笔记|强化学习(一续):从 REINFORCE 到 Actor-Critic
本文承接上一篇的策略梯度理论,介绍策略梯度的三种实际实现——从最朴素的 REINFORCE 到引入基线的版本,再到 Actor-Critic 架构——并推导广义优势估计(GAE),为后续深入理解 PPO 和 GRPO 打下坚实的算法基础。
⬅️ 上一篇:笔记|强化学习(一):强化学习基础与策略梯度
在上一篇中,我们通过策略梯度定理推导出了梯度公式 \(\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta}\left[\sum_t \gamma^t \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot Q^{\pi_\theta}(s_t, a_t)\right]\),并证明了为什么梯度中会出现 \(\log\) 概率。
从 REINFORCE 到 Actor-Critic:算法的演进
虽然我们在理论上推导出了应该用优势函数 \(A(s_t, a_t)\) 来更新策略,但在实际写代码时,我们无法直接获得真实的 \(A\) 值或 \(Q\) 值,只能通过采样(Sampling)来近似估计。根据估计方法的不同,策略梯度算法经历了以下几个阶段的演进。
在进入具体算法之前,先理清本文中频繁出现的几个符号的层次关系——它们是不同算法的共同基础:
| 符号 | 名称 | 定义 | 层次 |
|---|---|---|---|
| \(r_t\) | 即时奖励 | 第 \(t\) 步环境给的分数 | 观测值(单步,已知) |
| \(G_t = \sum_{k=0}^{T-t} \gamma^k r_{t+k}\) | 累积回报 | 从 \(t\) 到结束的折扣奖励总和 | 观测值(需跑完整局才知道) |
| \(Q(s,a) = \mathbb{E}[G_t \mid s_t{=}s, a_t{=}a]\) | 动作价值 | 在 \(s\) 执行 \(a\) 后的期望总回报 | 理论期望(跑无数局取平均) |
| \(V(s) = \mathbb{E}_{a \sim \pi}[Q(s,a)]\) | 状态价值 | 在 \(s\) 下按策略行动的期望总回报 | 理论期望 |
| \(A(s,a) = Q(s,a) - V(s)\) | 优势函数 | 动作 \(a\) 比平均水平好多少 | 理论期望 |
| \(\delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)\) | TD 误差 | 一步实际表现与 Critic 预期之差 | \(A\) 的有偏近似(方差低) |
核心关系:理论公式用的是 \(A\)(真实优势),但 \(A\) 算不出来。实际算法用不同的近似替代它:
\[ A(s_t, a_t) \approx \begin{cases} G_t - V(s_t) & \text{(蒙特卡洛,无偏但方差大)} \\ \delta_t & \text{(TD 误差,方差小但有偏)} \\ \sum_l (\gamma\lambda)^l \delta_{t+l} & \text{(GAE,可调的折中)} \end{cases} \]
下面三种算法分别对应这三种近似方式。
为了让讲解更直观,我们先设定一个贯穿本章的具体例子,然后用它来串起三种算法。
例子:训练 AI 面试助手
假设你在训练一个 AI 面试助手(智能体),面试共三轮。AI 在每轮做出一个决策,并获得面试官打分。我们让 AI 完成了一局面试(为简化,令 \(\gamma = 1\)):
| 轮次 | 状态 | AI 的决策 | 该轮得分(\(r_t\)) |
|---|---|---|---|
| 第 1 轮(自我介绍) | \(s_1\) | "讲项目经历" | \(r_1 = +6\) |
| 第 2 轮(技术面) | \(s_2\) | "用动态规划解题" | \(r_2 = +2\) |
| 第 3 轮(HR 面) | \(s_3\) | "聊职业规划" | \(r_3 = +4\) |
同时,假设我们有一个经验丰富的面试顾问(Critic 网络 \(V_\phi\)),他对各状态的预估为:
- \(V_\phi(s_1) = 9\)("从第 1 轮开始,历史面试者的平均总分大约是 9 分")
- \(V_\phi(s_2) = 5\)("从第 2 轮开始,平均还能拿 5 分")
核心问题:第 1 轮选择"讲项目经历"这个决策到底好不好?策略参数应该怎么调? 接下来,我们看三种算法如何回答这个问题。
1. 最朴素的实现:REINFORCE 算法
先看例子: REINFORCE 的做法最简单——等三轮面试全部结束,算出总分,直接用总分评价第 1 轮的决策:
\[G_1 = r_1 + r_2 + r_3 = 6 + 2 + 4 = \mathbf{12}\]
然后用 \(G_1 = 12\) 乘以梯度方向 \(\nabla_\theta \log \pi_\theta(a_1|s_1)\) 来更新策略参数:让"讲项目经历"的概率变大。
问题马上就来了: 假设 AI 再跑一局,第 1 轮仍然选"讲项目经历"(\(r_1 = +6\)),但第 2、3 轮运气不同(\(r_2 = 0, r_3 = +1\)),总分变成了 \(G_1 = 7\)。两次信号(\(12\) vs \(7\))的差异,并非第 1 轮决策好坏所致,而是后面轮次的随机性造成的。而且信号都是较大的正数,被乘入梯度后,参数每次更新的幅度都很大且波动剧烈。
一般化的算法原理:
上面例子中 \(G_1 = r_1 + r_2 + r_3\) 是 \(\gamma = 1\) 时的特例。一般地,智能体在 \(t\) 时刻执行动作 \(a_t\) 后,实际获得的累积折扣回报记为: \[ G_t = \sum_{k=0}^{T-t} \gamma^k r_{t+k} \]
REINFORCE 算法直接用 \(G_t\) 替换策略梯度公式中的 \(Q(s_t, a_t)\)。之所以可以这样替换,是因为 \(Q\) 的定义就是 \(G_t\) 的期望(\(Q(s_t, a_t) = \mathbb{E}[G_t]\)),所以 \(G_t\) 是 \(Q\) 的一个无偏估计(Unbiased Estimate)——虽然每局的 \(G_t\) 时高时低,但打足够多局取平均,就会精确收敛到理论上的 \(Q\) 值。
参数更新公式: \[ \theta \leftarrow \theta + \alpha \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot G_t \]
从数学公式到 PyTorch 代码:为什么 Loss 是 \(-G_t \cdot \log \pi\)?
上面的更新公式写明了梯度方向,但 PyTorch
中我们不手动算梯度——我们定义一个 loss,调用 loss.backward()
让自动微分完成反向传播。那么问题来了:loss 该怎么定义,才能让
.backward() 算出策略梯度?
一个常见的初学者直觉是"目标是最大化回报 \(G\),直接写 loss = -G
不就行了?"但这条路从计算图(Computation
Graph)的角度根本走不通。下面这张图直观地展示了"断"在哪里,以及数学推导如何巧妙地"绕过"了这个断点:
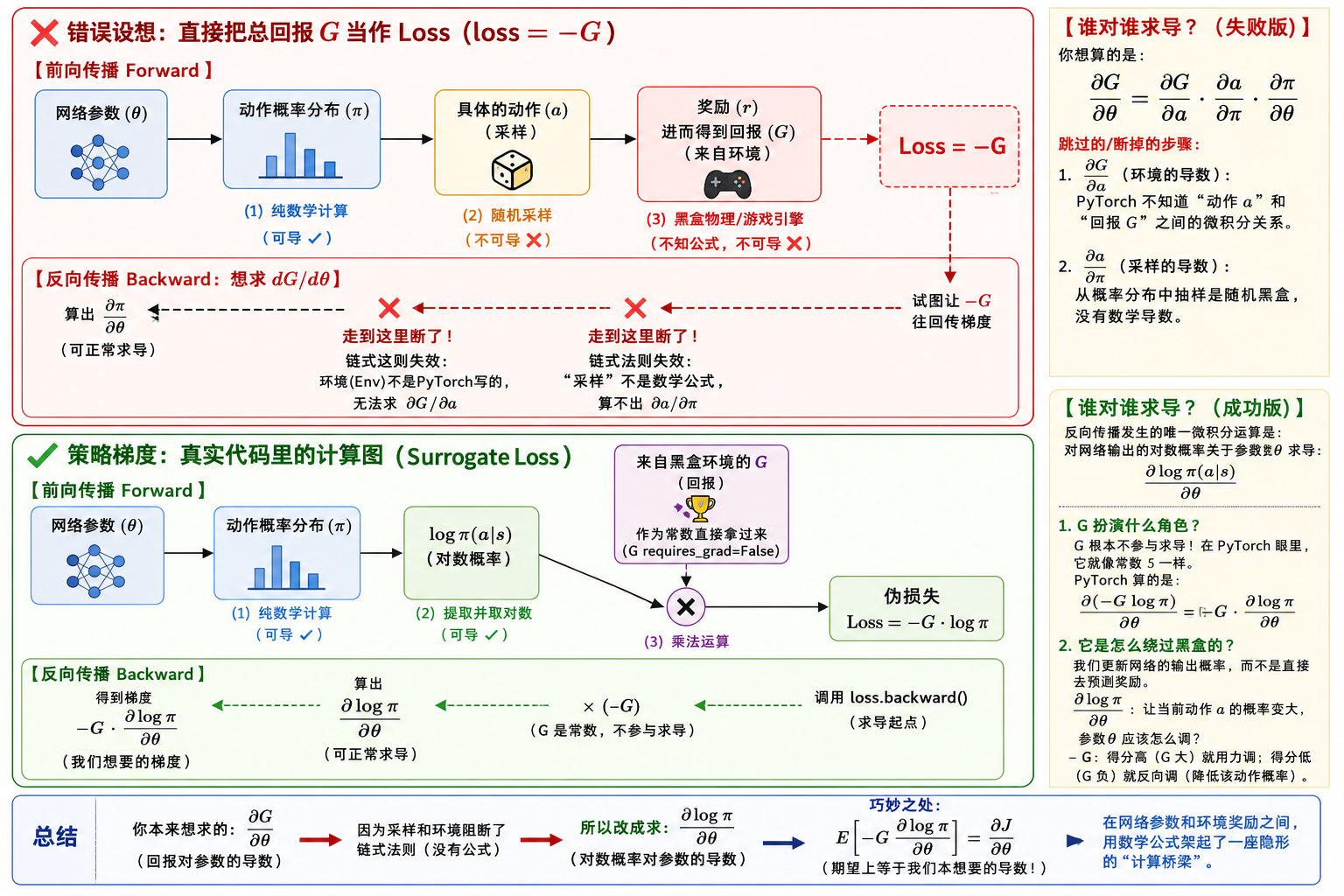
❌ 错误设想:loss = -G
如果写 loss = -G 并调用
loss.backward(),PyTorch 需要沿链式法则计算 \(\frac{\partial G}{\partial
\theta}\)。但前向传播的计算图如下:
\[\theta \xrightarrow[\text{可导 ✓}]{\text{(1) 纯数学计算}} \pi(a|s) \xrightarrow[\text{不可导 ❌}]{\text{(2) 随机采样}} a \xrightarrow[\text{不可导 ❌}]{\text{(3) 环境黑盒}} r \to G\]
链式法则要求 \(\frac{\partial G}{\partial \theta} = \frac{\partial G}{\partial a} \cdot \frac{\partial a}{\partial \pi} \cdot \frac{\partial \pi}{\partial \theta}\),其中有两个无法计算的导数:
- \(\frac{\partial a}{\partial \pi}\)(采样的导数):从概率分布 \(\pi(a|s) = [0.1, 0.9]\) 中"抽奖"得到离散动作 \(a\),是一个随机操作而非可微函数,不存在解析导数。
- \(\frac{\partial G}{\partial a}\)(环境的导数):动作 \(a\) 送入环境后得到奖励 \(r\)。环境可能是物理引擎、游戏模拟器或大模型评分器——PyTorch 不知道它们的内部公式,也无法对其求导。
反向传播走到这两个节点就断了——梯度无法从 \(G\) 传回参数 \(\theta\)。
✅ 策略梯度的巧妙绕路:代理损失(Surrogate Loss)
策略梯度定理提供了一种绕过黑盒的方案。核心思想是:不求 \(\frac{\partial G}{\partial \theta}\),而是构造一个代理损失,让它的梯度恰好等于策略梯度。 这个代理损失就是:
\[\text{Loss}_{\text{surrogate}} = -G_t \cdot \log \pi_\theta(a_t|s_t)\]
它对应的计算图从 \(\theta\) 到 Loss 全部由纯数学运算组成,反向传播畅通无阻:
\[\theta \xrightarrow[\text{可导 ✓}]{\text{(1) 纯数学}} \pi(a|s) \xrightarrow[\text{可导 ✓}]{\text{(2) 取对数}} \log \pi(a|s) \xrightarrow[\text{可导 ✓}]{\text{(3) 乘以常数 } {-G}} \text{Loss}\]
关键在于 \(G\)
的角色彻底改变了:它不再是计算图的"下游输出"(需要从环境中反传梯度回来),而是作为一个外部常数(requires_grad=False)直接乘入。就像写
loss = 5 * x 里的 5,PyTorch 根本不对 \(G\) 求导——它只对 \(\log \pi\) 求导。
调用 loss.backward() 时,PyTorch 实际计算的是:
\[\frac{\partial \text{Loss}}{\partial \theta} = -G \cdot \frac{\partial \log \pi}{\partial \theta}\]
取负号是因为 PyTorch 做的是梯度下降(最小化 loss),等价于对目标函数 \(J(\theta)\) 做梯度上升(最大化期望回报)。而 \(-G \cdot \frac{\partial \log \pi}{\partial \theta}\) 恰好就是我们在上一篇的对数导数技巧推导中证明的策略梯度——那段推导的贡献 (2) 正是关键:环境转移概率 \(P(s'|s,a)\) 对 \(\theta\) 的梯度为零并被消除,所以最终的梯度公式 \(\nabla_\theta \log \pi\) 只涉及策略网络自身,完全不需要对环境求导。这就是代理损失能绕过黑盒的数学根基。更严格地说,代理损失的梯度在期望意义下精确等于真正的策略梯度(参见 Williams, 1992 和 Schulman et al., 2015: Gradient Estimation Using Stochastic Computation Graphs):
\[\mathbb{E}\left[\frac{\partial \text{Loss}}{\partial \theta}\right] = \mathbb{E}\left[-G \cdot \frac{\partial \log \pi}{\partial \theta}\right] = -\nabla_\theta J(\theta)\]
一句话总结:我们本来想求 \(\frac{\partial G}{\partial \theta}\)(回报对参数的导数),但采样和环境交互阻断了链式法则。策略梯度定理证明,改为求 \(\frac{\partial \log \pi}{\partial \theta}\)(对数概率对参数的导数)再乘以常数 \(G\),在期望上恰好等价。代理损失 \(-G \cdot \log \pi\) 就是在网络参数和环境奖励之间架起的一座"数学桥梁"——让不可导的黑盒绕路变成了可导的计算图。这就是代码中
policy_loss += -log_prob * G_t这一行的深层含义。
关于 REINFORCE 算法的深入探讨可参考 REINFORCE: Monte Carlo Policy Gradient Methods(含方差分析和代码示例)。回到面试的例子,REINFORCE 的两个致命缺点就非常清楚了:
- 方差极大:两局面试中 \(G_1\) 分别是 \(12\) 和 \(7\),但第 1 轮的决策完全相同。这种波动来自后续轮次的随机性,却被当作第 1 轮决策的评价信号,导致梯度估计震荡剧烈。
- 回合更新(Episodic):必须等三轮面试全部结束,才能算出 \(G_1\) 并更新参数。如果面试有 100 轮呢?效率极低。
REINFORCE 的完整实现:
import torch
import gymnasium as gym
# ============================================================
# 超参数与环境
# ============================================================
gamma = 0.99 # 折扣因子 γ ∈ [0,1)
num_episodes = 1000 # 训练总局数
env = gym.make("CartPole-v1") # Gymnasium 环境(可替换为任意环境)
state_dim = env.observation_space.shape[0] # 状态向量维度(CartPole: 4)
action_dim = env.action_space.n # 离散动作数(CartPole: 2)
# ============================================================
# 模型定义
# actor: 策略网络 π_θ(a|s),输入状态 s,输出动作概率分布
# REINFORCE 只需要 Actor,不需要 Critic
# ============================================================
actor = ActorModel(state_dim, action_dim) # 需自行定义,如两层 MLP → Softmax
optimizer = torch.optim.Adam(actor.parameters(), lr=1e-3)
def collect_episode(env, actor):
"""
采集一条完整轨迹 τ = (s₀,a₀,r₀), (s₁,a₁,r₁), ...
必须跑完整局(回合制),因为 G_t 需要直到终止的所有奖励
"""
trajectory = []
state, _ = env.reset() # Gymnasium 返回 (obs, info)
done = False
while not done:
state_t = torch.tensor(state, dtype=torch.float32)
dist = actor(state_t) # 前向传播: s → π_θ(·|s_t)
action = dist.sample() # 从策略分布采样: a_t ~ π_θ(·|s_t)
log_prob = dist.log_prob(action) # 记录 log π_θ(a_t|s_t),策略梯度公式中的核心项
next_state, reward, terminated, truncated, _ = env.step(action.item())
done = terminated or truncated
trajectory.append((log_prob, reward))
state = next_state
return trajectory
def compute_returns(trajectory, gamma):
"""
反向递推蒙特卡洛回报:
G_t = r_t + γ·r_{t+1} + γ²·r_{t+2} + ... = r_t + γ·G_{t+1}
G_t 是 Q^π(s_t, a_t) 的无偏估计
"""
returns, G = [], 0
for _, reward in reversed(trajectory):
G = reward + gamma * G # 从末尾反向累加
returns.insert(0, G)
# requires_grad=False(默认),G_t 在计算图中充当常数系数
return torch.tensor(returns)
# ============================================================
# 训练循环
# 对应公式: ∇_θ J(θ) ≈ Σ_t ∇_θ log π_θ(a_t|s_t) · G_t
# 每局: 采一条轨迹 → 算 G_t → 梯度更新 → 丢弃数据(on-policy)
# ============================================================
for episode in range(num_episodes):
trajectory = collect_episode(env, actor) # Step 1: 采集轨迹 τ ~ π_θ
returns = compute_returns(trajectory, gamma) # Step 2: 计算各步 G_t
# Step 3: 构建代理损失
# 对应公式: loss = −Σ_t log π_θ(a_t|s_t) · G_t
# 最小化此 loss ⟺ 沿 Σ_t ∇_θ log π · G_t 方向做梯度上升
policy_loss = 0
for t in range(len(trajectory)):
log_prob = trajectory[t][0] # 第 t 步的 log π_θ(a_t|s_t)
G_t = returns[t] # 第 t 步的累积回报
policy_loss += -log_prob * G_t # 每个时间步的梯度贡献
optimizer.zero_grad()
policy_loss.backward() # 反传: ∂loss/∂θ = −Σ G_t · ∂log π/∂θ
optimizer.step() # θ ← θ - α·∂loss/∂θ = θ + α·Σ G_t·∇log π代码中为什么省略了 \(\gamma^t\)?
上一篇推导出的策略梯度定理包含 \(\gamma^t\) 因子——\(\nabla J_\gamma = \mathbb{E}[\sum_t \gamma^t \nabla \log \pi \cdot Q]\),但代码里用的是 \(\sum_t \nabla \log \pi \cdot G_t\)(没有 \(\gamma^t\))。这并非疏忽,而是 RL 领域一个已知的"理论 vs 实践"缺口:
- Nota & Thomas (2020) "Is the Policy Gradient a Gradient?" 严格证明了:丢掉 \(\gamma^t\) 后,大家实际使用的更新方向不对应任何明确的优化目标。打个比方:梯度上升就像"沿山坡最陡方向往上爬",只要你爬的是一座真实的山(某个目标函数 \(J\)),就一定能到达山顶(局部最优)。但丢掉 \(\gamma^t\) 后的方向就像"一组看似上坡却拼不出任何连贯地形的箭头"——你沿着走通常也能走到高处,但理论上不保证。Nota & Thomas 甚至构造了一个反例,在某个 MDP 中,沿这个方向走最终收敛到了全局最差策略。
- 但几乎所有主流实现(Spinning Up、CleanRL、PyTorch 示例、stable-baselines 中的 A2C/PPO/TRPO/SAC/TD3)都这样做。Nota & Thomas 调查了这些实现,确认全部丢掉了 \(\gamma^t\)。
- 实际原因:保留 \(\gamma^t\) 会让后期决策的梯度信号指数衰减(\(\gamma=0.99, t=100\) 时 \(\gamma^{100} \approx 0.37\)),严重拖慢对后期决策的学习。丢掉它虽然理论上不严格,但让每个时间步都有平等的学习机会,实践中效果更好。
- 研究仍在继续:Che et al. (ICML 2023) 提出了修正方案来缓解这个 discount-factor mismatch。
2. 引入基线 (REINFORCE with Baseline)
先看例子: 为了更准确地评价第 1 轮的决策,我们请出那位面试顾问(Critic)。他说:"历史上从第 1 轮开始,面试者的平均总分是 \(V_\phi(s_1) = 9\) 分。"
有了这个参考值,我们就可以算出"这局面试比平均水平好了多少":
\[\text{更新信号} = G_1 - V_\phi(s_1) = 12 - 9 = \mathbf{+3}\]
\(+3\) 的含义很清晰:这局比平均高了 3 分,"讲项目经历"是好于平均的选择。
如果另一局总分是 \(7\) 分,信号就是 \(7 - 9 = -2\)(不如平均,应降低该决策的概率)。对比两种算法的信号:
| 第 1 局 | 第 2 局 | 信号波动范围 | |
|---|---|---|---|
| REINFORCE | \(12\) | \(7\) | \([7, 12]\)(大正数) |
| + Baseline | \(+3\) | \(-2\) | \([-2, +3]\)(0 附近) |
减去基线后,信号的幅度从 \([7, 12]\) 缩小到了 \([-2, +3]\),梯度被乘以的数值大大减小,参数更新的震荡随之降低。而且正负号直接告诉你决策是好是坏,方向更清晰。
一般化的算法原理:
我们在 \(G_t\) 的基础上减去一个状态价值的估计值 \(V_\phi(s_t)\)(用另一个神经网络拟合,参数为 \(\phi\)),用 \((G_t - V_\phi(s_t))\) 来近似优势函数 \(A(s_t, a_t)\)。
参数更新公式: \[ \theta \leftarrow \theta + \alpha \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot (G_t - V_\phi(s_t)) \]
需要注意一个微妙之处:虽然信号的绝对幅度降低了,但 \(G_t\) 本身的随机波动(它仍然包含 \(r_{t+1}, r_{t+2}, \dots\) 等后续时步的随机性)并没有改变。基线解决的是"信号偏离零点太远"的问题,而非"信号内部的随机性太大"的问题。
回到面试的例子,这个方法依然没有解决"回合更新"的问题——计算 \(G_1 = r_1 + r_2 + r_3\) 仍然需要等三轮面试全部结束。有没有办法不等面试结束,走一步就能评价呢?
REINFORCE with Baseline 的完整实现:
import torch
import torch.nn.functional as F
import gymnasium as gym
# ============================================================
# 超参数与环境(同上)
# ============================================================
gamma = 0.99
num_episodes = 1000
env = gym.make("CartPole-v1")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
# ============================================================
# 模型定义(新增 Critic 网络作为基线)
# actor: 策略网络 π_θ(a|s)
# critic: 价值网络 V_φ(s),估计状态价值,用于减小方差
# ============================================================
actor = ActorModel(state_dim, action_dim) # 需自行定义
critic = CriticModel(state_dim) # 需自行定义,如两层 MLP → 标量输出
actor_optimizer = torch.optim.Adam(actor.parameters(), lr=1e-3)
critic_optimizer = torch.optim.Adam(critic.parameters(), lr=1e-3)
def collect_episode_with_values(env, actor, critic):
"""
采集一条完整轨迹,同时记录每步的 V_φ(s_t)
仍需跑完一整局(回合制),因为计算 G_t 需要全部奖励
"""
trajectory = []
state, _ = env.reset()
done = False
while not done:
state_t = torch.tensor(state, dtype=torch.float32)
dist = actor(state_t) # π_θ(·|s_t)
action = dist.sample() # a_t ~ π_θ(·|s_t)
log_prob = dist.log_prob(action) # log π_θ(a_t|s_t)
value = critic(state_t).squeeze() # V_φ(s_t):基线估计值
next_state, reward, terminated, truncated, _ = env.step(action.item())
done = terminated or truncated
trajectory.append((log_prob, reward, value))
state = next_state
return trajectory
# ============================================================
# 训练循环
# 对应公式: ∇_θ J(θ) ≈ Σ_t ∇_θ log π_θ(a_t|s_t) · [G_t − V_φ(s_t)]
# 与 REINFORCE 唯一的区别: G_t → (G_t − V_φ),期望不变但方差更小
# ============================================================
for episode in range(num_episodes):
trajectory = collect_episode_with_values(env, actor, critic)
returns = compute_returns(trajectory, gamma) # 复用上面定义的 compute_returns
policy_loss = 0 # Actor 损失
value_loss = 0 # Critic 损失
for t in range(len(trajectory)):
log_prob = trajectory[t][0] # log π_θ(a_t|s_t)
value = trajectory[t][2] # V_φ(s_t)
G_t = returns[t] # 蒙特卡洛回报
# 优势估计: A_t ≈ G_t − V_φ(s_t)
# detach(): 阻止 policy_loss 的梯度流入 Critic 参数 φ
advantage = G_t - value.detach()
# Actor 损失: −log π_θ(a_t|s_t) · A_t
# A_t > 0 → 增大该动作概率; A_t < 0 → 降低该动作概率
policy_loss += -log_prob * advantage
# Critic 损失: MSE(V_φ(s_t), G_t)
# 让 Critic 的预测向蒙特卡洛真值靠拢
value_loss += F.mse_loss(value, torch.tensor(G_t))
# Actor 和 Critic 分开更新,互不干扰
actor_optimizer.zero_grad()
policy_loss.backward() # ∂loss/∂θ: 只经过 log π → θ
actor_optimizer.step()
critic_optimizer.zero_grad()
value_loss.backward() # ∂loss/∂φ: 只经过 V_φ → φ
critic_optimizer.step()3. Actor-Critic 架构 (时序差分与单步更新)
关于 Actor-Critic 方法及其变体(A2C、GAE)的系统介绍,推荐 Actor-Critic Methods, A2C and GAE。
先看例子: Actor-Critic 的核心想法是——评价第 1 轮的决策,何必等到面试结束?第 1 轮结束后,我们已经知道两件事:这轮拿了 \(r_1 = 6\) 分,且进入了状态 \(s_2\)。面试顾问(Critic)告诉我们 \(V_\phi(s_2) = 5\),即"从 \(s_2\) 开始平均还能拿 5 分"。
于是我们可以立刻估算:走完第 1 步后的"实际表现" \(\approx r_1 + V_\phi(s_2) = 6 + 5 = 11\)。而 Critic 之前对 \(s_1\) 的预期是 \(V_\phi(s_1) = 9\)。两者之差:
\[\delta_1 = r_1 + \gamma V_\phi(s_2) - V_\phi(s_1) = 6 + 5 - 9 = \mathbf{+2}\]
\(\delta_1 = +2\) 的含义是:实际表现比预期好了 2 分,"讲项目经历"是个不错的决策。关键是——第 1 轮一结束就算出来了,不用等后面两轮!
一般化的算法原理:
上面的 \(\delta_1\) 就是著名的时序差分误差(TD Error)。其核心思想叫自举(Bootstrapping):不再等待真实的完整回报 \(G_t\),而是用 Critic 对下一状态的估值 \(V_\phi(s_{t+1})\) 来"代替"未来的实际奖励:
\[Q(s_t, a_t) \approx r_t + \gamma V_\phi(s_{t+1})\]
将其代入优势函数 \(A(s_t, a_t) = Q(s_t, a_t) - V(s_t)\),就得到了 TD 误差: \[ \delta_t = r_t + \gamma V_\phi(s_{t+1}) - V_\phi(s_t) \]
\(\delta_t\) 近似了优势函数 \(A(s_t, a_t)\),而且只需要走一步(获得 \(r_t\) 和 \(s_{t+1}\))就能计算。
在 Actor-Critic 架构中,我们同时训练两个神经网络:
- Actor(演员/策略网络) \(\pi_\theta(a|s)\):负责选择动作。用 Critic 算出的 \(\delta_t\) 来更新策略: \[ \theta \leftarrow \theta + \alpha \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot \delta_t \]
- Critic(评委/价值网络) \(V_\phi(s)\):负责估计状态价值。目标是让自己的预测越来越准,即最小化 TD 误差的平方: \[ \phi \leftarrow \phi - \beta \nabla_\phi \left( \frac{1}{2} \delta_t^2 \right) \]
用面试的例子理解 Critic 的更新:我们算出了 \(\delta_1 = +2\),说明 Critic 之前对 \(s_1\) 的预估 \(V_\phi(s_1) = 9\) 偏低了——实际的单步证据显示"得了 6 分,且到达了一个价值 5 分的状态",合计预期 \(11\) 分,而 Critic 只预测了 \(9\) 分。
Critic 的目标是减小这个预测误差,即最小化 \(\frac{1}{2}\delta_t^2\)。让我们展开梯度下降的计算,看看它是否真的会让 \(V_\phi(s_1)\) 往上调:
\[\nabla_\phi \frac{1}{2}\delta_t^2 = \delta_t \cdot \nabla_\phi \delta_t\]
由于 \(\delta_t = r_t + \gamma V_\phi(s_{t+1}) - V_\phi(s_t)\),其中"目标值" \(r_t + \gamma V_\phi(s_{t+1})\) 在实际训练中被视为常数(停止梯度),所以:
\[\nabla_\phi \delta_t = -\nabla_\phi V_\phi(s_t)\]
代入更新公式(注意梯度下降的减号和链式法则的减号相消了):
\[\phi \leftarrow \phi - \beta \cdot \delta_t \cdot (-\nabla_\phi V_\phi(s_t)) = \phi + \beta \delta_t \nabla_\phi V_\phi(s_t)\]
当 \(\delta_t = +2 > 0\) 时,最终效果是加上 \(\beta \cdot 2 \cdot \nabla_\phi V_\phi(s_t)\),推动 \(V_\phi(s_1)\) 增大——正好从 \(9\) 往真实值 \(11\) 靠拢。反之,如果 \(\delta_t < 0\)(预估偏高),则会推动 \(V_\phi\) 减小。这就是标准梯度下降自动做到"偏低就调高、偏高就调低"的数学原因。
随着训练迭代,Critic 的预测会越来越准,\(\delta_t\) 会越来越小,Actor 收到的信号也就越来越精确。
回到面试的例子,Actor-Critic 相比前两种方法的两个关键优势就很清楚了:
- 单步更新:第 1 轮一结束就能计算 \(\delta_1\),无需等后续轮次。
- 方差更低:\(\delta_1\) 仅依赖单步的随机性(\(r_1\) 和 \(s_2\)),与第 2、3 轮的随机结果完全解耦。相比 \(G_1\) 累积了三步的随机性,波动自然更小。
代价是引入了偏差(Bias):如果 Critic 对 \(V_\phi(s_2)\) 的估计不准(比如真实值是 \(6\) 而非 \(5\)),\(\delta_1\) 也会偏离真实优势值。这就是经典的偏差-方差权衡(Bias-Variance Trade-off):Actor-Critic 用一定的偏差换来了更低的方差和更高的学习效率。随着训练推进,Critic 的估值会越来越准,偏差也会逐渐减小。
Actor-Critic 完美结合了策略梯度和价值函数的优势,极大地降低了方差,并实现了高效的在线单步更新。然而,它仍然面临着策略更新步长难以控制的问题,过大的更新可能导致策略崩溃。这就引出了下一篇要讲的 TRPO 和 PPO 算法。
Actor-Critic 的完整实现:
import torch
import gymnasium as gym
# ============================================================
# 超参数与环境(同上)
# ============================================================
gamma = 0.99
total_steps = 100_000 # 总训练步数
env = gym.make("CartPole-v1")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
# ============================================================
# 模型定义(与 Baseline 版相同: Actor + Critic)
# 关键区别: 不再需要 G_t,用 TD 误差 δ_t 替代优势估计
# ============================================================
actor = ActorModel(state_dim, action_dim) # 需自行定义
critic = CriticModel(state_dim) # 需自行定义
actor_optimizer = torch.optim.Adam(actor.parameters(), lr=1e-3)
critic_optimizer = torch.optim.Adam(critic.parameters(), lr=1e-3)
# ============================================================
# 训练循环: 每走一步就更新!不需要等回合结束
# 对应公式: θ ← θ + α · ∇_θ log π_θ(a_t|s_t) · δ_t
# 其中 δ_t = r_t + γ·V_φ(s_{t+1}) − V_φ(s_t)
# ============================================================
state, _ = env.reset()
for step in range(total_steps):
state_t = torch.tensor(state, dtype=torch.float32)
# --- 前向传播 ---
dist = actor(state_t) # s_t → π_θ(·|s_t)
action = dist.sample() # a_t ~ π_θ(·|s_t)
log_prob = dist.log_prob(action) # log π_θ(a_t|s_t)
value = critic(state_t).squeeze() # V_φ(s_t): TD 残差的 "预测" 端
# --- 与环境交互(只需走一步!)---
next_state, reward, terminated, truncated, _ = env.step(action.item())
done = terminated or truncated
next_state_t = torch.tensor(next_state, dtype=torch.float32)
# V_φ(s_{t+1}): TD 残差的 "目标" 端
# detach(): 目标值视为常数,不让梯度流回去(类似 DQN 的 target network 思想)
next_value = critic(next_state_t).squeeze().detach()
# --- 计算 TD 误差 δ_t ≈ A(s_t, a_t) ---
# 公式: δ_t = r_t + γ·V_φ(s_{t+1}) − V_φ(s_t)
# (1-done): 终止状态时 V(s_{T+1})=0,不再 bootstrap
td_target = reward + gamma * next_value * (1 - done)
delta = td_target - value # δ_t: 单步 TD 误差 ≈ 优势函数
# --- Actor 更新 ---
# 公式: loss_actor = −log π_θ(a_t|s_t) · δ_t
# delta.detach(): Critic 的误差不应通过 δ 反传到 Actor 参数 θ
actor_loss = -log_prob * delta.detach()
# --- Critic 更新 ---
# 公式: loss_critic = δ_t² = [r_t + γ·V_φ(s') − V_φ(s)]²
# 最小化预测误差,让 V_φ(s_t) 逼近真实价值
critic_loss = delta.pow(2)
actor_optimizer.zero_grad()
actor_loss.backward() # ∂loss/∂θ = −δ · ∂log π/∂θ
actor_optimizer.step()
critic_optimizer.zero_grad()
critic_loss.backward() # ∂loss/∂φ = −2δ · ∂V_φ(s)/∂φ
critic_optimizer.step()
if done:
state, _ = env.reset()
else:
state = next_state对比总结
回到面试的例子,三种算法对第 1 轮"讲项目经历"的评价一目了然:
| REINFORCE | + Baseline | Actor-Critic | |
|---|---|---|---|
| 更新信号 | \(G_t\) | \(G_t - V_\phi(s_t)\) | \(\delta_t = r_t + \gamma V_\phi(s_{t+1}) - V_\phi(s_t)\) |
| 本例数值 | \(12\) | \(+3\) | \(+2\) |
| 信号含义 | 绝对总回报 | 相对于平均的优势 | 单步 TD 误差 |
| 何时可计算 | 回合结束后 | 回合结束后 | 每走一步即可 |
| 梯度方差 | 高(信号幅度大 + 累积多步随机性) | 较低(信号幅度小,但仍累积多步随机性) | 低(信号幅度小 + 仅含单步随机性) |
| 偏差 | 无偏(\(G_t\) 是 \(Q\) 的无偏估计) | 无偏(减去常数不影响期望) | 有偏(取决于 \(V_\phi\) 的精度) |
从 REINFORCE → + Baseline → Actor-Critic,算法的演进路线非常清晰:先解决信号幅度过大的问题(引入基线,将信号从绝对值拉到 0 附近),再解决学习效率低的问题(用 Critic 自举替代完整回报,将多步随机性压缩为单步,同时实现即时更新)。
广义优势估计(GAE):蒙特卡洛与 TD 的统一框架
上面三种算法分别用了蒙特卡洛(\(G_t\))、蒙特卡洛减基线(\(G_t - V\))、单步 TD(\(\delta_t\))来估计优势。但蒙特卡洛无偏却方差大,TD 方差小却有偏——有没有一种方法能在这两个极端之间自由调节?这就是 GAE(Generalized Advantage Estimation)(原始论文)要解决的问题,它是后续 TRPO 和 PPO 算法的基础组件。
三种优势估计方法的关系
不同的估计方法,本质上是在回答同一个问题——"估计 \(Q(s_t, a_t)\) 时,我们应该多大程度地依赖真实观测(实际奖励),多大程度地依赖 Critic 的预测(\(V_\phi\))?"
方法 1:蒙特卡洛估计(完全不信 Critic)。 从 \(t\) 时刻开始,一直走到回合结束,用实际获得的累积奖励替代 \(Q\):
\[\hat{A}_t^{MC} = G_t - V(s_t) = \left(\sum_{l=0}^{T-t-1} \gamma^l r_{t+l}\right) - V(s_t)\]
因为 \(G_t\) 是 \(Q(s_t, a_t)\) 的无偏估计(\(\mathbb{E}[G_t | s_t, a_t] = Q(s_t, a_t)\)),所以 \(\hat{A}_t^{MC}\) 是真实优势的无偏估计。但它累积了从 \(t\) 到 \(T\) 每一步的随机性,方差极大。用面试的例子说:\(G_1 = r_1 + r_2 + r_3\),后两轮的随机性全部混进了对第 1 轮决策的评价。
方法 2:单步 TD 误差(完全信任 Critic)。 只看一步实际奖励,未来的部分全部交给 Critic 预测:
\[\hat{A}_t^{TD} = \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)\]
\(\delta_t\) 仅含一步随机性(\(r_t\) 和 \(s_{t+1}\)),方差很低。但如果 \(V(s_{t+1})\) 不准确,\(\delta_t\) 就会有偏差。用面试的例子说:\(\delta_1 = r_1 + V(s_2) - V(s_1) = 6 + 5 - 9 = +2\),这个 \(+2\) 完全依赖 Critic 对 \(V(s_2) = 5\) 的预估准不准。如果实际后续得分是 \(6\) 而非 \(5\),\(\delta_1\) 就低估了真实优势。
方法 3:n 步估计(折中方案)。 自然的想法是:多看几步实际奖励,减少对 Critic 的依赖。n 步优势估计为:
\[\hat{A}_t^{(n)} = \left(\sum_{l=0}^{n-1} \gamma^l r_{t+l}\right) + \gamma^n V(s_{t+n}) - V(s_t)\]
看 \(n\) 步真实奖励,然后用 Critic 估计剩余部分。\(n\) 越大,偏差越小(用了更多真实数据),但方差越大(累积了更多随机性)。容易验证:\(n = 1\) 时退化为 TD 误差 \(\delta_t\),\(n = T - t\) 时退化为蒙特卡洛估计 \(G_t - V(s_t)\)。
n 步优势估计 = TD 误差的折扣累加
一个关键的数学等式是:n 步优势估计恰好等于前 n 个 TD 误差的折扣累加:
\[\hat{A}_t^{(n)} = \sum_{l=0}^{n-1} \gamma^l \delta_{t+l}\]
我们用面试例子(\(n = 3\),三轮面试,令 \(\gamma = 1\) 简化)来逐项展开验证。先把 3 个 TD 误差写出来:
\[\delta_1 = r_1 + V(s_2) - V(s_1), \quad \delta_2 = r_2 + V(s_3) - V(s_2), \quad \delta_3 = r_3 + V(s_4) - V(s_3)\]
把它们加起来,按类型分组(\(\color{blue}{\text{蓝色 = 真实奖励}}\)、\(\color{green}{\text{绿色 = 正 V 项}}\)、\(\color{red}{\text{红色 = 负 V 项}}\)):
\[\delta_1 + \delta_2 + \delta_3 = \underbrace{\color{blue}{r_1 + r_2 + r_3}}_{\text{真实奖励}} + \underbrace{\color{green}{V(s_2) + V(s_3) + V(s_4)}}_{\text{来自 }+\gamma V(s_{t+l+1})} - \underbrace{\color{red}{V(s_1) + V(s_2) + V(s_3)}}_{\text{来自 }-V(s_{t+l})}\]
现在逐项比较\(\color{green}{\text{绿色}}\)和\(\color{red}{\text{红色}}\)两组(\(\color{gray}{\text{灰色}}\)表示已抵消的项):
\[= \color{blue}{r_1 + r_2 + r_3} + \color{gray}{V(s_2)} + \color{gray}{V(s_3)} + \color{green}{V(s_4)} - \color{red}{V(s_1)} - \color{gray}{V(s_2)} - \color{gray}{V(s_3)}\]
\(\color{gray}{V(s_2)}\) 在绿色组出现一次(\(+\)),在红色组也出现一次(\(-\)),抵消变灰;\(\color{gray}{V(s_3)}\) 同理抵消。中间所有 \(V\) 项两两对消,只剩下首尾:
\[= \color{blue}{(r_1 + r_2 + r_3)} + \color{green}{V(s_4)} - \color{red}{V(s_1)} = \hat{A}_1^{(3)} \quad \checkmark\]
这正是 3 步优势估计的定义!如果回合在第 3 步结束(\(V(s_4) = 0\)),则 \(= G_1 - V(s_1)\),退化为蒙特卡洛。
一般情况(\(\gamma \neq 1\))同理:每个正 \(V\) 项 \(\gamma^{l+1} V(s_{t+l+1})\) 与下一个负 \(V\) 项 \(\gamma^{l+1} V(s_{t+l+1})\) 配对抵消,最终只剩首尾:
\[\sum_{l=0}^{n-1} \gamma^l \delta_{t+l} = \sum_{l=0}^{n-1} \gamma^l r_{t+l} + \gamma^n V(s_{t+n}) - V(s_t) = \hat{A}_t^{(n)} \quad \square\]
这个等式解释了一个常见的困惑:为什么"不属于第 \(t\) 步"的后续 TD 误差 \(\delta_{t+1}, \delta_{t+2}, \ldots\) 也被加进了对动作 \(a_t\) 的优势评价? 答案是:累加后续 TD 误差并不是在"重复衡量动作 \(a_t\) 好不好",而是在用实际观测逐步替换 Critic 的预测——每多加一个 \(\delta\),就多看了一步真实奖励,少依赖一步 Critic 的猜测。
用面试例子来说:\(\delta_1 = +2\) 完全信任 Critic 对 \(V(s_2) = 5\) 的预估。如果面试继续走下去,发现 \(\delta_2 > 0\)(第 2 步实际表现比 Critic 预估好),这说明 \(V(s_2)\) 被低估了——而这正是 \(\delta_1\) 被低估的同一个原因。把 \(\delta_2\) 加进来(2 步估计 \(\hat{A}_1^{(2)} = \delta_1 + \gamma\delta_2\)),就是用第 2 步的实际奖励替换了 Critic 对 \(V(s_2)\) 的不完美预测,修正了偏差。
从 n 步估计到 GAE:指数加权平均
现在问题变成了:n 取多少合适? \(n=1\) 偏差大方差小,\(n=T-t\) 偏差小方差大,中间的 \(n\) 是某种折中。但每个 \(n\) 都给出了真实优势的一个合理估计,选哪个都有道理。
GAE 的巧妙之处在于:不选任何单一的 \(n\),而是把所有 n 步估计做指数加权平均:
\[\hat{A}_t^{\text{GAE}(\gamma,\lambda)} = (1-\lambda) \sum_{n=1}^{\infty} \lambda^{n-1} \hat{A}_t^{(n)}\]
展开来看,各个 n 步估计分到的权重为:
| n 步估计 | 含义 | 权重 | \(\lambda = 0.95\) 时 |
|---|---|---|---|
| \(\hat{A}_t^{(1)} = \delta_t\) | 只看 1 步,完全信任 Critic | \((1-\lambda) = 0.05\) | 5% |
| \(\hat{A}_t^{(2)} = \delta_t + \gamma\delta_{t+1}\) | 看 2 步 | \((1-\lambda)\lambda = 0.0475\) | 4.75% |
| \(\hat{A}_t^{(3)} = \delta_t + \gamma\delta_{t+1} + \gamma^2\delta_{t+2}\) | 看 3 步 | \((1-\lambda)\lambda^2 = 0.0451\) | 4.51% |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) |
权重总和为 \((1-\lambda)(1 + \lambda + \lambda^2 + \cdots) = (1-\lambda) \cdot \frac{1}{1-\lambda} = 1\)。由于 \(\lambda^n\) 随 \(n\) 指数衰减,短步估计的权重总是更大。\(\lambda\) 越接近 \(0\),1 步估计的权重 \((1-\lambda)\) 越接近 \(1\),几乎只用 \(\delta_t\)(低方差、高偏差);\(\lambda\) 越接近 \(1\),各步估计的权重越均匀,等效于看更多步的实际奖励(低偏差、高方差)。
将 \(\hat{A}_t^{(n)} = \sum_{l=0}^{n-1} \gamma^l \delta_{t+l}\) 代入,对于固定的 \(l\),\(\delta_{t+l}\) 出现在所有 \(n \geq l+1\) 的估计中。交换求和顺序:
\[\hat{A}_t^{\text{GAE}} = (1-\lambda) \sum_{l=0}^{\infty} \gamma^l \delta_{t+l} \sum_{n=l+1}^{\infty} \lambda^{n-1} = (1-\lambda) \sum_{l=0}^{\infty} \gamma^l \delta_{t+l} \cdot \frac{\lambda^l}{1-\lambda} = \sum_{l=0}^{\infty} (\gamma\lambda)^l \delta_{t+l}\]
得到 GAE 的标准形式:
\[\boxed{\hat{A}_t^{\text{GAE}(\gamma,\lambda)} = \sum_{l=0}^{T-t-1} (\gamma \lambda)^l \, \delta_{t+l}, \quad \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)}\]
严格推导:\(\lambda = 1\) 时 GAE 退化为蒙特卡洛(无偏)
当 \(\lambda = 1\) 时,GAE 公式变为 \(\hat{A}_t = \sum_{l=0}^{T-t-1} \gamma^l \delta_{t+l}\)。这和上面 n 步估计的 telescoping 完全相同——只是 \(n\) 取到了最大值 \(T - t\)(看完全程)。
仍然用面试例子(\(\gamma = 1\),3 轮面试,\(T - t = 3\))具体展开:
\[\hat{A}_1^{\text{GAE}(1,1)} = \delta_1 + \delta_2 + \delta_3\]
\[= \underbrace{\color{blue}{r_1 + r_2 + r_3}}_{\text{真实奖励}} + \underbrace{\color{gray}{V(s_2)} + \color{gray}{V(s_3)} + \color{green}{V(s_4)}}_{\text{正 V 项}} - \underbrace{\color{red}{V(s_1)} + \color{gray}{V(s_2)} + \color{gray}{V(s_3)}}_{\text{负 V 项}}\]
\[= \color{blue}{(r_1 + r_2 + r_3)} + \color{green}{V(s_4)} - \color{red}{V(s_1)}\]
若 \(s_4\) 为终止状态(\(V(s_4) = 0\)):\(= (r_1 + r_2 + r_3) - V(s_1) = G_1 - V(s_1)\),即蒙特卡洛估计。
一般情况(\(\gamma \neq 1\))同理,抵消规律与上面完全一致(只是每项多了 \(\gamma^l\) 系数,不影响配对抵消),最终只剩首尾:
\[\hat{A}_t^{\text{GAE}(\gamma,1)} = \sum_{l=0}^{T-t-1} \gamma^l r_{t+l} + \gamma^{T-t} V(s_T) - V(s_t)\]
若回合在 \(T\) 时刻终止(终止状态价值为零,\(V(s_T) = 0\)):
\[\hat{A}_t^{\text{GAE}(\gamma,1)} = \underbrace{\sum_{l=0}^{T-t-1} \gamma^l r_{t+l}}_{= \; G_t} - V(s_t) = G_t - V(s_t) = \hat{A}_t^{MC} \quad \square\]
所有 \(V\) 项被望远镜抵消消灭,估计中不再依赖 Critic 的任何预测——这就是 \(\lambda = 1\) 无偏的根本原因。类似地,\(\lambda = 0\) 时 \(\hat{A}_t^{\text{GAE}(\gamma,0)} = \delta_t\),退化为单步 TD。
蒙特卡洛、TD 误差与 GAE 的对比总结
| 蒙特卡洛 \(G_t - V(s_t)\) | TD 误差 \(\delta_t\) | GAE \(\sum (\gamma\lambda)^l \delta_{t+l}\) | |
|---|---|---|---|
| 等价于 | \(\lambda = 1\) 的 GAE | \(\lambda = 0\) 的 GAE | \(\lambda \in (0,1)\) 的加权混合 |
| 公式展开 | \(\sum_{l} \gamma^l r_{t+l} - V(s_t)\) | \(r_t + \gamma V(s_{t+1}) - V(s_t)\) | 所有 n 步估计的指数加权平均 |
| 信任 Critic 程度 | 完全不信(只用 \(V(s_t)\) 作基线) | 完全信任(用 \(V(s_{t+1})\) 替代全部未来) | 部分信任(\(\lambda\) 调节) |
| 偏差 | 无(\(G_t\) 是 \(Q\) 的无偏估计) | 有(\(V(s_{t+1})\) 可能不准) | 介于两者之间 |
| 方差 | 高(累积 \(T-t\) 步随机性) | 低(仅 1 步随机性) | 介于两者之间 |
| 何时可计算 | 回合结束后 | 每走一步即可 | 回合结束后(需后续 \(\delta\)) |
| 物理意义 | 动作 \(a_t\) 走完全程后实际比平均好多少 | 动作 \(a_t\) 的即时表现比 Critic 预期好多少 | 综合即时和多步信息的平滑估计 |
实践中 \(\lambda = 0.95\) 是一个好的折中——保留了 95% 的长期信息,同时通过 \(0.95^l\) 的指数衰减使远处(方差大的)TD 误差权重递减,有效抑制方差。
GAE 的递推实现
GAE 公式可以从后向前递推计算,避免显式求和:
\[ \hat{A}_t = \delta_t + \gamma \lambda \, \hat{A}_{t+1} \]
下面是具体实现:
def compute_gae(rewards, values, gamma=0.99, lam=0.95, dones=None):
"""
广义优势估计 (Generalized Advantage Estimation)
rewards: Tensor [T] 每步即时奖励
values: Tensor [T] 或 [T+1] Critic 对各状态的价值估计
推荐 T+1,最后一个元素是 bootstrap 值 V(s_T)
gamma: 折扣因子,控制对远期奖励的衰减(通常 0.99)
lam: GAE 平滑参数 λ,越大方差越高但偏差越小(通常 0.95)
dones: Tensor [T] (0/1) 1 表示回合在该步结束
用于在 episode 边界处截断 GAE 递推链
"""
T = len(rewards)
# zeros_like 自动继承 device/dtype,多 GPU 训练时不会出错
advantages = torch.zeros_like(rewards)
# 没有提供 dones 时,默认全部为 0(假设一个连续回合,不推荐)
if dones is None:
dones = torch.zeros_like(rewards)
# 如果 values 长度为 T(调用方未提供末状态的 bootstrap 值),末尾补 0
# 等价于假设 V(s_T)=0(终止状态);若回合是被截断而非正常结束,
# 应传入 T+1 维度的 values,让末尾能用 Critic 估计值正确 bootstrap
if len(values) == T:
values = torch.cat([values, torch.zeros(1, device=values.device)])
gae = 0.0 # 递推中的累积量,从末尾往前滚动
for t in reversed(range(T)): # 从 t=T-1 向前递推到 t=0
# TD 残差 δ_t = r_t + γ·V(s_{t+1})·(1-done_t) − V(s_t)
# 当 done_t=1 时,回合已结束,V(s_{t+1}) 属于新回合,用 (1-done) 归零
delta = rewards[t] + gamma * values[t + 1] * (1 - dones[t]) - values[t]
# GAE 递推:Â_t = δ_t + γλ·(1-done_t)·Â_{t+1}
# (1-done_t) 同时截断递推链,防止新回合的优势信号泄漏回旧回合
gae = delta + gamma * lam * (1 - dones[t]) * gae
advantages[t] = gae
return advantages # [Â_0, Â_1, ..., Â_{T-1}]什么是 Bootstrap? 在 TD 误差 \(\delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)\) 中,\(V(s_{t+1})\) 就是 bootstrap——我们不知道从 \(s_{t+1}\) 开始真正能拿多少分,所以用 Critic 的预测值 \(V(s_{t+1})\) 来"代替"看不到的未来回报,这种"用估计值替代真实值"的操作就叫 bootstrap(自举)。
为什么需要
dones? 一个 rollout buffer 往往包含多个回合片段。用面试的例子来说:假设 AI 连续跑了两局面试,数据在 buffer 中紧挨着排列:
位置 \(t=1\) \(t=2\) \(t=3\)(第1局结束) \(t=4\)(第2局开始) \(t=5\) ... 状态 \(s_1^{(1)}\) \(s_2^{(1)}\) \(s_3^{(1)}\) \(s_1^{(2)}\) \(s_2^{(2)}\) ... done 0 0 1 0 0 ... 没有
dones会怎样? 计算 \(t=3\)(第 1 局最后一步)的 TD 误差时:\(\delta_3 = r_3 + \gamma V(s_4) - V(s_3)\)。但 \(s_4\) 是第 2 局的初始状态——一场全新的面试!\(V(s_4)\) 与第 1 局完全无关,不应被当作第 1 局末尾的 bootstrap 值。如果直接使用,等于把"第 2 局开局的预期分数"算进了第 1 局的优势评价,导致估计错误。加上
(1 - done_t)后:当 \(\text{done}_3 = 1\) 时,\((1 - \text{done}_3) = 0\),于是 \(\delta_3 = r_3 + \gamma \cdot V(s_4) \cdot 0 - V(s_3) = r_3 - V(s_3)\)。bootstrap 值被归零,第 1 局的最后一步不再"偷看"第 2 局的信息。同时,GAE 递推链 \(\hat{A}_3 = \delta_3 + \gamma\lambda \cdot 0 \cdot \hat{A}_4 = \delta_3\) 也被截断,第 2 局的优势不会泄漏回第 1 局。
开源代码参考: 在实际应用中,REINFORCE 由于方差过大,几乎不再被单独用于复杂任务;Actor-Critic(特别是其变体 A2C/A3C)则被广泛使用。目前最主流的强化学习开源库如 Stable-Baselines3 和 Hugging Face 的 TRL (Transformer Reinforcement Learning) 都提供了这些基础算法的实现。上面三个算法各自的完整 PyTorch 实现已附在对应小节末尾,从模型定义、数据采集到参数更新的完整前向流程可以直接参考。
参考资料: 本文的理论基础主要来自 Sutton & Barto 的经典教材 Reinforcement Learning: An Introduction,其中 Chapter 13 详细讨论了策略梯度方法。更偏实践的入门推荐 OpenAI Spinning Up,提供了从概念到代码的完整路径。
这些基础算法与大模型 RLHF 的关系: 本文介绍的三种算法都是经典 RL 场景中的理论基础,它们本身没有直接的 RLHF 版本,但它们的核心思想直接催生了大模型对齐中的关键算法:
- Actor-Critic → PPO:PPO 本质上是加了裁剪机制的 Actor-Critic,是目前 RLHF 中最主流的算法。在 RLHF 场景下需要四个模型(Actor、Critic、Reference、Reward)协同工作,详见下一篇。
- REINFORCE → GRPO:GRPO(Group Relative Policy Optimization)的核心思想来自 REINFORCE——对同一个 prompt 生成一组回答,用组内相对排名替代 Critic 的价值估计,彻底去掉了 Critic 模型。
附录:强化学习的分类体系
学完上面的算法后,我们回过头来梳理一下强化学习的两个核心分类维度,这对理解后续系列文章中各算法的定位非常重要。
在线强化学习 vs 离线强化学习
根据训练过程中是否需要与环境实时交互,强化学习可以分为两大范式:
在线强化学习(Online RL):训练时,智能体主动与环境交互——执行动作、观察反馈、收集新数据,然后用这些新鲜数据更新策略。每一轮训练都需要"真的去玩"。
离线强化学习(Offline RL):训练时,不与环境交互,只从一批预先收集好的固定数据集中学习。数据可能是其他策略(甚至人类专家)收集的,训练过程中不再产生新数据。
继续用训狗的例子:
- 在线 RL:你每天带狗到公园训练,狗做出动作、你给奖惩、它当场学习。训练质量取决于你和狗的实时互动。
- 离线 RL:你给狗看一堆"别人家狗"的训练录像——哪些动作得了奖、哪些被罚了——让它从录像中自己总结经验,不需要亲自下场。
On-Policy vs Off-Policy
这是另一个容易和在线/离线混淆的分类维度。它关注的不是"是否与环境交互",而是用来更新策略的数据是谁产生的。
On-Policy(同策略):用当前正在训练的策略 \(\pi_\theta\) 产生的数据来更新 \(\pi_\theta\) 自己。每次策略更新后,旧数据就"过期"了,必须重新采集。
Off-Policy(异策略):用其他策略(称为行为策略 \(\beta\))产生的数据来更新目标策略 \(\pi_\theta\)。数据可以来自旧版本的自己、其他算法、甚至人类专家,通过重要性采样等技术修正分布差异。
还是用训狗的例子:
- On-Policy:你亲自带狗训练,狗每次做出动作后你立刻给反馈,它根据自己刚才的表现学习。学完一轮后,之前的经验就不再使用,因为狗的行为模式已经变了。
- Off-Policy:你让狗看别的狗(或者它自己以前)的训练录像,从中学习哪些动作好、哪些不好。录像不是它当前策略产生的,但仍然可以从中提取有用信息。
两个维度的交叉分类
在线/离线和 on-policy/off-policy 是两个独立的维度,它们的组合产生了不同类型的算法:
| On-Policy | Off-Policy | |
|---|---|---|
| 在线(Online) | REINFORCE、A2C:每次用当前策略采集数据,用完即弃 | DQN、SAC:与环境交互,但数据存入 replay buffer 反复使用 |
| 离线(Offline) | (不存在:不交互就无法用当前策略采集数据) | DPO、KTO:从预先收集的固定数据集学习 |
PPO 和 GRPO 在哪里? 它们是在线 + 近似 on-policy。严格的 on-policy 要求每次更新后立刻丢弃旧数据,但 PPO/GRPO 会把同一批数据复用 K 个 epoch(通常 K=3~4),通过 clip 机制或重要性采样权重来限制新旧策略的偏差,使得复用旧数据不会导致严重的分布失配。这种"采一批、用几轮、再采新的"的方式,比纯 on-policy 高效,又比完全 off-policy 稳定。
在大模型对齐的语境下:
| 在线 RL | 离线 RL | |
|---|---|---|
| 训练时 | 模型实时生成回答,奖励模型/环境打分 | 从预先收集好的偏好数据中学习 |
| 典型算法 | PPO、GRPO、DAPO、REINFORCE++ | DPO、IPO、KTO |
| 优点 | 能不断探索新策略,利用最新反馈 | 无需 4 模型架构,训练简单高效 |
| 缺点 | 需要维护生成+打分的完整流水线 | 受限于离线数据的质量和覆盖范围 |
参考资料:
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction. MIT press.
- Schulman, J., Moritz, P., Levine, S., Jordan, M., & Abbeel, P. (2015). High-Dimensional Continuous Control Using Generalized Advantage Estimation. ICLR 2016.
- Part 3: Intro to Policy Optimization — OpenAI Spinning Up
- Policy Gradient Algorithms — Lil'Log
- Actor-Critic Methods, A2C and GAE