right) = \text{std}\!\left(\{\beta \cdot \Delta_i\}_{i=1}^G\right) = \beta \cdot \text{std}\!\left(\{\Delta_i\}\right) \]
除法时,分子的 \(\beta\) 和分母的 \(\beta\) 对消:
\[ \hat{r}'_\theta(x, y_i) = \frac{\beta \cdot \Delta_i}{\beta \cdot \text{std}(\{\Delta_j\})} = \frac{\Delta_i}{\text{std}(\{\Delta_j\})} \]
最终得到一个既不含 \(Z(x)\)、也不含 \(\beta\) 的纯净隐式奖励——它只取决于当前策略和参考策略的对数概率比在组内的相对位置。
GIFT vs GRPO 的归一化区别:
- GRPO 归一化的是外部奖励(z-score 标准化 \(\to\) 优势值),目的是取代 Critic 网络,本质仍是策略梯度。
- GIFT 同时归一化隐式奖励和外部奖励,目的是消灭配分函数 \(Z(x)\),从而将 RL 降维为监督回归。
GIFT 的损失函数:大道至简的 MSE
消灭 \(Z(x)\) 后,训练变得无比简单——强迫模型心里的打分去逼近外部裁判的打分:
\[ \mathcal{L}_{\text{GIFT}}(\pi_\theta) = \mathbb{E}_{(x, y) \sim \text{on-policy}}\left[\left(r'_\phi(x, y) - \hat{r}'_\theta(x, y)\right)^2\right] \]
其中 \(r'_\phi\) 是外部奖励(归一化后),\(\hat{r}'_\theta\) 是隐式奖励(归一化后)。
一个具体的例子:
| 回答 | 裁判打分(\(r'_\phi\)) | 模型打分(\(\hat{r}'_\theta\)) | 损失 | 模型的内心活动 |
|---|---|---|---|---|
| \(y_1\)(正确简洁) | +1.22 | +1.15 | \(\approx 0\) | "裁判觉得好,我也觉得好,不用改。" |
| \(y_2\)(正确冗长) | +0.41 | +0.23 | \((0.41-0.23)^2\) | "裁判觉得还行,我给低了,要提高概率。" |
| \(y_3\)(错误) | -0.82 | -0.69 | \((-0.82+0.69)^2\) | "裁判觉得差,我给高了,要降低概率。" |
GIFT vs GRPO vs DPO
| 特性 | GRPO | DPO | GIFT |
|---|---|---|---|
| 核心动作 | 算优势值,做策略梯度 | 两个回答打擂台对比 | 算分数差,做 MSE 回归 |
| 在线生成新回答? | ✓ | ✗ | ✓ |
| 需要裁剪 clip? | ✓(需要设 \(\varepsilon\)) | ✗ | ✗(MSE 天然稳定) |
| 需要参考模型? | ✓ | ✓ | ✓(但 \(\beta\) 和 \(Z(x)\) 被消除) |
| 数学稳定性 | 容易剧烈震荡 | 中等 | 极高(MSE 是凸函数) |
实验效果:GIFT 论文指出,在 7B 模型上,GIFT 在 AlpacaEval 和 Arena-Hard 上的胜率大幅超越了标准 GRPO,证明了回归方法在 LLM 对齐中的巨大潜力。
GIFT 的损失函数极为简洁——组内归一化 + MSE:
def gift_loss(log_probs, ref_log_probs, rewards):
"""GIFT: 组内标准化消除 Z(x) 和 β,然后用 MSE 回归。"""
# r_θ = β·log(π_θ/π_ref) + β·log Z(x),此处省略 β(标准化后会被消掉)
implicit_rewards = log_probs - ref_log_probs # (B, G), 带梯度
# 减均值: β·log Z(x) 是 prompt 级常数,G 个回答共享 → 相减时抵消
# 除标准差: std(β·X) = β·std(X),分子分母的 β 对消
impl_norm = (implicit_rewards - implicit_rewards.mean(dim=1, keepdim=True)) \
/ (implicit_rewards.std(dim=1, keepdim=True) + 1e-8)
rew_norm = (rewards - rewards.mean(dim=1, keepdim=True)) \
/ (rewards.std(dim=1, keepdim=True) + 1e-8)
return F.mse_loss(impl_norm, rew_norm.detach()) # MSE 回归
# ---- 训练循环 ----
actor = AutoModelForCausalLM.from_pretrained("sft_checkpoint")
ref_model = AutoModelForCausalLM.from_pretrained("sft_checkpoint")
ref_model.requires_grad_(False)
optimizer = torch.optim.AdamW(actor.parameters(), lr=1e-6)
G = 8
for step in range(total_steps):
prompts = sample_prompts(dataset, batch_size=32)
# 阶段 1: 在线采样(与 GRPO 完全相同)
with torch.no_grad():
all_resp, all_rewards, all_ref_logps = [], [], []
for prompt in prompts:
for _ in range(G):
resp = actor.generate(prompt, do_sample=True)
all_resp.append(resp)
all_rewards.append(reward_fn(prompt, resp))
all_ref_logps.append(compute_seq_log_prob(ref_model, prompt, resp))
rewards = torch.tensor(all_rewards).reshape(-1, G) # (B, G)
ref_logps = torch.stack(all_ref_logps).reshape(-1, G) # (B, G)
valid = rewards.std(dim=1) > 0 # 过滤零方差组
# 阶段 2: GIFT 更新(无多 epoch、无裁剪、无重要性采样)
for idx in valid.nonzero(as_tuple=True)[0]:
log_probs = torch.stack([
compute_seq_log_prob(actor, prompts[idx], r) for r in all_resp_groups[idx]
]).unsqueeze(0) # (1, G), 带梯度
loss = gift_loss(log_probs, ref_logps[idx].unsqueeze(0), rewards[idx].unsqueeze(0))
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(actor.parameters(), max_norm=1.0)
optimizer.step()GIFT vs GRPO 实现差异:GIFT 不需要裁剪(clip)、不需要重要性采样(\(\pi_\theta / \pi_{\theta_\text{old}}\))、不需要显式 KL 惩罚。KL 约束被隐含在参考模型的对数概率中。代价是每步都需要重新前向传播,不能像 PPO/GRPO 那样多 epoch 复用旧数据。
三重面孔的统一视角
| 视角 | 核心思想 | 代表方法 |
|---|---|---|
| 对比学习 | GRPO ≈ 在线版 DPO,核心是正负对比 | 2-GRPO |
| f-散度优化 | GRPO 的正负划分 ≈ f-散度变分表示的两侧 | f-GRPO |
| 隐式奖励回归 | 组内归一化消除配分函数,变为 MSE 回归 | GIFT |
这三种视角不是互斥的——它们从不同的数学工具出发,揭示了 GRPO 优化行为的不同侧面:
- 设计更高效的算法(2-GRPO:减少 rollout 数量)
- 选择更好的散度(f-GRPO:用 Pearson \(\chi^2\) 替代 KL)
- 构建更稳定的训练(GIFT:MSE 替代裁剪策略梯度)
参考资料:
- It Takes Two: Your GRPO Is Secretly DPO
- f-GRPO and Beyond: Divergence-Based RL for General LLM Alignment
- GIFT: Group-relative Implicit Fine Tuning
- How RLHF Amplifies Sycophancy
- Pref-GRPO: Pairwise Preference Reward-based GRPO
- KL-Regularized RL is Designed to Mode Collapse
- Demystifying GRPO: Its Policy Gradient is a U-Statistic