笔记|生成模型(十五):Flux 架构解析
本文为生成模型系列第十五篇。继 Stable Diffusion 3(SD3)之后,由原 SD 核心团队创立的 Black Forest Labs 推出了 Flux 系列模型。Flux 沿用了 Flow Matching 与 Diffusion Transformer(DiT)的底层框架,但在特征对齐、位置编码、网络结构以及蒸馏策略上进行了深度的重构与优化。本文将从数学原理与网络设计的角度,全面解析 Flux 的核心架构。
⬅️ 上一篇:笔记|生成模型(十四):Stable Diffusion 3 架构解析 (MMDiT)
➡️ 下一篇:笔记|强化学习(一):强化学习基础与策略梯度
一、 引言:Flux 的定位与变体
在 2024 年 8 月发布时,FLUX.1 是开源社区规模最大的文本到图像(Text-to-Image)生成模型之一 [1]。相比于 2B 参数量级的 SD3,FLUX.1 将 Transformer 骨干网络的参数量大幅扩展至 12B(120 亿)。相关研究表明,这种对模型容量的暴力扩展(Scaling up)能够显著提升模型对复杂物理规律、空间关系以及长文本指令的遵循能力 [3, 5]。
FLUX.1 包含三个主要变体,它们共享相同的 12B 参数基础架构,但在推理效率与开源协议上有所不同:
- FLUX.1 [pro]:闭源的最强基座模型,采用标准的无分类器指引(Classifier-Free Guidance, CFG)进行多步采样。
- FLUX.1 [dev]:开源非商用版本。通过指引蒸馏(Guidance Distillation)技术 [6],将 CFG 的双路前向计算压缩为单路,在保持生成质量的同时将推理效率提升一倍。
- FLUX.1 [schnell]:开源商用版本(Apache 2.0)。通过潜空间对抗扩散蒸馏(LADD)技术 [7],将原本需要数十步的采样过程极速压缩至 1~4 步。
二、 Flux 整体架构与数据流解析
Flux 的核心架构是一种混合了双流(Double Stream)与单流(Single Stream)的 Transformer 网络 [5]。我们首先通过数据流的视角,梳理其从文本/图像输入到最终输出的完整计算图。
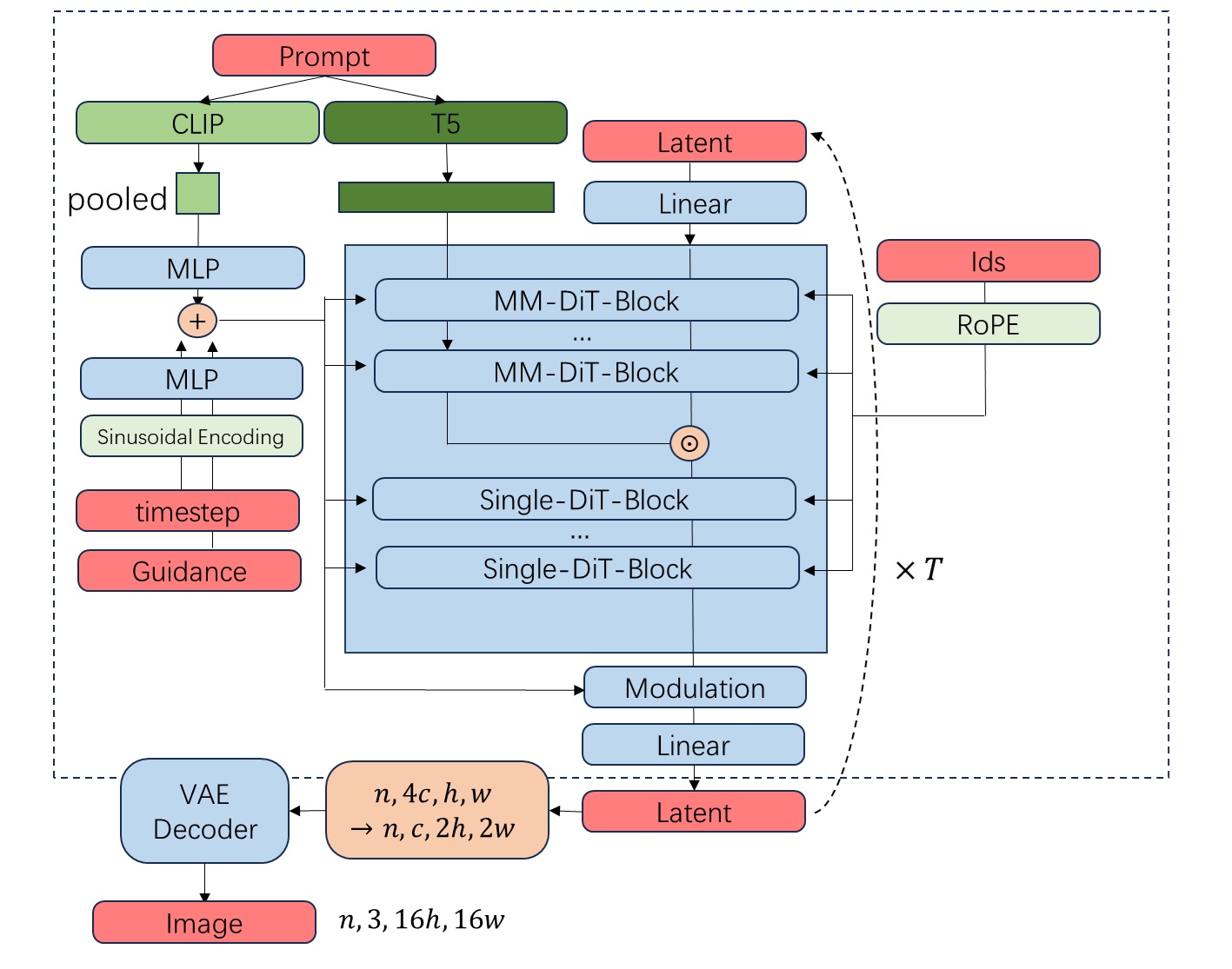
2.1 文本编码与全局条件注入(Text Encoding & Conditioning)
Flux 采用了双文本编码器策略,但相比 SD3 进行了精简,移除了 OpenCLIP-bigG,仅保留 CLIP-L/14 与 T5-v1.1-XXL [5]。
Token 级特征(细粒度语义):T5-XXL 提取长度为 512 的文本特征序列,主要负责长指令遵循与复杂逻辑解析。该序列将直接作为 Transformer 的文本流输入。
全局条件向量(Global Conditioning Vector):模型需要一个全局向量来统领整个生成过程。Flux 将以下三种标量/向量映射到相同的隐藏维度(3072维)并求和,构建出统一的全局条件向量 \(\mathbf{c}_{\text{global}}\)(在 diffusers 源码中常被称为
temb):- 时间步 \(t\):经过正弦位置编码(Sinusoidal Embedding)与 MLP 映射。
- 指引强度 \(s\)(仅限 [dev] 版本):同样经过正弦编码与 MLP 映射。
- 全局文本语义:CLIP-L 提取的 Pooled Output 经 MLP 映射。
\[ \mathbf{c}_{\text{global}} = \text{MLP}(\text{Sinusoidal}(t)) + \text{MLP}(\text{Sinusoidal}(s)) + \text{MLP}(\text{CLIP}_{\text{pooled}}) \]
这个 \(\mathbf{c}_{\text{global}}\) 向量极其关键,它将通过自适应层归一化(Adaptive Layer Normalization, AdaLN)机制 [8],在 Transformer 的每一层中动态调制(Modulate)特征的缩放(Scale)与平移(Shift)。
2.2 图像潜空间与 Pixel Unshuffle
在图像输入端,Flux 使用预训练的 VAE 将 RGB 图像压缩到潜空间(Latent Space)。假设输入图像分辨率为 \(H \times W\),VAE 编码后的 Latent 形状为 \(C \times \frac{H}{8} \times \frac{W}{8}\)(Flux 中 \(C=16\)),记 \(h = \frac{H}{8}\),\(w = \frac{W}{8}\)。
为了将 2D 的 Latent 转换为 Transformer 所需的 1D Token 序列 \((B, L, D)\),传统方法(如 ViT [11] 或 SD3 [8])通常使用步长与核大小相同的卷积层(Patch Embedding)。而 Flux 摒弃了卷积,采用了一种无参数的 Pixel Unshuffle(又称 Space-to-Depth)操作 [5, 12]:将空间维度上 \(2 \times 2\) 的相邻像素块展平,并堆叠至通道维度。
从 4D Latent 到 \((B, L, D)\) Token 序列的完整流程包含三步:
第一步:Pixel Unshuffle — 空间换通道。 将每 \(2 \times 2\) 的空间邻域折叠进通道维度。这是一个纯粹的张量重排(双射操作),不含任何可学习参数:
\[ (N, 16, h, w) \xrightarrow{\text{PixelUnshuffle}(r{=}2)} (N,\ 16 \times 2 \times 2,\ \frac{h}{2},\ \frac{w}{2}) = (N, 64, \frac{h}{2}, \frac{w}{2}) \]
此时张量仍为 4D 形式,空间分辨率减半,通道数增为原来的 4 倍。每个空间位置现在"看到"了原始 \(2 \times 2\) 邻域的全部信息。
第二步:Flatten 空间维度 — 得到 Token 序列。 将后两个空间维度展平为序列长度 \(L\):
\[ (N, 64, \frac{h}{2}, \frac{w}{2}) \xrightarrow{\text{flatten}} (N,\ \underbrace{\frac{h}{2} \times \frac{w}{2}}_{L},\ \underbrace{64}_{D'}) \]
至此已得到 \((B, L, D')\) 形式的 Token 序列,其中 \(L = \frac{hw}{4}\) 为 Token 数量,\(D' = 64\) 为每个 Token 的初始特征维度。
第三步:线性投影 — 对齐 Transformer 隐藏维度。
通过一个线性层 nn.Linear(64, 3072) 将每个 Token 从 64
维映射到 Transformer 的工作维度 \(D =
3072\):
\[ (N, L, 64) \xrightarrow{\text{Linear}} (N, L, 3072) \]
在 Flux 官方源码 [5] 中,上述三步被 einops 的
rearrange与一个线性层简洁地实现为:python# sampling.py — prepare():Pixel Unshuffle + Flatten(一步完成) img = rearrange(img, "b c (h ph) (w pw) -> b (h w) (c ph pw)", ph=2, pw=2) # model.py — Flux.__init__():线性投影 self.img_in = nn.Linear(self.in_channels, self.hidden_size) # Linear(64, 3072)
为什么不直接 Flatten? 如果不做 Pixel Unshuffle,直接将 \((N, 16, h, w)\) 展平为 \((N, h \times w, 16)\),每个空间像素各自成为一个 Token,则序列长度为 \(h \times w\)。而 Transformer 自注意力的计算量为 \(O(L^2)\),对序列长度极其敏感:
| 方案 | Token 数 \(L\) | 注意力 FLOPs(相对值) |
|---|---|---|
| 直接 Flatten(不做 Patch) | \(h \times w\) | \(1\times\) |
| Pixel Unshuffle(\(2 \times 2\) Patch) | \(\frac{hw}{4}\) | \(\frac{1}{16}\times\) |
以 1024×1024 图像为例,VAE 编码后 Latent 尺寸为 128×128。不做 Patch 将产生 16384 个 Token;做 \(2\times2\) 合并后仅 4096 个 Token——注意力计算量降至 \(\frac{1}{16}\)。
为什么 Patch 大小是 \(2 \times 2\) 而不是更大? 需要注意,Flux 的 Patchification 操作在潜空间(Latent Space)而非像素空间中进行。原始 ViT [11] 在像素空间使用 \(16 \times 16\) 的 Patch 是因为输入分辨率高达 \(224 \times 224\);而 Flux 的输入已经过 VAE 的 \(8\times\) 下采样(如 1024×1024 图像被压缩至 128×128 的 Latent),空间信息已高度压缩。在此基础上再用大 Patch 会造成严重的信息损失。
Peebles & Xie (2023) [13] 在 DiT(Diffusion Transformer)中系统地对比了 Patch 大小为 8、4、2 三种配置,发现:Patch 越小,Token 数越多,生成质量(FID)越好。其最优模型 DiT-XL/2 正是使用 \(2 \times 2\) Patch。(Wang et al., 2025) 进一步发现了 Patchification 的 Scaling Law:减小 Patch 大小可以一致性地提升性能,理论最优为 \(1 \times 1\)(像素级 Token 化)。但 \(1 \times 1\) 对应的序列长度太大(\(h \times w\)),计算成本过高。因此 \(2 \times 2\) 是在生成质量与计算效率之间的最佳折中点——在潜空间中以极低的信息损失换取 \(4\times\) 的序列压缩。
设计动机——去除归纳偏置(Inductive Bias)
什么是归纳偏置? 归纳偏置是模型在架构设计中对数据所做的先验假设,它限制了模型的假设空间,使其在有限数据下更容易泛化。CNN 具有两种强归纳偏置:
- 局部性(Locality):卷积核只关注局部邻域(如 \(3 \times 3\)),假设相邻像素高度相关,而忽略远距离像素的关系;
- 平移等变性(Translation Equivariance):同一卷积核在所有空间位置上共享权重。数学上,若 \(\phi\) 为卷积操作、\(T_s\) 为平移 \(s\) 个像素的算子,则 \(\phi(T_s(x)) = T_s(\phi(x))\)——即输入图像平移多少,输出特征图也跟着平移多少。直观地说,不管一只猫出现在图像的左上角还是右下角,卷积核检测到的响应模式完全相同,只是响应的位置跟着移动了。(注意这与平移不变性 \(\phi(T_s(x)) = \phi(x)\) 不同,后者需要全局池化才能近似实现。)
这些先验使 CNN 在小数据集上非常高效,但也限制了它捕获全局、长程依赖关系的能力。Transformer 则几乎不带空间先验——它必须完全从数据中"学习"这些关系,因此需要更大规模的训练数据,但在数据充足时能达到更高的性能上限 [11]。
与 ViT [11] 和 SD3 [8] 使用的可学习卷积 Patch Embedding 不同,Pixel Unshuffle 是一个确定性的双射(Bijective)重排,彻底移除了卷积层引入的归纳偏置。卷积 Patch Embedding 的权重矩阵本质上是在学习"如何聚合局部像素",其感受野大小和权重共享结构仍隐含地编码了局部性假设。而 Pixel Unshuffle 只做纯粹的空间→通道重排,不对像素之间的关系施加任何先验——所有的空间关系学习完全交由 Transformer 的全局自注意力机制来完成。
Dosovitskiy et al. [11] 在 ViT 的实验中已证明:当数据量与模型规模足够大时,去除归纳偏置反而能获得更高的性能上限。对于 Flux 这样拥有 12B 参数、在海量数据上训练的模型而言,这一设计选择尤为合理。此外,该操作完全可逆——解码时只需应用逆操作 Pixel Shuffle 即可无损还原空间分辨率 [12]。
2.3 三维旋转位置编码(3D RoPE)
SD3 采用的是传统的加性二维正弦位置编码 [8]。Flux 则引入了自然语言处理中广泛使用的旋转位置编码(Rotary Positional Embedding, RoPE) [2],并将其扩展至三维空间 [5]。
RoPE 的核心思想是不在输入端直接叠加位置向量,而是在计算注意力机制的 Query (\(\mathbf{q}\)) 和 Key (\(\mathbf{k}\)) 时,左乘一个与位置相关的正交旋转矩阵 \(\mathbf{R}_{\Theta, m}\)。这使得内积 \(\mathbf{q}_m^\top \mathbf{k}_n\) 能够自然地表达 Token 之间的相对位置关系 [2]。
在 Flux 中,每个 Token 被赋予一个三维坐标 \((t, h, w)\):
- 文本 Token:没有空间概念,坐标统一设为 \((0, 0, 0)\)。
- 图像 Token:位于特征图第 \(i\) 行 \(j\) 列的 Token,坐标设为 \((0, i, j)\)。
这三个维度的坐标分别被编码为长度为 16、56、56 的 RoPE 向量,拼接后总长度为 128(恰好等于单个注意力头的特征维度)。
为什么用 3D RoPE 而非 2D RoPE? 乍看之下,对于单张图像的文生图任务,所有图像 Token 的 \(t\) 维度恒为 0,似乎 \(t\) 是多余的——2D RoPE 只编码 \((h, w)\) 就够了。但这个第三维度 \(t\) 实际上是一个语义索引维度,为 Flux 的多图扩展预留了架构接口。
Flux Kontext 论文 [14] 明确阐述了这一设计意图:在上下文图像编辑(In-Context Editing)任务中,模型需要同时处理目标图像和参考图像,两者共享相同的 \((h, w)\) 空间网格。此时 \(t\) 维度充当"虚拟时间步"(virtual time step),用于在不破坏空间结构的前提下区分不同的图像流:
\[ \mathbf{u}_{\text{target}} = (0, h, w), \qquad \mathbf{u}_{y_i} = (i, h, w), \quad i = 1, \dots, N \]
其中目标图像的 \(t = 0\),第 \(i\) 张参考图像的 \(t = i\)。这在官方源码中也有直接体现:
# sampling.py — prepare_kontext()
img_cond_ids = torch.zeros(height // 2, width // 2, 3)
img_cond_ids[..., 0] = 1 # t 维度设为 1,区分参考图与目标图因此,Flux 选择 3D RoPE 的原因可以归纳为三点:
- 多图区分:2D RoPE 只能编码空间位置 \((h, w)\),无法区分同一空间位置上来自不同图像的 Token。\(t\) 维度提供了这个额外的区分能力,使得 Kontext 可以原生支持最多 10 张参考图 [14]。
- 视频扩展:\(t\) 维度天然对应视频的时间轴。VideoRoPE (Wang et al., 2025b) 等工作已证明 3D RoPE 在视频生成中的有效性。Flux 从一开始就采用 3D 编码,未来扩展到视频生成时无需修改架构。
- 零成本预留:对于基础的文生图任务,\(t \equiv 0\) 对 RoPE 旋转矩阵不产生影响(旋转角为 0),因此不会引入额外的计算开销或性能损失——它只是一个"休眠"维度,在需要时才被激活。
3D RoPE 赋予了 Flux 极强的空间外推能力,使其能够完美适应任意长宽比与高分辨率的图像生成,同时为多图编辑和视频生成提供了统一的位置编码框架 [5, 14]。
三、 混合 Transformer 骨干网络
Flux 的 Transformer 骨干网络由 19 层双流块(Double Stream Blocks)和 38 层单流块(Single Stream Blocks)串联而成 [5]。这种混合架构在表达能力与计算效率之间取得了绝佳的平衡。
3.1 双流块(Double Stream Blocks):跨模态对齐
网络的前 19 层采用了与 SD3 MMDiT 结构一致的双流块 [8]。在这一阶段,文本序列 \(\mathbf{X}_{\text{txt}}\) 与图像序列 \(\mathbf{X}_{\text{img}}\) 保持物理上的隔离。
计算流程:
- 独立调制与投影:文本和图像分别通过各自的 AdaLN 层(受 \(\mathbf{c}_{\text{global}}\) 调制),并使用独立的权重矩阵投影出各自的 \(\mathbf{Q}, \mathbf{K}, \mathbf{V}\)。
- 联合注意力(Joint Attention):将两者的 \(\mathbf{Q}, \mathbf{K}, \mathbf{V}\) 在序列维度上拼接,执行全局的自注意力计算。这一步是模态间信息交换的唯一通道。
- 独立前馈网络(MLP):注意力计算完成后,序列被重新拆分为文本和图像两部分,分别输入各自的 MLP 进行非线性变换。
设计动机:在网络浅层,文本(离散语义)与图像(连续像素)的特征空间存在巨大的语义鸿沟(Modality Gap)。使用独立的权重矩阵处理不同的模态,能够提供足够的自由度让模型完成初步的特征对齐 [5, 8]。
3.2 单流块(Single Stream Blocks):深度融合与并行计算
在经过 19 层双流块的初步对齐后,网络后段的 38 层无缝切换至单流块 [5]。

计算流程:
- 序列拼接:文本与图像序列在进入单流块前被永久拼接为一个统一的长序列 \(\mathbf{X}_{\text{joint}} = [\mathbf{X}_{\text{txt}}, \mathbf{X}_{\text{img}}]\)。
- 共享权重:所有 Token 共享同一套 AdaLN、自注意力权重与 MLP 权重。
- 并行计算架构:Flux 借鉴了 ViT-22B 的设计 [3],打破了传统 Transformer 中 Attention 和 MLP 串行计算的惯例。在单流块中,归一化后的特征同时输入给 Attention 层和 MLP 层,两者的输出在通道维度拼接后,通过一个统一的线性层进行融合: \[ \mathbf{X}_{\text{out}} = \mathbf{X}_{\text{in}} + \text{Linear}(\text{Concat}(\text{Attention}(\mathbf{X}_{\text{norm}}), \text{MLP}(\mathbf{X}_{\text{norm}}))) \]
设计动机:在网络深层,多模态特征已经实现了高层次的语义融合,此时继续维持两套权重不仅造成参数冗余,还会阻碍特征的进一步交融。单流架构显著提升了参数利用率;而并行计算设计则大幅减少了计算图的深度,提高了硬件执行效率 [3, 5]。
四、 核心创新点与数学原理解析
除了骨干网络的重构,Flux 在训练目标、蒸馏策略与训练稳定性上也引入了多项前沿技术。
4.1 蒸馏技术:从指引蒸馏到 LADD
传统扩散模型依赖无分类器指引(CFG)来增强文本条件的影响力。数学上,CFG 要求在每个时间步计算两次速度场(或噪声),并进行外推: \[ \hat{v} = v_{\text{uncond}} + s \cdot (v_{\text{cond}} - v_{\text{uncond}}) \] 其中 \(s\) 为指引强度(Guidance Scale)。这种双路计算导致推理时间直接翻倍。Flux 提供了两种截然不同的蒸馏方案来解决这一痛点:
方案一:指引蒸馏(Guidance Distillation, 用于 FLUX.1 [dev]) 该方案的目标是消除 CFG 的双倍计算开销,但保持原有的采样步数(约 50 步) [6]。
- 教师模型(FLUX.1 [pro])的计算:在训练的每一步,给定文本条件 \(c\)、当前潜变量 \(z_t\) 和时间步 \(t\),教师模型首先进行两次前向传播,分别计算无条件输出 \(v_{\text{uncond}}\) 和有条件输出 \(v_{\text{cond}}\)。随后,在预设的区间内(如 \([1.0, 10.0]\))随机采样一个指引强度标量 \(s\)(例如抽到 \(s=3.5\)),利用 CFG 公式计算出融合后的目标速度场 \(\hat{v}_{\text{teacher}}\)。注:教师模型的全局条件向量 \(\mathbf{c}_{\text{global}}\) 仅包含时间步 \(t\) 和文本语义,不包含 \(s\)。
- 学生模型(FLUX.1 [dev])的计算:学生模型同样接收文本条件 \(c\)、潜变量 \(z_t\) 和时间步 \(t\)。但与教师不同的是,学生模型将刚才采样到的标量 \(s\) 作为一个额外的输入参数(经过正弦编码与 MLP 后,融入全局条件向量 \(\mathbf{c}_{\text{global}}\) 中)。学生模型仅进行一次前向传播,输出 \(v_{\text{student}}\)。
- 优化目标:通过均方误差损失(MSE),迫使单次前向的 \(v_{\text{student}}\) 逼近教师模型双次前向组合出的 \(\hat{v}_{\text{teacher}}\)。
- 结果:蒸馏完成后,推理时只需将期望的 CFG 强度 \(s\) 传给模型,即可在单次前向计算中直接获得等效于该 CFG 强度的生成结果,推理速度翻倍。
方案二:潜空间对抗扩散蒸馏(LADD, 用于 FLUX.1 [schnell]) 该方案的目标是极大地压缩采样步数(从 50 步压缩至 1~4 步) [7]。为了理解 LADD,我们需要先了解它试图解决的痛点:
早期对抗蒸馏(如 ADD [15])的痛点:早期的加速方案会让学生模型在 1~4 步内生成图像,然后用一个外部的、预训练好的图像分类器(如 DINOv2)作为“判别器”来打分。但 DINOv2 工作在像素空间,这就要求学生模型(在潜空间中去噪的)必须先通过 VAE 解码器将潜变量转换为像素图像,才能送入判别器。虽然 VAE 解码本身只是一次前向计算,但在训练循环中反复执行会带来严重的瓶颈 [7, 15]:
- 反向传播开销:对抗损失的梯度需要穿过 VAE 解码器回传到学生模型,训练时必须保存解码器所有中间层的激活值,显存压力巨大;
- 数据膨胀:像素图像远大于潜变量(如 \(128 \times 128 \times 16\) 的 Latent 解码为 \(1024 \times 1024 \times 3\) 的像素图,数据量增大约 12 倍),进一步加剧显存消耗;
- 分辨率锁死:DINOv2 判别器只能处理固定分辨率(如 \(518 \times 518\)),导致 ADD 训练被限制在固定分辨率,无法支持任意长宽比的生成。
LADD 的核心创新:全程在潜空间(Latent Space)完成对抗。LADD 彻底抛弃了外部的像素级判别器,直接利用强大的教师模型(FLUX.1 [pro])本身来充当判别器的特征提取器,完全绕开了 VAE 解码这一环节 [7]。
LADD 的具体训练流程如下:
- 生成阶段(Generator):学生模型([schnell])接收纯噪声,试图在极少的步数(如 1~4 步)内,直接预测出一个高质量的潜变量 \(\hat{z}_0\)。
- 判别阶段(Discriminator):将学生生成的 \(\hat{z}_0\) 和真实的潜变量 \(z_0\) 分别输入给冻结的教师模型([pro])。LADD 并不看教师模型的最终输出,而是提取教师模型内部注意力层(Attention Layers)的中间特征。在这些特征之上,接一个轻量级的判别器网络,用来分辨输入到底是“学生生成的 Fake Latent”还是“真实的 Real Latent” [7]。
- 双重优化目标:
- 对抗损失(Adversarial Loss):学生模型需要不断优化自身,努力生成极其逼真的潜变量,以“骗过”基于教师特征的判别器。这保证了模型在 1~4 步内就能生成具有极高清晰度和丰富细节(高频信息)的图像。
- 分数蒸馏采样(Score Distillation Sampling, SDS):除了对抗,学生模型还要最小化 SDS 损失。SDS 利用教师模型预测的速度场/噪声,为学生模型提供明确的梯度方向,确保学生生成的图像在整体语义和结构上(低频信息)严格遵循教师模型的分布 [7]。
- 合成数据训练(Synthetic Data Training):为了保证学生模型在极少步数下依然拥有顶级的图文对齐能力,LADD 的训练数据并非真实图像,而是由教师模型([pro])提前生成好的高质量合成数据。因为真实图文对往往存在描述缺失或错位的问题,而合成数据则能提供“完美对齐”的监督信号。
- 结果:蒸馏后的 [schnell] 模型不仅摆脱了 CFG 的束缚(无需输入 Guidance),还能在 1~4 步内生成极高质量的图像,且天然支持多分辨率和任意长宽比。
4.2 分辨率自适应噪声调度(Resolution-Adaptive Noise Scheduling)
在 Flow Matching 框架下,时间步 \(t \in [0, 1]\) 决定了当前状态是偏向纯噪声(\(t=0\))还是清晰图像(\(t=1\))。推理时,采样器需要在 \([0, 1]\) 区间上放置若干时间步,然后沿这些时间步依次求解 ODE。一个朴素的做法是均匀放置时间步(如 \(t = 1.0, 0.8, 0.6, 0.4, 0.2, 0.0\)),但这对所有分辨率一视同仁,忽略了一个关键的物理直觉。
核心直觉:为什么高分辨率需要更多"高噪声"步数?
想象往一张 \(64 \times 64\) 和一张 \(512 \times 512\) 的图像上添加相同标准差的高斯噪声。低分辨率图像的全局结构(如物体轮廓、大色块)很快就被淹没了;而高分辨率图像由于像素数多、相邻像素强相关,同样强度的噪声对全局结构的破坏要小得多——你仍能"透过噪声"看到大致轮廓 [8]。这意味着高分辨率图像需要更强的噪声才能将信号彻底摧毁。对称地,反向生成时,高分辨率图像必须在高噪声区域(即 \(t\) 接近 0 时)投入更多的积分步数,才能正确恢复其复杂的全局拓扑结构 [8]。
SD3 论文 [8] 首先提出了这一分辨率自适应的时间步偏移机制,Flux 继承了这一设计。具体来说,给定均匀分布的基础时间步 \(t\),Flux 通过一个非线性变换将其映射为偏移后的时间步 \(t'\):
\[ t' = \frac{e^{\mu} \cdot t}{1 + (e^{\mu} - 1) \cdot t} \]
其中偏移参数 \(\mu\) 根据图像 Token 总数 \(N\) 线性插值得到:
\[ \mu = m \cdot N + b, \quad m = \frac{1.15 - 0.5}{4096 - 256}, \quad b = 0.5 - m \cdot 256 \]
即 \(\mu\) 在 \(N = 256\)(\(16 \times 16\) Latent,低分辨率)时为 \(0.5\),在 \(N = 4096\)(\(64 \times 64\) Latent,高分辨率)时为 \(1.15\)。这在官方源码中的实现如下:
# sampling.py
def time_shift(mu, sigma, t):
return math.exp(mu) / (math.exp(mu) + (1 / t - 1) ** sigma)
def get_schedule(num_steps, image_seq_len, base_shift=0.5, max_shift=1.15, shift=True):
timesteps = torch.linspace(1, 0, num_steps + 1) # 均匀时间步
if shift:
mu = get_lin_function(y1=base_shift, y2=max_shift)(image_seq_len)
timesteps = time_shift(mu, 1.0, timesteps) # 非线性偏移
return timesteps.tolist()下图展示了不同 \(\mu\) 值下时间步偏移函数的效果。黑色虚线为无偏移(恒等映射),彩色曲线分别对应低、中、高分辨率的偏移程度:
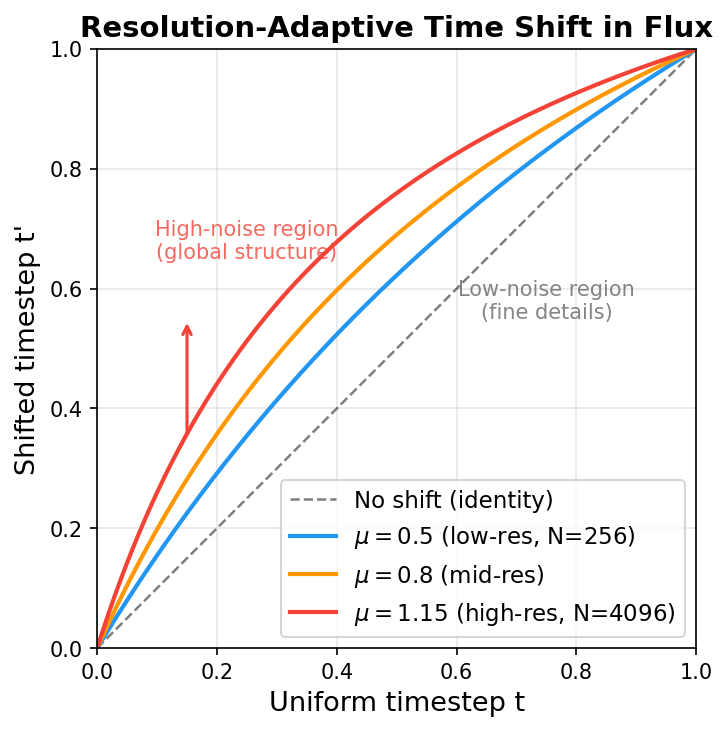
可以看到,\(\mu\) 越大(分辨率越高),曲线越向左上方凸起——同一个均匀时间步 \(t\) 被映射到更高的 \(t'\) 值。这意味着采样器在高噪声区域(曲线左侧,对应全局结构的恢复阶段)分配了更密集的步长,而在低噪声区域(曲线右侧,对应细节填充)则以更大步长快速通过 [8]。
4.3 QK-Norm 与 12B 模型训练稳定性
在将 Transformer 扩展至 12B 参数时,注意力机制的数值不稳定性会急剧放大。在标准的 Attention 中,注意力分数由 \(\mathbf{Q}\mathbf{K}^\top / \sqrt{d}\) 计算得出。当特征维度或参数量极大时,点积结果容易出现极值,导致 Softmax 函数进入饱和区(梯度消失)或引发梯度爆炸 [3]。
Flux 引入了 QK-Norm 技术 [3, 5]:在计算点积之前,先对 Query 和 Key 分别应用 RMSNorm(均方根归一化): \[ \text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{Softmax}\left( \text{RMSNorm}(\mathbf{Q}) \cdot \text{RMSNorm}(\mathbf{K})^\top \right) \mathbf{V} \] 这一操作强制 \(\|\mathbf{q}\| \approx 1\) 且 \(\|\mathbf{k}\| \approx 1\),严格限制了注意力分数的数值上限,从根本上消除了 Softmax 饱和现象,确保了 12B 极大规模模型的训练稳定性 [3]。
延伸:QK-Norm 已成为现代大模型的标配。 到 2025 年,QK-Norm 已被广泛采用为大规模 Transformer 的训练稳定性"最佳实践",包括 Gemma 3、OLMo 2、Qwen 3、Kimi K2 等主流模型均采用了这一技术 (Tan, 2025)。即便是 DeepSeek-V3(671B 参数)和 V4(1T+ 参数)这样的超大规模模型,训练过程也被报告为"极其稳定,没有不可恢复的 Loss 尖峰"(DeepSeek-AI, 2024)。值得注意的是,DeepSeek 使用的 MLA(Multi-head Latent Attention) 架构由于对 Q、K 做了低秩压缩,无法直接在推理时展开完整的 Q、K 向量来应用标准 QK-Norm (Anson & Aitchison, 2025)。对此,研究者提出了替代方案:如通过参数级别的学习率调控来约束注意力 logit 的增长速度 (Anson & Aitchison, 2025),或使用 Logit Soft-Capping(如 Gemma 2 中的 \(c \cdot \tanh(\text{logits} / c)\))对注意力分数做平滑截断 (Tan, 2025)。但总体趋势是:QK-Norm 因其简洁性和有效性,正在逐步取代这些后处理方案——Gemma 3 就将 Gemma 2 中的 Soft-Capping 替换为了 QK-Norm (Tan, 2025)。
五、 延伸:FLUX.2 的架构演进与能力飞跃
2025 年 11 月,Black Forest Labs 推出了全新预训练的 FLUX.2 [9]。它绝非 FLUX.1 的简单微调版,而是在底层架构与产品能力上进行了一次“脱胎换骨”的重构 [10]。为了让大家更直观地理解这次升级,我们将从“底层架构”和“外在能力”两个维度进行剖析。
5.1 底层架构的激进重构
文本编码器大换血:从“关键词匹配器”到“原生多模态大模型” FLUX.1 使用了 CLIP + T5 的组合,这俩本质上还是传统的文本编码器,对复杂物理规律(比如“镜子里的倒影”、“半透明材质”)的理解比较吃力。 FLUX.2 直接掀桌子,换成了一个 24B 参数的视觉语言大模型(VLM)—— Mistral Small 3.1 [9]。VLM 是看过海量图文交织数据的,它拥有强大的“世界知识”。这意味着 FLUX.2 不仅能听懂你的提示词,还能像人类一样理解空间关系和物理属性。为了达到最佳效果,FLUX.2 巧妙地提取了 Mistral 中间层(第 10、20、30 层)的特征进行堆叠,因为中间层往往保留了最适合生成图像的语义信息 [10]。
骨干网络大倾斜:单流块的全面胜利 FLUX.1 证明了一件事:双流块(文本和图像分开处理)虽然好,但太占参数了。只要在网络最前面用几个双流块把特征对齐,后面的工作完全可以交给更高效的单流块(文本图像拼在一起处理)。 因此,FLUX.2 将 19 层双流 + 38 层单流的比例,极其激进地调整为 8 层双流 + 48 层单流 [10]。在 FLUX.2 庞大的 32B 参数中,约 73% 的参数都被分配给了融合更深入、计算更高效的单流块。
极致的架构微调(Tweaks)
- 全面移除 Bias 参数:在神经网络中,线性层的计算为
\(y = Wx + b\),其中 \(b\) 就是
Bias(偏置)参数——它是一个可学习的向量,允许线性变换在输出空间中做平移。在
Transformer 中,Bias 主要存在于以下位置:(1) 注意力层的 Q/K/V
投影和输出投影的线性层中(FLUX.1 中
qkv_bias=True);(2) MLP/FFN 层的线性层中;(3) 归一化层中(LayerNorm 的 \(\beta\) 参数本质上也是 Bias,但 RMSNorm 天然不含此项)。然而在使用了 RMSNorm 的现代 Transformer 中,归一化操作本身已经会重新调整激活值的分布,使得 Bias 的平移效果被"抵消",变得冗余。移除 Bias 不仅减少了参数量和显存开销,实验上还被发现能提升大模型的训练稳定性。这也是 LLaMA、PaLM、Qwen 等主流大语言模型的标准做法。 - 共享 AdaLN 调制:双流块和单流块内部不再各自为战,而是共享调制参数,大幅降低了条件注入的开销。
- 升级 SwiGLU 激活函数:抛弃了老旧的 GELU,换上了在大语言模型(LLM)中大放异彩的 SwiGLU。
- 全新 VAE (AutoencoderKLFlux2):重新训练了 VAE,极大地提升了对高频细节(如微小的文字、织物纹理)的压缩与重建质量 [9, 10]。
- 全面移除 Bias 参数:在神经网络中,线性层的计算为
\(y = Wx + b\),其中 \(b\) 就是
Bias(偏置)参数——它是一个可学习的向量,允许线性变换在输出空间中做平移。在
Transformer 中,Bias 主要存在于以下位置:(1) 注意力层的 Q/K/V
投影和输出投影的线性层中(FLUX.1 中
5.2 架构驱动的能力质变
上述架构变化并非孤立的工程优化——它们共同支撑了 FLUX.2 在实际生成能力上的显著提升 [9, 10]。
- 原生 4MP 高分辨率生成:FLUX.1 原生输出约 1MP(如 1024×1024),FLUX.2 则支持原生 4MP(如 2048×2048)输出,无需后处理放大。这得益于全新 VAE(AutoencoderKLFlux2)更优的压缩-重建平衡,以及 32B 骨干网络对高分辨率全局结构的建模能力。
- 多图参考一致性(Multi-Reference):FLUX.2 原生支持最多 10 张参考图同时输入,保持角色、产品或画风在不同场景间的一致性。这一能力直接源自 3D RoPE 的 \(t\) 维度设计(§2.3)——不同参考图通过不同的 \(t\) 值编码,在共享空间坐标 \((h, w)\) 的同时被自注意力机制区分 [14]。
- 生成与编辑的统一:FLUX.1 时代,文生图(Generation)和局部编辑(Inpainting/Editing)通常需要独立的模型或工作流。FLUX.2 将两者统一在同一架构下——同一个 checkpoint 既能从纯文本生成图像,也能基于参考图进行编辑 [9]。
- 可靠的文字渲染(Typography):FLUX.2 能够生成包含复杂排版的图像(如 UI 原型、信息图表中的精细文字)。VLM 文本编码器(Mistral Small 3.1)对字母序列和排版语义的理解远超传统的 CLIP/T5 组合,是这一能力的关键 [9]。
- 结构化精准控制:支持 HEX 色值精确匹配(如提示词中写
#FF5733即可还原对应颜色)和 JSON 格式的结构化提示词(Structured Prompting),允许开发者以类似代码的方式控制构图、相机参数与光影布局 [9, 10]。
5.3 FLUX.1 与 FLUX.2 核心参数对比
| 架构维度 | FLUX.1 | FLUX.2 |
|---|---|---|
| 骨干参数量 | 12B | 32B |
| 文本编码器 | CLIP-L + T5-XXL | Mistral Small 3.1 (24B) |
| 双流/单流层数 | 19 / 38 | 8 / 48 |
| 双流参数占比 | ~54% | ~24% |
| Bias 参数 | 存在 | 全部移除 |
| AdaLN 调制 | 逐层独立生成 | 块间共享 |
| MLP 激活函数 | GELU | SwiGLU |
| VAE | FLUX.1 VAE | AutoencoderKLFlux2 |
| 原生分辨率 | ~1MP | 4MP |
| 参考图支持 | 依赖外部 ControlNet | 原生支持最多 10 张 |
参考资料:
- Black Forest Labs. (2024). Flux.1 [dev]. https://blackforestlabs.ai/
- Su, J. et al. (2024). RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864.
- Dehghani, M. et al. (2023). Scaling Vision Transformers to 22 Billion Parameters. ICML 2023.
- 周弈帆. (2024). FLUX.1 源码深度前瞻解读. https://zhouyifan.net/2024/09/03/20240809-flux1/
- Greenberg, O. (2025). Demystifying Flux Architecture. arXiv:2507.09595.
- Meng, C. et al. (2023). On Distillation of Guided Diffusion Models. CVPR 2023.
- Sauer, A. et al. (2024). Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation. arXiv:2403.12015.
- Esser, P. et al. (2024). Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. ICML 2024.
- Black Forest Labs. (2025). FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2
- HuggingFace. (2025). Diffusers welcomes FLUX-2. https://huggingface.co/blog/flux-2
- Dosovitskiy, A. et al. (2021). An Image is Worth 16x16 Words. ICLR 2021.
- Shi, W. et al. (2016). Efficient Sub-Pixel Convolutional Neural Network. CVPR 2016.
- Peebles, W. & Xie, S. (2023). Scalable Diffusion Models with Transformers. ICCV 2023.
- Black Forest Labs. (2025). FLUX.1 Kontext. arXiv:2506.15742.
- Sauer, A. et al. (2024). Adversarial Diffusion Distillation. ECCV 2024.
➡️ 下一篇:笔记|强化学习(一):强化学习基础与策略梯度