笔记|强化学习(五):Flow-GRPO 与图像生成应用(基于 Flux 的代码解析)
本文为 RL 系列第五篇。在完整梳理了从 REINFORCE 到 PPO、DPO,再到最新 GRPO 的演进路线后,我们将目光转向图像生成领域。本文将结合
flow_grpo开源代码库,深入解析如何将 GRPO 算法应用于基于 Flow Matching 的图像生成模型(如 Flux)的微调中。方法学与系统实验见论文 Flow-GRPO: Training Flow Matching Models via Online RL(文中以 SD3.5 等为主报告;仓库实现覆盖 Flux)。
图像生成中的强化学习
先用一个例子理解为什么需要 RL。
假设你用一个 Flux 模型生成图像,给定 Prompt:"一只橘猫坐在蓝色沙发上"。模型可能生成以下几种结果:
| 生成结果 | 问题 |
|---|---|
| 一只白色猫坐在蓝色沙发上 | 颜色不对(应该是橘猫) |
| 一只橘猫站在蓝色沙发旁边 | 动作不对(应该是"坐在") |
| 一只橘猫坐在蓝色沙发上,画面清晰 | 符合预期 |
| 一只橘猫坐在蓝色沙发上,但画面模糊 | 质量差 |
传统的训练方式(Flow Matching 损失)只是让模型学会"生成看起来像训练集的图像"。但训练集里可能有模糊的、构图差的、与 Prompt 不一致的图像——模型无法区分好坏。
RL 的价值:我们训练一个“代理奖励模型”(Proxy Reward Model, RM,如 PickScore 或 ImageReward)来给图像打分。模型自己生成图像 → RM 打分 → 模型根据分数调整自己。这就是 RLHF 在图像生成中的应用。
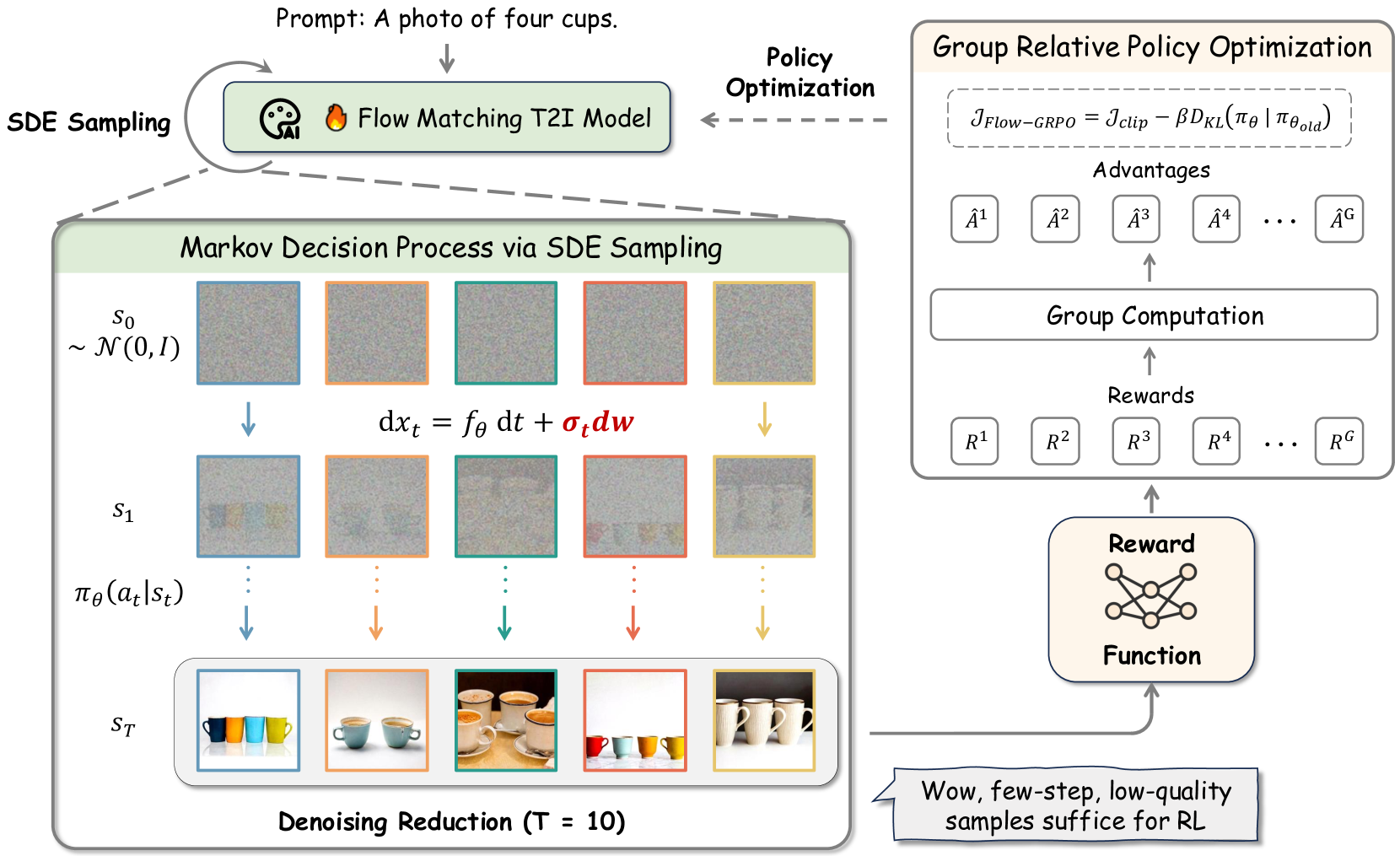
Flow-GRPO 框架解析:基于组内相对优势的策略优化
先看例子:对于 Prompt "一只橘猫坐在蓝色沙发上",我们让 Flux 模型生成 \(G = 4\) 张图像,RM 分别打分:
| 图像 | 描述 | 奖励 \(r_i\) | 相对优势 \(\hat{A}_i\) |
|---|---|---|---|
| 图 1 | 橘猫坐沙发,画面清晰 | \(r_1 = 0.9\) | \(+1.27\) |
| 图 2 | 橘猫坐沙发,稍微模糊 | \(r_2 = 0.6\) | \(-0.12\) |
| 图 3 | 白猫坐沙发(颜色错) | \(r_3 = 0.3\) | \(-1.50\) |
| 图 4 | 橘猫坐沙发,普通水平 | \(r_4 = 0.7\) | \(+0.35\) |
(均值 \(\mu_R = 0.625\),标准差 \(\sigma_R \approx 0.22\))
跟上一篇 GRPO 的做法完全一样:图 1 和图 4 高于平均(正优势),模型学习生成更像它们的图;图 3 远低于平均(负优势),模型学习远离这种生成方式。不需要 Critic 网络,只需要多生成几张图做对比。
核心思考出发点:由于像 Flux 这样的图像生成模型参数量达到百亿级别,传统的 PPO 算法由于需要额外的 Critic 网络,显存开销极大。因此,Flow-GRPO 采用了 GRPO 算法——移除了 Critic,用"组内相对评分"来实现高效的在线强化学习。
核心挑战:如何在连续生成过程中定义 \(\log \pi_\theta\)?
在 LLM 中,动作(Action)是离散的词表 Token,\(\log \pi_\theta(a|s)\) 就是 softmax 输出的对数概率——定义清晰、计算简单。然而在 Flow Matching 中,生成过程是一个连续的常微分方程(ODE)求解过程,没有天然的"离散动作"概念。
用例子理解:LLM 生成文本就像逐字写作——每个字是一个离散的"动作",概率就是词表上的 softmax。而 Flux 生成图像像是画画——每个时间步的"动作"是在画布上做一次连续的涂抹(从噪声图向清晰图的一步变换),这是一个高维连续向量,不存在离散概率。
将去噪过程建模为 MDP
Flow-GRPO 的第一个关键设计是:将 Flow Matching 的去噪过程定义为一个 马尔可夫决策过程:
| MDP 要素 | LLM (GRPO) | 图像生成 (Flow-GRPO) |
|---|---|---|
| 状态 \(s_t\) | \((x, y_{<t})\) (Prompt + 已生成 token) | \((x_t, t, c)\) (当前噪声图 + 时间步 + 文本条件) |
| 动作 \(a_t\) | 下一个 token \(y_t \in \mathcal{V}\)(离散) | 预测的速度场 \(v_\theta(x_t, t, c)\)(连续向量) |
| 转移 | 确定性:拼接 \(y_t\) 到序列 | 确定性 ODE 步:\(x_{t-\Delta t} = x_t - \Delta t \cdot v_\theta\) |
| 奖励 | 稀疏奖励(仅在整句完成后获得) | 稀疏奖励(仅在 \(t=0\) 生成完整图像后获得) |
由于这是一个典型的稀疏奖励(Sparse Reward)设定——中间去噪步的即时奖励均为 0,只有在轨迹终点才能获得 RM 的打分。这在数学上构成了长视野的信用分配(Credit Assignment)问题,因此我们需要计算整条轨迹的累积对数概率来进行策略更新。
推导 Flow Matching 中的对数概率
在 Flow Matching 框架中,前向过程(加噪)定义为线性插值:
\[ x_t = (1 - t) \cdot x_0 + t \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) \]
其中 \(x_0\) 是干净图像,\(\epsilon\) 是纯噪声,\(t \in [0, 1]\)。模型 \(v_\theta(x_t, t, c)\) 学习预测速度场(即 \(x_0\) 到 \(\epsilon\) 方向的向量场)。
在去噪(生成)过程中,每一步的转移可以写成:
\[ x_{t - \Delta t} = x_t - \Delta t \cdot v_\theta(x_t, t, c) \]
如何从这个过程中提取对数概率? 确定性 ODE 没有概率可言——给定初始噪声 \(x_T\),每步转移是唯一确定的,不存在"选择 A 而非 B"的随机性,自然也就没有 \(\log\pi_\theta\) 可以计算。
解决思路(三步走):
- 引入随机性:在 ODE 的每一步注入高斯噪声,将确定性 ODE 改为随机的 SDE。这样每步转移就变成了一个高斯分布,\(\log\pi_\theta\) 就有了。
- 保持分布不变:光加噪声会破坏生成质量。我们需要同时加入 Score Function 纠偏项,使改造后的 SDE 在统计分布上与原始 ODE 完全等价(即生成的图像质量不变)。
- 提取对数概率:从 SDE 的高斯转移核中直接计算每步的 \(\log p(x_{t-\Delta t} | x_t)\),累加得到整条轨迹的 \(\log\pi_\theta\)。
以下我们按这三步展开。
1. 为什么要引入 SDE 与 Score Function?(第一步:引入随机性)
在纯 ODE 采样中,模型就像是沿着一条设定好的轨道平滑地滑向终点(只需速度 \(v_\theta\) 即可更新 \(x_t\))。但 Flow-GRPO 为了让强化学习能够“试错”和“探索”,引入了 SDE(随机微分方程),也就是在滑行的过程中加入随机的扰动(噪声)。
问题来了:如果盲目地加入随机噪声,生成的轨迹就会偏离真实图像的流形(Manifold),最终生成崩坏的画面。
解决方案:我们需要一个“指南针”来纠正这种偏离,这个指南针就是 Score Function(分数函数 \(\nabla_{x_t} \log p_t(x_t)\))。它在数学上指向数据分布密度增加(更接近真实图像分布)的方向。一旦随机探索导致偏航,Score 修正项会提供一个指向高密度区域的拉力。
Score 在 SDE 中的数学角色:将去噪 ODE 转换为逆向 SDE 后(完整推导见下文 Section 2),每一步去噪更新变为(注意时间方向:\(t \to t - \Delta t\),即生成/去噪方向):
\[x_{t-\Delta t} = \underbrace{(x_t - \Delta t \cdot v_\theta)}_{\text{逆向 ODE 漂移}} + \underbrace{\tfrac{1}{2}g^2 \cdot \nabla_{x_t}\log p_t(x_t) \cdot \Delta t}_{\text{Score 纠偏}} + \underbrace{g\sqrt{\Delta t}\cdot\epsilon}_{\text{随机探索}}\]
第一项是原始 ODE 的确定性去噪;第三项是为 RL 注入的随机噪声;第二项就是 Score 纠偏——它的方向指向数据高密度区域,恰好抵消噪声带来的分布偏移。
回到主线(第三步:提取对数概率):现在我们已经证明了 SDE 不会破坏分布。这意味着我们可以放心地使用 SDE 的高斯转移核来计算 \(\log\pi_\theta\)——因为每一步 \(x_{t-\Delta t} | x_t\) 都是一个高斯分布,其对数概率可以直接写出来。我们将在后续代码解析中看到这一步的具体实现。
但要使用这个 SDE,还需要解决一个实际问题:公式中的 Score \(\nabla_{x_t}\log p_t(x_t)\) 怎么算?这就用到了高斯特威迪公式(Gaussian Tweedie's Formula, Efron 2011):
Tweedie 公式是一个适用于指数族分布的广义定理,在各向同性高斯扰动核的特例下,它证明了一个深刻的结论:Score 可以通过贝叶斯后验均值 \(\mathbb{E}[x_0 \mid x_t]\)(即模型预测的 \(\hat{x}_0\))来反向精确表达。
其核心数学公式为: \[ \underbrace{\mathbb{E}[\mu_{x_t} \mid x_t]}_{\text{对真实信号的最优估计}} = \underbrace{x_t}_{\text{带噪观测}} + \underbrace{\sigma_t^2 \nabla_{x_t} \log p_t(x_t)}_{\text{噪声方差 × 密度上升方向}} \]
各项的物理意义:
- \(x_t\)(带噪观测):你当前看到的"含噪图像",它是真实信号 \(\mu_{x_t}\) 加上高斯噪声的结果。
- \(\nabla_{x_t}\log p_t(x_t)\)(Score):指向数据分布密度增大的方向——直觉上就是"图像变得更真实"的方向。
- \(\sigma_t^2\)(噪声方差):噪声越大(\(\sigma_t^2\) 越大),你对当前观测 \(x_t\) 的信任度越低,修正力度就越大;噪声越小,\(x_t\) 本身已经接近真实信号,修正幅度也越小。
整个公式的含义:对含噪观测的最优去噪 = 原始观测 + 沿密度上升方向的修正,修正幅度由噪声水平自适应调节。这在统计学中被称为"收缩估计"(Shrinkage Estimation)——将噪声观测"收缩"向数据分布的中心。
经过移项,即可得到 Score 的表达式: \[ \nabla_{x_t} \log p_t(x_t) = -\frac{x_t - \mathbb{E}[\mu_{x_t} \mid x_t]}{\sigma_t^2} \] (注:对于 Rectified Flow,\(\mu_{x_t} = (1-\sigma)x_0\),因此 \(\mathbb{E}[\mu_{x_t} \mid x_t] = (1-\sigma)\mathbb{E}[x_0 \mid x_t]\))
这使得神经网络无需直接拟合 Score,而是可以通过预测干净图像 \(x_0\) 间接得到。
以下推导的目标:将上述通用的 Tweedie 公式落实到 Rectified Flow 中,推导出 Score 的可计算表达式——即如何从模型预测的 \(v_\theta\) 直接算出 \(\nabla_{x_t}\log p_t(x_t)\)。
推导:在 Rectified Flow 中,\(x_t = (1-\sigma)x_0 + \sigma \epsilon\)(\(\epsilon \sim \mathcal{N}(0,I)\)),因此条件分布为 \(p(x_t | x_0) = \mathcal{N}((1-\sigma)x_0,\; \sigma^2 I)\)。对高斯对数密度求梯度,条件 Score 为:
\[\nabla_{x_t} \log p(x_t | x_0) = -\frac{x_t - (1-\sigma)x_0}{\sigma^2}\]
但上式是给定 \(x_0\) 的条件 Score,而我们需要的是不知道 \(x_0\) 时的边缘 Score \(\nabla_{x_t}\log p_t(x_t)\)。从边缘分布的定义出发逐步推导:
\[ \begin{aligned} \nabla_{x_t}\log p_t(x_t) &= \frac{\nabla_{x_t} p_t(x_t)}{p_t(x_t)} & \text{(Score 的定义)}\\[6pt] &= \frac{\nabla_{x_t} \int p(x_t|x_0)\,p(x_0)\,dx_0}{p_t(x_t)} & \text{(边缘分布 = 对所有 $x_0$ 积分)}\\[6pt] &= \frac{\int \nabla_{x_t} p(x_t|x_0)\,p(x_0)\,dx_0}{p_t(x_t)} & \text{(交换梯度与积分)}\\[6pt] &= \int \frac{p(x_t|x_0)\,p(x_0)}{p_t(x_t)} \cdot \nabla_{x_t}\log p(x_t|x_0)\,dx_0 & \text{(利用 $\nabla f = f \cdot \nabla\log f$)}\\[6pt] &= \int p(x_0|x_t) \cdot \nabla_{x_t}\log p(x_t|x_0)\,dx_0 & \text{(贝叶斯公式:$\frac{p(x_t|x_0)p(x_0)}{p_t(x_t)} = p(x_0|x_t)$)}\\[6pt] &= \mathbb{E}_{p(x_0|x_t)}\!\left[\nabla_{x_t}\log p(x_t|x_0)\right] & \text{(写成期望形式)} \end{aligned} \]
即:边缘 Score = 条件 Score 在后验分布下的期望。代入条件 Score 公式并将常数项提到期望外面:
\[ \nabla_{x_t}\log p_t(x_t) = \mathbb{E}_{p(x_0|x_t)}\!\left[-\frac{x_t - (1-\sigma)x_0}{\sigma^2}\right] = -\frac{x_t - (1-\sigma)\,\mathbb{E}[x_0|x_t]}{\sigma^2} \]
这就是 Tweedie 公式在 Rectified Flow 中的具体形式——Score 完全由后验均值 \(\mathbb{E}[x_0|x_t]\) 决定。实际生成时,我们用模型速度场反推 \(\hat{x}_0 = x_t - \sigma \cdot v_\theta\) 来近似 \(\mathbb{E}[x_0|x_t]\)。
2. SDE 离散化公式链
下面将上述连续 SDE 逐步离散化。为保证学术严谨性,本文将 \(t \in [0,1]\) 严格作为连续时间变量(\(t=1\) 为纯噪声),而将 \(\sigma\) 定义为离散化采样时的调度节点(Noise Schedule)。设当前时间步为 \(\sigma\),模型预测速度场为 \(v_\theta\),扩散系数为 \(g(\sigma)\),离散步长为 \(\Delta\sigma = \sigma_{\text{next}} - \sigma < 0\)(去噪方向),对应正向时间增量 \(\Delta t = -\Delta\sigma > 0\)。
公式 ①:Tweedie 反推干净样本
\[\hat{x}_0 = x_t - \sigma \cdot v_\theta \tag{①}\]
利用 Rectified Flow 的直线插值 \(x_t = (1-\sigma)x_0 + \sigma x_1\)(其中 \(x_1\) 为纯噪声),速度场 \(v_\theta\) 训练目标为预测 \(x_1 - x_0\)。因此 \(x_t = x_0 + \sigma(x_1 - x_0) = x_0 + \sigma v_\theta\),可直接推导出 \(\hat{x}_0 = x_t - \sigma v_\theta\)。
公式 ②:Score Function(Tweedie 估计)
将 ① 代入 Score 定义 \(\nabla_{x_t}\log p_t = -\frac{x_t - (1-\sigma)\hat{x}_0}{\sigma^2}\):
\[\nabla_{x_t}\log p_t(x_t) = -\frac{x_t - (1-\sigma)\hat{x}_0}{\sigma^2} = -\frac{x_t + (1-\sigma)v_\theta}{\sigma} \tag{②}\]
公式 ③:SDE 转移均值(ODE 漂移 + Score 纠偏)
根据第一步推导的通用 SDE 形式,并结合离散步长 \(\Delta\sigma < 0\)(对应 \(\Delta t = -\Delta\sigma\)),通用的单步均值更新可以写为: \[\mu = \underbrace{(x_t + v_\theta \Delta\sigma)}_{\text{ODE 漂移}} - \underbrace{\frac{1}{2}g^2 \nabla_{x_t}\log p_t(x_t) \Delta\sigma}_{\text{Score 纠偏}}\]
将公式 ② 中的 Score 代入上述一般式,即可得到合并后的均值: \[\mu = \underbrace{(x_t + v_\theta \Delta\sigma)}_{\text{ODE 漂移}} + \underbrace{\tfrac{1}{2} \frac{g^2}{\sigma} \cdot (x_t + (1-\sigma)v_\theta) \cdot \Delta\sigma}_{\text{Score 纠偏}} \tag{③}\]
为什么需要 Score 纠偏? 设真实的下一步分布 \(p_{t-\Delta t}\) 具有某个特定的方差 \(\Sigma_{\text{true}}\)。如果仅在 ODE 落点上直接叠加噪声(跳过 Score 修正项),采样结果的分布为 \(\mathcal{N}(\mu_{\text{ODE}},\; g^2\Delta t \cdot I)\)。这里的方差 \(g^2\Delta t\) 是我们额外注入的,它叠加在真实分布的不确定性之上,使得样本的整体散布范围比 \(p_{t-\Delta t}\) 更宽——这就是分布膨胀(即协方差矩阵被人为增大)。随步数累积,这种逐步膨胀的分布会越来越远离真实流形,最终导致图像崩坏。Score 纠偏的作用是:在加噪声之前,先沿数据高密度方向(\(\nabla\log p_t\))微调均值,精确补偿噪声带来的方差增量,使得加完噪声后的样本分布恰好等于目标分布 \(p_{t-\Delta t}\)。若 \(g=0\),修正项为零,退化为纯 ODE。
均值收缩与方差膨胀的对冲:Score 纠偏并不是在"消除"噪声增加的方差——单步的方差确实增大了 \(g^2\Delta t\)。它的机制是均值收缩:Score \(\nabla\log p_t\) 对不同位置的样本施加不同强度的"向内拉力"——分布边缘的样本受力大(Score 大),分布中心的样本几乎不动(Score 接近零)。这使得所有样本的均值分布变得更集中(补偿了噪声的扩散)。从整体来看:
\[\underbrace{\text{均值收缩带来的"聚拢"效应}}_{\text{Score 修正项}} + \underbrace{\text{噪声带来的"扩散"效应}}_{\text{$g\sqrt{\Delta t}\cdot\epsilon$}} = \text{互相抵消}\]
Fokker-Planck 方程严格证明了这一点:漂移项的聚拢效应 \(-\nabla\cdot(\mu\,p)\) 与扩散项 \(\frac{1}{2}g^2\nabla^2 p\) 在 Score 系数恰好取 \(\frac{1}{2}g^2\) 时逐项完美对消,使 SDE 的分布演化方程退化为与纯 ODE 完全相同的 Liouville 方程。
公式 ④:SDE 采样
\[x_{t-\Delta t} = \mu + g\sqrt{\Delta t} \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) \tag{④}\]
公式 ③④ 合起来构成 SDE 一步:先计算修正均值 \(\mu\),再以 \(\mu\) 为中心重采样。条件分布为 \(p(x_{t-\Delta t} \mid x_t) = \mathcal{N}(\mu,\; g^2 \Delta t \cdot I)\)。
边缘分布不变性:③④ 的设计保证 SDE 采样与纯 ODE 采样在统计意义上遵循相同的边缘分布——图像质量和多样性的总体特征一致。但单条轨迹变为随机的:同一初始噪声下,ODE 每次产出相同图像,SDE 每次产出不同图像。此性质使 GRPO 能在同一 Prompt 下生成多张不同图像做组内对比,同时不因探索而降低生成质量。
公式 ⑤:单步对数概率(单维度)
由公式 ③④ 可知,\(x_{t-\Delta t} \mid x_t\) 服从均值为 \(\mu\)、方差为 \(g^2\Delta t\) 的高斯分布。对一维高斯 \(\mathcal{N}(\mu, \sigma^2)\) 取对数:
\[\log p(x) = \log\left[\frac{1}{\sqrt{2\pi}\,\sigma}\exp\!\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)\right] = -\frac{(x-\mu)^2}{2\sigma^2} - \log\sigma - \tfrac{1}{2}\log(2\pi)\]
代入 \(\sigma^2 = g^2\Delta t\)(即 \(\sigma = g\sqrt{\Delta t}\)),即可得到:
\[\log p_\theta(x_{t-\Delta t} \mid x_t, c) = -\frac{(x_{t-\Delta t} - \mu)^2}{2\,g^2\,\Delta t} - \log(g\sqrt{\Delta t}) - \tfrac{1}{2}\log(2\pi) \tag{⑤}\]
严格的多元高斯对数似然应对所有维度 \(d\) 求和,上式为单维度(单像素)形式。
后两项(归一化常数)仅依赖 \(g\) 和 \(\Delta t\),不含策略参数 \(\theta\)。因为它们是时间步相关的常数项,在计算 GRPO 的 importance ratio 所需的新旧策略对数概率之差(\(\log\pi_\theta^{\text{new}} - \log\pi_\theta^{\text{old}}\))时会直接相减抵消,对梯度无贡献,但代码实现时通常会保留它们以便于数值验证与调试。
公式 ⑥:整条轨迹对数概率
\[\log \pi_\theta(\text{trajectory} \mid c) = \sum_{k=1}^{T} \log p_\theta(x_{t_k - \Delta t} \mid x_{t_k}, c) \tag{⑥}\]
与 LLM 中 token 级对数概率求和形式完全对应,至此 GRPO 框架可无缝迁移到图像生成。
3. DanceGRPO:显式分解法(直观实现)
DanceGRPO 的实现忠实还原了公式 ①②③ 的逐步分解结构,每一行代码都能与数学公式一一对应,便于理解原理。
实现公式(直接对应前文的公式链):
- 公式 ① → Tweedie 预估:\(\hat{x}_0 = x_t - \sigma v_\theta\)
- 公式 ② → Score 预估:\(\nabla_{x_t}\log p_t = -\frac{x_t - (1-\sigma)\hat{x}_0}{\sigma^2}\)
- 公式 ③ → 均值更新:\(\mu = \underbrace{(x_t + v_\theta \Delta\sigma)}_{\text{ODE 漂移}} - \underbrace{\frac{1}{2}\eta^2 \nabla_{x_t}\log p_t \cdot \Delta\sigma}_{\text{Score 纠偏}}\)
- 公式 ④ → 采样:\(x_{t-\Delta t} = \mu + \eta\sqrt{-\Delta\sigma}\cdot\epsilon\)
- 公式 ⑤ → 对数概率:\(\log p = -\frac{(x_{t-\Delta t} - \mu)^2}{2\,\eta^2(-\Delta\sigma)}\)(省略常数项)
import math
import torch
from typing import Optional
def dance_grpo_step(
model_output: torch.Tensor, # v_θ
latents: torch.Tensor, # x_t
eta: float, # 噪声强度(恒定 g = η)
sigmas: torch.Tensor, # σ 调度表
index: int, # 当前步索引
prev_sample: torch.Tensor, # 外部已采样则传入,否则 None
grpo: bool, # True=返回 log_prob
sde_solver: bool, # True=SDE;False=ODE
):
device = latents.device
sigma = sigmas[index].to(device)
sigma_prev = sigmas[index + 1].to(device)
dsigma = sigma_prev - sigma # < 0(去噪方向)
delta_t = sigma - sigma_prev # > 0
# 【公式 ①】Tweedie 反推: x̂_0 = x_t - σ·v_θ
pred_original_sample = latents - sigma * model_output
# ── ODE 漂移: μ = x_t + v_θ·Δσ ──
prev_sample_mean = latents + dsigma * model_output
# 单步标准差: std = η·√(Δt)
std_dev_t = eta * torch.sqrt(delta_t)
if sde_solver:
# 【公式 ②】Score 估计: -(x_t - (1-σ)x̂_0) / σ²
score_estimate = -(latents - pred_original_sample * (1 - sigma)) / sigma**2
# 【公式 ③】SDE 均值: μ += -½·η²·Score·Δσ
prev_sample_mean = prev_sample_mean + (-0.5 * eta**2 * score_estimate) * dsigma
# 【公式 ④】SDE 采样: x_next = μ + std·ε
if grpo and prev_sample is None:
prev_sample = (prev_sample_mean + torch.randn_like(prev_sample_mean) * std_dev_t
if sde_solver else prev_sample_mean)
# 【公式 ⑤】对数概率: -(x-μ)²/(2σ²)(省略常数项)
if grpo:
log_prob = -((prev_sample.detach().float() - prev_sample_mean.float()) ** 2
) / (2 * std_dev_t**2)
log_prob = log_prob.mean(dim=tuple(range(1, log_prob.ndim)))
return prev_sample, pred_original_sample, log_prob
return prev_sample_mean, pred_original_sample工程缺陷:虽然直观,但 DanceGRPO 的恒定噪声 \(g = \eta\) 存在两个问题:(1) Score
中直接除以 sigma**2,当 \(\sigma
\to 0\) 时极易导致 NaN;(2) 需要显式分配
pred_original_sample 和 score_estimate 等中间
Tensor,增加显存开销。
4. Flow-GRPO:算子融合与自适应噪声(工程优化)
Flow-GRPO 在数学上与 DanceGRPO 完全等价,但通过两个关键改进大幅提升了数值稳定性和计算效率:
改进一:自适应噪声 \(g^2 = \frac{\sigma \eta^2}{1-\sigma}\)
代入公式 ③ 中 Score 纠偏项的系数 \(\frac{g^2}{2\sigma}\),\(\sigma\) 恰好消去:
\[\frac{g^2}{2\sigma} = \frac{1}{2\sigma} \cdot \frac{\sigma \eta^2}{1-\sigma} = \frac{\eta^2}{2(1-\sigma)}\]
避免了 \(\sigma \to 0\) 时除以极小值的数值崩溃风险。
改进二:算子融合(消除中间变量)
将 Score 和 \(\hat{x}_0\) 全部代数消去,只保留 \(x_t\) 和 \(v_\theta\) 的标量系数:
\[\mu = x_t + v_\theta \Delta\sigma + \frac{\eta^2}{2(1-\sigma)}(x_t + (1-\sigma)v_\theta)\Delta\sigma\]
合并同类项后得到算子融合形式:
\[\mu = x_t\left(1 + \frac{\eta^2}{2(1-\sigma)}\Delta\sigma\right) + v_\theta\left(1 + \frac{\eta^2}{2}\right)\Delta\sigma \tag{③'}\]
无需计算 \(\hat{x}_0\) 和 Score,直接用标量乘法完成更新。
以下是 Flow-GRPO 的核心代码实现,直接使用上述公式 ③':
目标:给定当前状态 \(x_t\) 和速度 \(v_\theta\),计算下一步的采样值 \(x_{t-\Delta t}\) 以及该步转移的高斯对数概率 \(\log p(x_{t-\Delta t} \mid x_t)\)。 实现公式:
- 均值更新:\(\mu = x_t \left( 1 + \frac{\eta^2}{2(1-\sigma)} \Delta\sigma \right) + v_\theta \left( 1 + \frac{\eta^2}{2} \right) \Delta\sigma\)
- 采样计算:\(x_{t-\Delta t} = \mu + g(\sigma)\sqrt{-\Delta\sigma}\cdot\epsilon\)
- 对数概率:\(\log p = -\frac{(x_{t-\Delta t} - \mu)^2}{2\,g(\sigma)^2(-\Delta\sigma)} - \log(g(\sigma)\sqrt{-\Delta\sigma}) - \frac{1}{2}\log(2\pi)\)
import math
import torch
from typing import Optional
# 从1->0 是噪声到清晰图像
def flow_grpo_step(
model_output: torch.Tensor, # Transformer 输出的速度 v_θ (B, seq, hidden)
latents: torch.Tensor, # 当前 x_t (float32)
eta: float, # SDE 噪声强度系数
sigmas: torch.Tensor, # 完整 σ 调度表
index: int, # 当前步索引 i
prev_sample: torch.Tensor, # 若外部已采样则传入,否则 None
generator: Optional[torch.Generator] = None, # 随机数生成器
determistic: bool = False, # True=ODE(覆盖噪声采样)
sde_type: str = "sde", # "sde" 或 "cps"
noise_level: Optional[float] = None, # 覆盖 eta 的显式噪声水平
):
"""MixGRPO 单步更新:由速度场 v_θ 更新 latent,计算 SDE 转移的 log_prob。
做什么:给定当前 x_t 和模型预测 v,执行一步 ODE 或 SDE 转移到 x_{t-Δ}。
怎么做:
1. 从 σ 调度读取 σ_i → σ_{i+1},算步长 dt = σ_{i+1} - σ_i (< 0)
2. 预测 x̂_0 = x_t - σ·v
3. ODE:x_{next} = x + dt·v(确定性欧拉步)
SDE:构造均值 μ 和标准差 σ_eff,采样 x_{next} ~ N(μ, σ_eff²)
4. 计算 log N(x_{next}; μ, σ_eff²) 作为策略 log_prob
返回:(x_{next}, x̂_0, log_prob, μ, σ_eff)
"""
device = model_output.device
# ── 读取相邻 σ 节点 ──
sigma = sigmas[index].to(device)
sigma_prev = sigmas[index + 1].to(device)
sigma_max = sigmas[1].item() # 用于 σ=1 时的数值稳定替换
dt = sigma_prev - sigma # 负值 = 沿去噪方向前进
if prev_sample is not None and generator is not None:
raise ValueError(
"Cannot pass both generator and prev_sample. Please make sure that either `generator` or"
" `prev_sample` stays `None`."
)
# ════════════════════════════════════════════════════════════════════
# sde_type 分支:决定噪声注入公式。ODE 不是单独分支,而是在每个分支内
# 通过 determistic=True 覆盖采样结果为纯 Euler 步 x + dt·v。
# ════════════════════════════════════════════════════════════════════
if sde_type == "sde":
# ── 标准 SDE:噪声量自适应 g(σ) = √(σ/(1-σ)) · η ──
# 当 σ→1 时探索无穷大,σ→0 时噪声收敛为 0 以保护高频细节
_noise_level = eta if noise_level is None else noise_level
# SDE 单步标准差 std_dev_t = g(σ)·√(-Δσ)
# (注:代码中把 √(-Δσ) 的计算推迟到了后面,这里的 std_dev_t 实际对应公式里的 g(σ))
# torch.where 是数值稳定防护罩,防止 σ=1 时分母为 0 导致溢出
std_dev_t = (
torch.sqrt(sigma / (1 - torch.where(sigma == 1, sigma_max, sigma)))
* _noise_level
)
# 【公式 ①】Tweedie 反推干净样本: x̂_0 = x_t - σ·v_θ
pred_original_sample = latents - sigma * model_output
# 【公式 ③'】算子融合形式的 SDE 漂移均值 μ
# μ = z_t · (1 + η²/(2(1-σ)) · Δσ) + v_θ · (1 + η²/2) · Δσ
#
# 代入代码变量检验:
# g(σ)²/(2σ) = η²/(2(1-σ)) → 对应代码第一项系数
# g(σ)²·(1-σ)/(2σ) = η²/2 → 对应代码第二项系数
prev_sample_mean = (
latents * (1 + std_dev_t**2 / (2 * sigma) * dt)
+ model_output * (1 + std_dev_t**2 * (1 - sigma) / (2 * sigma)) * dt
)
# 【公式 ④】SDE 采样:x_{next} = μ + g(σ)·√(-Δσ)·ε
if prev_sample is None:
variance_noise = torch.randn(
model_output.shape, generator=generator,
device=device, dtype=model_output.dtype,
)
prev_sample = (
prev_sample_mean + std_dev_t * torch.sqrt(-1 * dt) * variance_noise
)
# ODE 覆盖:determistic=True 时直接用 Euler 步,丢弃上面的 SDE 采样
if determistic:
prev_sample = latents + dt * model_output
# 【公式 ⑤】计算单步对数概率: log N(x_next; μ, g(σ)²|Δσ|)
# 实际离散步长下的标准差 effective_std = g(σ) × √(-Δσ)
effective_std = std_dev_t * torch.sqrt(-1 * dt)
# 完整高斯对数似然包含三项:
# -(x-μ)²/(2σ²) 马氏距离:主信号项
# -log(σ) 方差惩罚项
# -0.5·log(2π) 归一化常数(不影响梯度,用于数值对齐)
log_prob = (
-((prev_sample.detach() - prev_sample_mean) ** 2)
/ (2 * (effective_std ** 2))
- torch.log(effective_std)
- torch.log(torch.sqrt(2 * torch.as_tensor(math.pi, device=device)))
)
# 对所有像素空间维度求均值(详见下方提示框)
log_prob = log_prob.mean(dim=tuple(range(1, log_prob.ndim)))
return (
prev_sample,
pred_original_sample,
log_prob,
prev_sample_mean,
effective_std,
)
else:
raise ValueError(f"Unsupported sde_type: {sde_type}. Must be 'sde'.")工程优势:
- 算子融合(Operator Fusion):完全摒弃了显式计算
Score 和 \(\hat{x}_0\),直接对 \(x_t\) (
latents) 和 \(v_\theta\) (model_output) 乘以标量系数相加,极大提升了 CUDA 上的计算吞吐量。 - 数值稳定性(Robustness):通过
torch.where防护罩,消除了 \(\sigma \to 1\) 时的分母溢出问题。 - 策略梯度完备性:其产生的
log_prob包含了完整的马氏距离和方差惩罚项,确保了 REINFORCE 优化的梯度严谨性。
5. 与 DanceGRPO 的对比
同期的 DanceGRPO 采用了与 Flow-GRPO 相同的 ODE→SDE 改造思路,但在工程实现上有两个关键差异:
| 维度 | Flow-GRPO | DanceGRPO |
|---|---|---|
| 噪声系数 | 自适应 \(g(\sigma) = \sqrt{\sigma/(1-\sigma)} \cdot \eta\) | 恒定 \(g = \eta\) |
| 实现风格 | 算子融合:直接用标量系数乘以 \(x_t\) 和 \(v_\theta\) | 显式分解:逐步计算 \(\hat{x}_0\) → Score → 均值 |
| 数值稳定性 | torch.where 防护 \(\sigma \to 0\) |
直接除以 \(\sigma^2\),末期有崩溃风险 |
DanceGRPO 的真正价值在于将 GRPO 框架推广到了视频生成和 Diffusion 范式,详见 DanceGRPO 与 MixGRPO 专题。
6. 整体框架回顾:与 LLM GRPO 的异同
梳理完完整的 SDE 改造与对数概率推导后,我们可以清晰地看到:Flow-GRPO 与 LLM GRPO 的宏观算法结构(组采样 → 优势计算 → PPO 裁剪更新 → KL 惩罚)是完全一致的。
尽管宏观一致,但受限于连续和离散的状态空间差异,两者在具体细节上仍存在三个核心不同:
- 对数概率 \(\log
\pi_\theta\) 的获取方式(最核心差异):
- LLM(离散空间):直接从模型最后一层的分类头中,按生成的 token 提取 softmax 的对数概率并求和。
- Flow-GRPO(连续空间):基于 SDE 改造,利用每一去噪步的高斯转移核对数密度,按前文的公式 ⑥ 沿着整条轨迹逐步累加,最终得到 \(\log\pi_\theta(\text{trajectory}\mid c)\)。
- 基线(Baseline)估计的维度:
- LLM:LLM 在组内采样的回答长度往往不一致,甚至有些实现会进行 Token 级别的密集奖励(Dense Reward)分配,基线可以在时间步(Token)层面上进行标准化。
- Flow-GRPO:图像生成的步数 \(T\) 始终是固定的,目前主要是在整条轨迹结束后获得一个单一的稀疏标量奖励(如 ImageReward)。因此其优势计算 \(\hat{A}\) 仅仅在组内(空间维度上)对这 \(G\) 个标量进行标准化,缺乏步级(Step-wise)的细粒度信用分配。
- KL 散度惩罚的计算依据:
- LLM:KL 惩罚通常通过近似公式计算当前策略网络和参考网络在各个 Token 上预测概率的 Kullback-Leibler 散度。
- Flow-GRPO:由于无法直接得到整个连续分布的解析 KL 散度,通常使用两个模型预测速度场(Velocity Field)之间的均方误差(MSE,即 \(\|v_\theta - v_\text{ref}\|^2\))来作为 KL 惩罚项的经验近似。
Flow-GRPO-Fast:加速采样的工程优化
全量去噪采样是 Flow-GRPO 的计算瓶颈——生成一张 1024×1024 图像,Flux 默认需要 50 步 ODE 求解。在标准的 Flow-GRPO 训练中,每个 Prompt 哪怕只采 10 步,为了算 \(G=4\) 张图并计算每步的对数概率和反向传播,开销依然非常巨大。
为此,官方代码库提出了一种极具启发性的加速变体:Flow-GRPO-Fast。 它的核心思想是:将随机探索(SDE)限制在极少的 1~2 步内,其余部分全部使用确定性 ODE 快速跳过。
具体生成与训练过程如下:
- 前期 ODE 确定性跨越:首先使用确定性的 ODE 采样,从纯噪声开始走到一个随机选择的中间时间步 \(t_{\text{start}}\)。因为是确定性的,这里只需要生成 1 条共享的轨迹底底子,不需要生成 \(G\) 份。
- 中间切入与单步 SDE 展开:在到达 \(t_{\text{start}}\) 时,突然向这 1 条轨迹中注入不同的随机噪声,并切换到 SDE 采样走 1 步(或 2 步)。就在这短短的 1~2 步里,原本的 1 条轨迹分裂成了 \(G\) 条不同的微小变体。
- 后期 ODE 快速收尾:完成这关键的 SDE 分裂后,后续所有的去噪步骤又重新切回确定性的 ODE 采样,直到生成最终的 \(G\) 张图像。
为什么它能大幅加速? 因为 SDE 的对数概率计算和 PPO 梯度反传仅仅发生在那 1~2 步 SDE 注入的阶段。模型不需要对整条轨迹计算对数概率,大大节省了显存和反向传播的计算量。
Flow-GRPO-Fast 的局限性:为什么还需要 MixGRPO?
虽然 Flow-GRPO-Fast 的加速思路极具启发性,但它存在三个严重的结构性缺陷,使得直接使用时性能显著下降(MixGRPO 论文 Figure 1 实验验证:随着训练步数减少,DanceGRPO/Flow-GRPO-Fast 的性能急剧退化):
1. 随机注入点导致梯度信号极度稀疏且不稳定
Flow-GRPO-Fast 每次随机选择一个中间时间步 \(t_\text{start}\) 注入 SDE。对于一条 25 步的去噪轨迹,仅有 1~2 步(4%~8%)接收梯度更新,剩余 92%~96% 的时间步完全无法被优化。更关键的是,由于注入点是随机的,不同 iteration 的梯度可能作用在完全不同的时间区段上,导致优化方向高度随机、收敛极不稳定。
2. 无课程调度导致时间步覆盖不均匀
去噪过程中,不同时间步负责截然不同的语义信息:高噪声步(\(\sigma\) 接近 1)决定全局构图和物体布局,低噪声步(\(\sigma\) 接近 0)决定纹理细节和高频信息。Flow-GRPO-Fast 的随机选择无法保证所有时间段都被充分优化,某些关键区间可能长期被遗漏,导致训练后的模型在这些时间段的行为与原始模型无异。
3. 不支持后期高阶加速
由于 Flow-GRPO-Fast 的 SDE 注入点是随机的,后期 ODE 阶段的起始位置不确定,因此无法安全地引入 DPM-Solver++ 等高阶求解器进行加速(原因见下方提示框)。
MixGRPO 的系统性解决方案(Li et al., arXiv:2507.21802)将 Flow-GRPO-Fast 的随机单步升级为系统性滑动窗口,从根本上解决了上述三个问题:
| 问题 | Flow-GRPO-Fast | MixGRPO |
|---|---|---|
| 窗口位置 | 每次随机选择 \(t_\text{start}\) | 固定窗口 \(W(l)\),从高噪声逐步滑向低噪声 |
| 窗口大小 | 1~2 步 | \(w = 4\) 步(实验验证的最优值) |
| 覆盖策略 | 无保证(完全随机) | 渐进式课程学习:先优化全局结构,再精修细节 |
| 后期加速 | 不可用 | MixGRPO-Flash:窗口后方 ODE 可用 DPM-Solver++ |
| ref_model | 需要冻结参考模型计算 KL | 不需要,用推理时混合采样替代 |
MixGRPO 的滑动窗口调度符合 RL 中从难到易的课程学习直觉:高噪声步的探索空间最大(t-SNE 可视化显示数据分布更离散),优先优化这些步可以更快锁定全局最优方向;随后逐步滑向低噪声步精修细节。最终,MixGRPO 仅用 4 步训练即可超越 DanceGRPO 全步优化的效果,训练时间削减 50%,MixGRPO-Flash 进一步削减 71%。
训练主循环:完整 Pipeline 解析
前面我们已经逐一解析了 SDE 单步更新(公式 ①-⑥)和 log_prob
的计算方法。现在让我们跳出单步视角,审视整个训练流程是如何将这些组件串联起来的。以下代码基于
flow_grpo 的
train_sd3_GRPO_Guard.py 和 MixGRPO 的
train_grpo_flux.py 两个官方实现,提取出核心主循环逻辑。
整体架构:Flow-GRPO / MixGRPO 的训练遵循经典的 On-Policy RL 范式——"采样 → 评估 → 更新"的循环迭代:
"""
Flow-GRPO / MixGRPO — 流匹配模型的组相对策略优化
论文: Flow-GRPO (arXiv:2505.05470), MixGRPO (arXiv:2507.21802)
⚡ 相对文本 GRPO 的关键改动(共 5 处):
1. 策略: 自回归 LM → Flow Transformer v_θ(x_t, t)
2. 动作: 离散 token → 连续去噪步 x_{t-Δ}
3. log_prob: log_softmax+gather → log N(x; μ_θ, σ²I)
4. 采样: 全程 SDE → 混合 ODE+SDE(MixGRPO,只在训练窗口走 SDE)
5. KL: f-散度+ref_model → 推理时混合采样(MixGRPO,省一半显存)
分布式架构(MixGRPO 默认: 4节点×8卡=32 GPU):
每卡: 1 prompt → 串行生成 G=12 张图 → 组内 z-score → backward
多卡: 32 卡处理 32 个不同 prompt(数据并行)
累积: grad_accum=3 → 等效 batch = 32×3 = 96 prompt
"""
import torch, math
# ── 初始化 ────────────────────────────────────────────
transformer = FlowTransformer(...) # 速度场模型 v_θ(x, t)
vae = VAE(...) # latent ↔ 图像
reward_fn = ImageRewardModel(...)
optimizer = AdamW(transformer.parameters(), lr=1e-6)
# ── 超参数 ────────────────────────────────────────────
G = 12 # 每 prompt 采样 G 张图
clip_range = 1e-4 # PPO ratio 裁剪
adv_clip = 5.0 # 优势截断
eta = 0.7 # SDE 噪声强度
num_steps = 25 # 去噪步数
window_size = 4 # 滑动窗口宽度
iters_per_win = 25 # 窗口停留步数
grad_accum = 3 # 梯度累积
kl_coeff = 0.0 # Flow-GRPO: 0.004; MixGRPO: 0.0
ref_transformer = None # kl_coeff>0 时需要冻结的参考模型
# σ 调度: [1→0],经 SD3 time shift 变换
# σ' = shift·σ / (1 + (shift-1)·σ)
sigmas = sd3_time_shift(3.0, linspace(1, 0, num_steps+1))
# ── 训练循环 ──────────────────────────────────────────
win_start = 0
for step in range(50000):
# === Phase 1: 组采样(冻结策略,生成轨迹)===
transformer.eval()
prompt = next(dataloader)
win = range(win_start, min(win_start + window_size, num_steps))
with no_grad():
x0 = randn(1, C, H, W) # 组内共享初始噪声
all_x = [] # 存 G 条完整轨迹
all_lp = [] # 存 G 条 log_prob 序列
for g in range(G): # 串行 G 张图
x = x0.clone()
x_traj = [x] # 第 g 张图的轨迹
lp_traj = [] # 第 g 张图的 log_prob
for i in range(num_steps):
v = transformer(x, t=sigmas[i])
if i in win: # 窗口内: SDE(有随机性)
x, lp = sde_step(v, x, sigmas[i], sigmas[i+1], eta)
else: # 窗口外: ODE(确定性)
x = x + (sigmas[i+1] - sigmas[i]) * v # Euler ODE
lp = 0
x_traj.append(x)
lp_traj.append(lp)
all_x.append(stack(x_traj)) # (T+1, C, H, W)
all_lp.append(stack(lp_traj)) # (T,)
all_x = stack(all_x) # (G, T+1, C, H, W)
all_lp = stack(all_lp) # (G, T)
images = vae.decode(all_x[:, -1]) # 解码最终 latent → 图像
scores = reward_fn(images, prompt) # (G,)
# === Phase 2: 优势估计(与文本 GRPO 完全相同)===
# Â_i = (r_i - μ_R) / (σ_R + ε)
advantages = group_zscore(scores, G) # (G,)
# === Phase 3: PPO 更新(只更新窗口内 timestep)===
transformer.train()
loss = 0
for i in win: # ← 只遍历训练窗口!
x_t = all_x[:, i] # Phase 1 记录的第 i 步 latent
x_next = all_x[:, i+1] # Phase 1 记录的第 i+1 步(固定 action)
v_new = transformer(x_t, t=sigmas[i]) # 当前策略的速度场
# 用当前策略重算 μ_new,但 x_next 固定(off-policy correction)
log_prob_new = sde_log_prob(v_new, x_t, x_next, sigmas[i], sigmas[i+1], eta)
# PPO Clip(逐去噪步,对应文本 GRPO 的逐 token)
ratio = exp(log_prob_new - all_lp[:, i])
adv = clamp(advantages, -adv_clip, adv_clip)
loss += max(-adv * ratio,
-adv * clamp(ratio, 1-clip_range, 1+clip_range)).mean()
# KL 惩罚(Flow-GRPO 可选,MixGRPO 不需要)
if kl_coeff > 0:
with no_grad():
v_ref = ref_transformer(x_t, t=sigmas[i])
loss += kl_coeff * mse(v_new, v_ref)
(loss / len(win) / grad_accum).backward() # 累积梯度
if (step+1) % grad_accum == 0: # 多卡 FSDP 同步
clip_grad_norm_(transformer.parameters(), 1.0)
optimizer.step(); optimizer.zero_grad()
if step % iters_per_win == 0: # 窗口滑动
win_start = min(win_start + 1, num_steps - window_size)对应的 SDE 步进和 log_prob 计算函数(即前文公式 ③'④⑤ 的精简实现):
def sde_step(v, x, sigma, sigma_next, eta):
"""采样时调用: 生成新样本 + 计算 log_prob"""
dt = sigma_next - sigma # Δt < 0
sigma_noise = eta * sqrt(sigma / (1 - sigma)) # g(σ) = η·√(σ/(1-σ))
mu = x * (1 + sigma_noise**2 / (2*sigma) * dt) \
+ v * (1 + sigma_noise**2 * (1-sigma) / (2*sigma)) * dt
std = sigma_noise * sqrt(-dt)
x_next = mu + std * randn_like(x) # x_next ~ N(μ, std²I)
# log N(x_next; μ, std²I)
log_prob = -((x_next - mu)**2 / (2 * std**2) + log(std) + 0.5*log(2*pi)).mean()
return x_next, log_prob
def sde_log_prob(v, x, x_next, sigma, sigma_next, eta):
"""更新时调用: x_next 固定,只重算 log_prob"""
dt = sigma_next - sigma
sigma_noise = eta * sqrt(sigma / (1 - sigma))
mu = x * (1 + sigma_noise**2 / (2*sigma) * dt) \
+ v * (1 + sigma_noise**2 * (1-sigma) / (2*sigma)) * dt
std = sigma_noise * sqrt(-dt)
return -((x_next - mu)**2 / (2 * std**2) + log(std) + 0.5*log(2*pi)).mean()GRPO-Guard:缓解隐式过优化
论文:GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping(同为 Flow-GRPO 团队,2025) 代码:已集成在 flow_grpo 和 Flow-Factory 中
问题:Importance Ratio 的固有偏差
Flow-GRPO 和 DanceGRPO 在训练中使用 PPO-style clipping 来约束策略更新。PPO 的 clipping 机制假设 importance ratio \(r_t = \pi_\theta(a_t|s_t) / \pi_{\theta_\text{old}}(a_t|s_t)\) 的分布以 1 为中心。但在 Flow Matching 模型中,importance ratio 的分布存在系统性的负向偏差:
- 均值始终低于 1,在低噪声步(如 SD3.5-M 的 step 8)偏差尤为显著。
- 方差在不同去噪步之间差异极大,对于对数比率 \(\log r_t\),低噪声步的方差远大于高噪声步。
为什么偏差是"负向"的?——完整推导
以下逐步推导 \(\mathbb{E}[\log r_t] < 0\) 的数学成因。
第一步:写出对数概率密度。 在 Flow-GRPO 的 SDE 框架中,每步转移的策略 \(\pi\) 是各向同性高斯分布 \(\pi(x_t) = \mathcal{N}(x_t \mid \mu,\; \sigma_t^2 I)\),其对数密度为(省略与 \(\mu\) 无关的常数项):
\[\log \pi(x_t) = -\frac{\|x_t - \mu\|^2}{2\sigma_t^2} + \text{const}\]
第二步:写出对数 Importance Ratio。 令 \(\delta = \mu_\theta - \mu_{\theta_\text{old}}\)(策略更新导致的均值偏移),对数重要性比为:
\[\log r_t = \log\frac{\pi_\theta(x_t)}{\pi_{\theta_\text{old}}(x_t)} = -\frac{\|x_t - \mu_\theta\|^2}{2\sigma_t^2} + \frac{\|x_t - \mu_{\theta_\text{old}}\|^2}{2\sigma_t^2}\]
第三步:展开范数平方(配方法)。 将 \(\mu_\theta = \mu_{\theta_\text{old}} + \delta\) 代入第一项:
\[ \begin{aligned} \|x_t - \mu_\theta\|^2 &= \|(x_t - \mu_{\theta_\text{old}}) - \delta\|^2 \\[4pt] &= \|x_t - \mu_{\theta_\text{old}}\|^2 - 2(x_t - \mu_{\theta_\text{old}})^T\delta + \|\delta\|^2 \end{aligned} \]
第四步:代入相消。 代回对数比后,\(\|x_t - \mu_{\theta_\text{old}}\|^2\) 项完美抵消:
\[ \begin{aligned} \log r_t &= \frac{2(x_t - \mu_{\theta_\text{old}})^T\delta - \|\delta\|^2}{2\sigma_t^2} \\[6pt] &= \frac{(x_t - \mu_{\theta_\text{old}})^T\delta}{\sigma_t^2} - \frac{\|\delta\|^2}{2\sigma_t^2} \end{aligned} \]
第五步:定义残差 \(e\) 得到最终形式。 令 \(e = x_t - \mu_{\theta_\text{old}}\)(旧策略下的采样残差,满足 \(\mathbb{E}[e] = 0\),\(\text{Cov}(e) = \sigma_t^2 I\)):
\[\boxed{\log r_t = \underbrace{\frac{e^T\delta}{\sigma_t^2}}_{\text{零均值随机项}} - \underbrace{\frac{\|\delta\|^2}{2\sigma_t^2}}_{\text{恒负偏置项}}}\]
各项的物理意义:
- 第一项 \(\frac{e^T\delta}{\sigma_t^2}\):策略偏移方向 \(\delta\) 上的随机投影。由于 \(\mathbb{E}[e] = 0\),该项期望为零——它只贡献方差 \(\text{Var} = \|\delta\|^2 / \sigma_t^2\),不贡献均值偏移。
- 第二项 \(-\frac{\|\delta\|^2}{2\sigma_t^2}\):来源于配方法展开中不可避免的交叉项 \(\|\delta\|^2\),总是非正的。只要策略发生了任何更新(\(\delta \neq 0\)),该项就严格为负。
因此 \(\mathbb{E}[\log r_t] = -\frac{\|\delta\|^2}{2\sigma_t^2} < 0\),即无论策略往哪个方向更新,对数比的期望都一定是负的。在高维 latent 空间中(\(d \sim 65536\)),\(\|\delta\|^2\) 随维度累积,导致 \(\log r_t\) 取到很大的负值。由于 \(r_t = e^{\log r_t}\),大负数的指数趋近于 0,使得经验均值 \(\mathbb{E}[r_t]\) 远低于其理论值 1。同时,\(\text{Var}[\log r_t] = \|\delta\|^2 / \sigma_t^2\) 在低噪声步(\(\sigma_t\) 小)时极大,进一步破坏 PPO clipping 的对称性。
这种偏差使得 PPO 的 clipping 区间 \([1-\varepsilon, 1+\varepsilon]\) 变得不对称。由于绝大多数样本的 \(r_t\) 远小于 1,正样本(高奖励的好图)的 ratio 反而更容易落在 clipping 区间内部(不被截断),导致正样本的梯度更新不受约束,策略模型不断向这些样本偏移。
解决方案:RatioNorm + Gradient Reweight
GRPO-Guard 提出了两个互补的机制:
1. RatioNorm(比率归一化)
RatioNorm 的目标是纠正 importance ratio 的分布偏差,使其均值回归到 1、方差在不同步之间保持一致。
具体做法是引入一个时间步相关的缩放因子 \(c_t = \sqrt{\Delta t} \cdot
\sigma_t\)(其中 \(\Delta t\)
是步长,\(\sigma_t\)
是前向加噪的噪声标准差,对应代码中的 sigma,而非 SDE
探索噪声 \(g\)),并用它来重新缩放
log-ratio:
\[\hat{r}_t = \exp\left[({\log \pi_\theta - \log \pi_{\theta_\text{old}}}) \cdot c_t + \frac{\|\mu_\theta - \mu_{\theta_\text{old}}\|^2}{2 c_t}\right]\]
这个公式在数学上完美呼应了前文发现的两个缺陷: 1. 乘法因子 \(c_t\):用于将不同时间步的方差缩放对齐,解决“低噪声步方差极大、高噪声步方差极小”的问题。 2. 加法补偿项 \(\frac{\|\mu_\theta - \mu_{\theta_\text{old}}\|^2}{2 c_t}\):这里的分子 \(\|\mu_\theta - \mu_{\theta_\text{old}}\|^2\) 正是前文推导中的 \(\|\delta\|^2\)。该项被精确设计用来抵消高斯分布带来的负向常数偏置 \(\mathbb{E}[\log r_t] = -\frac{\|\delta\|^2}{2\sigma_t^2}\),从而解决“均值始终低于 1”的问题。
经过 RatioNorm 校正后,importance ratio 的分布在所有时间步上都以 1 为中心,PPO 的 clipping 机制重新恢复了对称性。
2. Gradient Reweight(梯度重加权)
即使 RatioNorm 校正了 ratio 的分布,不同时间步对总 loss 的梯度贡献仍然不均衡。Gradient Reweight 对最终的 policy loss 进行时间步相关的重加权:
\[\mathcal{L}_\text{Guard} = \frac{\mathcal{L}_\text{PPO}(\hat{r}_t)}{(\sqrt{\Delta t})^2}\]
这使得每个时间步对总梯度的贡献大致相等,防止某些特定噪声水平下的过度优化。
与 MixGRPO 的对比:哪个更好?
GRPO-Guard 与 MixGRPO 都试图解决 Flow-GRPO 的过优化/Reward Hacking 问题,但它们解决的是不同层面的问题,严格来说不构成"谁更好"的竞争关系,而是互补关系。
切入点完全不同:
- GRPO-Guard 从梯度端入手:认为问题的根源是 SDE 使 importance ratio 的统计特性产生了偏差,导致 PPO clipping 失效。解决方法是 RatioNorm + Gradient Reweight。
- Flow-CPS 与 MixGRPO 从采样端入手:解决 SDE 带来的副作用。Flow-CPS 提出了系数保持采样(消除高频伪影);而 MixGRPO 则引入了滑动窗口(Mixed ODE-SDE)来提升训练效率,并结合原始模型推理限制伪影传播。
各自的优势领域:
- 抗过优化能力:GRPO-Guard 是专门为此设计的。GRPO-Guard 论文的实验表明,在 SD3.5-M 上以 GenEval 为 proxy reward 训练 1860 步后,Flow-GRPO 的 Gold Score(三项真实指标 HPS-v2、ImageReward、UnifiedReward 的归一化均值)跌至 0.84(基线 = 1.00),而 GRPO-Guard 维持在 0.89(提升 +0.05)。在 Flux.1-dev 上,DanceGRPO 的 Gold Score 跌至 0.88,GRPO-Guard 则恢复到 1.02(甚至超过原始模型)。视觉上,Flow-GRPO 和 DanceGRPO 在训练后期会出现严重的水平/垂直条纹伪影、面部同质化和人体比例失调,而 GRPO-Guard 保持了正常的图像质量和多样性。
- 训练效率:MixGRPO 在这方面优势明显,通过 Mixed ODE-SDE + 滑动窗口机制将训练开销削减了约 50%,同时在 ImageReward 和 HPS-v2.1 等指标上超越了 Flow-GRPO 和 DanceGRPO。
GRPO-Guard 的局限(论文自己承认的):RatioNorm 只能修复 clipping 机制的失效问题,无法消除奖励模型本身的固有缺陷(proxy score 与 gold score 之间的 gap)。如果奖励模型本身就有系统性偏见,单纯修复 clipping 也无法完全阻止 reward hacking。更根本的解决方案是提升奖励模型本身的能力(如 RewardDance),但这会引入大量计算开销。
实际使用建议:这两种方法并不互斥,可以组合使用。Flow-Factory
已经同时支持了两者,用户可以选择 trainer_type: 'grpo-guard'
+ dynamics_type: 'CPS',将梯度端的 ratio
修正与采样端的伪影消除同时启用,理论上能获得最佳的抗过优化效果。
算法对比与开源生态
| 维度 | Diffusion-DPO | DDPO (PPO) | Flow-GRPO |
|---|---|---|---|
| 训练方式 | 离线(偏好对) | 在线 RL | 在线 RL |
| 探索与优化机制的数学本质 | 基于轨迹 KL 散度的闭式解 | 基于单步高斯转移的 REINFORCE | 基于 SDE 轨迹对数似然的 PPO/GRPO |
| 需要 Critic | 否 | 是 | 否 |
| 基线估计 | 无 | Critic \(V_\phi\) | 组内均值 |
| 适用模型 | DDPM / LDM | DDPM / LDM | Flow Matching (Flux) |
| 显存 | 低 | 极高 | 低 |
| 探索能力 | 弱 | 强 | 强 |
开源代码参考: flow_grpo 提供了基于 Flux 的完整实现,支持 LoRA 微调、多 GPU 训练和 Flow-GRPO-Fast 加速。
系列总结
通过这五篇文章,我们从最基础的强化学习与策略梯度出发,推导了解决步长控制的 PPO 算法,探讨了绕开 RL 的 DPO 路线,最终迎来了解决大模型显存危机的 GRPO 算法,并成功将其落地到了最前沿的 Flow-GRPO 图像生成微调框架中。
强化学习与生成模型的结合,正在开启 AI 领域的新纪元。无论是语言模型中的深度思考(DeepSeek-R1),还是图像生成中的美学对齐(Flow-GRPO),在线强化学习都展现出了无与伦比的潜力。
参考资料:
- Liu, Y., Wang, P., Shao, Z., ... & Hao, K. (2025). Flow-GRPO: Training Flow Matching Models via Online RL. arXiv:2505.05470.
- Black Forest Labs. (2024). Flux.1 [dev]. https://blackforestlabs.ai/
- flow_grpo
- Wang, J., et al. (2025). GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping. arXiv:2510.22319.