笔记|强化学习(八):SuperFlow 与图像生成 RL 前沿(2026)
本文为 RL 系列的图像生成篇。在第五篇中我们介绍了 Flow-GRPO,将 GRPO 应用于基于 Flow Matching 的图像生成。本文将介绍其后续改进 SuperFlow,以及 2026 年图像/视频生成 RL 的统一框架生态,最后回顾整个系列的完整技术脉络。
论文:SuperFlow: Training Flow Matching Models with RL on the Fly(2025.12, revised 2026.01)
Flow-GRPO 的三个遗留问题
延续之前"橘猫坐在蓝色沙发上"的例子。 Flow-GRPO 的做法是:对每个 Prompt 生成 \(G\) 张图像,用奖励模型打分,算出组内相对优势,然后用策略梯度更新模型。这个流程在大规模训练时暴露出三个问题:
问题一:固定组大小导致计算浪费。 所有 Prompt 都生成固定 \(G = 16\) 张图,但太简单(16 张全满分)或太难(16 张全低分)的题目,组内方差 \(\sigma_R \approx 0\),优势值全为 0,梯度为 0——模型完全没有更新,而图像生成的 50 步 SDE 求解已白白消耗了昂贵的 GPU 算力。
问题二:轨迹级优势的"一刀切"。 Flow-GRPO 将最终奖励平均分配给去噪的每一步,但前期(定构图,\(\sigma_t\) 大)和后期(修细节,\(\sigma_t\) 小)对最终结果的贡献天差地别。这是经典的信用分配(Credit Assignment)问题。
问题三:训练后期的"躺平"。 后期模型能力整体提升,对同一 Prompt 生成的图都很完美,组内方差再次趋零,优势信号消失,训练停滞甚至崩溃。
SuperFlow 的三项改进
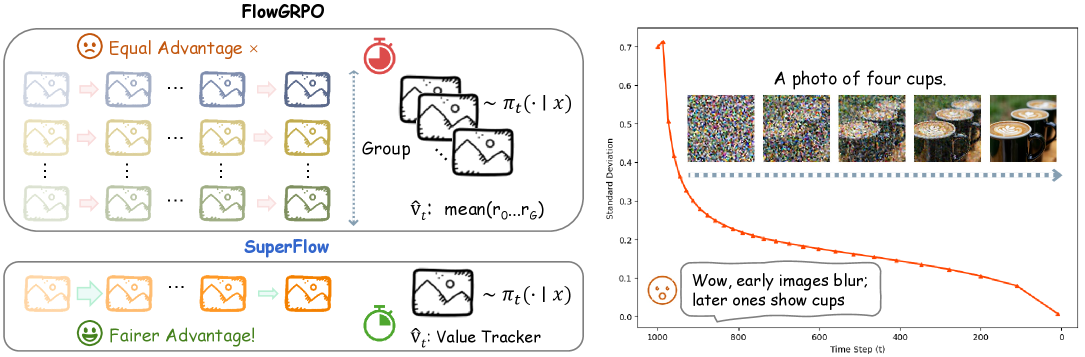
改进一:方差感知的动态采样(把算力花在刀刃上)
核心思路:用 Beta 分布追踪每个 Prompt 的历史得分率,据此动态分配算力。
SuperFlow 为每个 Prompt \(c\) 维护两个计数器——\(\alpha(c)\)(累积成功次数)和 \(\beta(c)\)(累积失败次数),用带遗忘因子 \(\rho\) 的指数滑动平均更新(确保反映模型当前水平而非历史包袱):
\[ \alpha \leftarrow \rho \cdot \alpha + r, \quad \beta \leftarrow \rho \cdot \beta + (1 - r) \]
其中 \(r \in [0,1]\) 是归一化后的奖励(连续奖励被拆分为"\(r\) 次成功"和"\(1-r\) 次失败")。历史平均得分率为 \(\hat{v}(c) = \frac{\alpha}{\alpha + \beta}\)。
不确定性 → 动态算力分配:将不确定性定义为伯努利标准差 \(w(c) \propto \sqrt{\hat{v}(c)(1 - \hat{v}(c)) + \epsilon}\),然后按 \(w(c)\) 分级分配组大小:
- \(\hat{v}(c) \approx 0.5\)(半会半不会)→ \(w(c)\) 最大 → 分配最多的 rollout,重点训练
- \(\hat{v}(c) \approx 0\) 或 \(1\)(太难或太简单)→ \(w(c)\) 极小 → 缩减 rollout,节省算力
| Prompt | 历史得分率 \(\hat{v}(c)\) | 不确定性 \(w(c)\) | 组大小 \(m(c)\) |
|---|---|---|---|
| "一只猫"(太简单) | 0.95 | 低 | 21 张(省算力) |
| "橘猫坐蓝色沙发"(中等) | 0.55 | 最高 | 24 张(满配) |
| "穿西装猫弹钢琴"(太难) | 0.05 | 低 | 21 张(省算力) |
改进二:步级优势重估计(按劳分配)
SuperFlow 不再对所有时间步使用同一个优势值,而是根据每一步的扩散噪声大小 \(\sigma_t\) 来分配功劳:
\[ \hat{A}_t = \eta \cdot \sigma_t \cdot A_\tau \]
其中 \(A_\tau\) 是整张图的最终优势值,\(\sigma_t\) 是第 \(t\) 步的 SDE 噪声标准差,\(\eta\) 是缩放系数。
| 时间步 \(t\) | \(\sigma_t\) | \(\hat{A}_t\) | 含义 |
|---|---|---|---|
| \(t = 10\)(从纯噪声开始) | 0.8 | \(1.2\eta\) | 选择构图方向 → 高权重 |
| \(t = 5\)(中间步) | 0.3 | \(0.45\eta\) | 细化结构 → 中权重 |
| \(t = 1\)(接近成品) | 0.05 | \(0.075\eta\) | 调整细节 → 低权重 |
为什么按 \(\sigma_t\) 而非确定性步伐分配? 确定性步伐(\(\Delta t \cdot v_\theta\))是模型"本来就会做的事",无法解释为什么这次生成的图"比平时更好"。真正产生好坏差异的是 SDE 注入的随机噪声——前期 \(\sigma_t\) 大,一次"大赌博"改变了构图,对最终高分居功至伟;后期 \(\sigma_t\) 极小,只改了一根猫毛,贡献微乎其微。
改进三:运行基线替代纯组相对
SuperFlow 用 Beta 追踪器 \(\hat{v}(c)\) 作为每 Prompt 的运行基线,而非纯粹依赖组内均值:
\[ A(c, y) = r(c, y) - \hat{v}(c) \]
为什么更好? 传统组内均值 \(\mu_R = \frac{1}{G}\sum r_i\) 仅基于当前 \(G\) 张图,估计不稳定。而 \(\hat{v}(c)\) 综合了历史信息,更准确。更关键的是,它打破了零方差死局——即使当前组内都考了 99 分,只要历史基线是 90 分,模型依然能获得 \(+9\) 分的正向激励,不会"躺平"。
SuperFlow 的训练效果
在 SD3.5-Medium 骨干上使用 LoRA(\(r = 32\),\(\alpha = 64\))进行 RL 训练:
| 方法 | GenEval 综合 | OCR 准确率 | PickScore |
|---|---|---|---|
| SD3.5-M(基线) | 0.5814 | 0.5717 | 0.8304 |
| Flow-GRPO | 0.7829 | 0.7252 | 0.8536 |
| Flow-SPO | 0.7540 | 0.7652 | 0.8516 |
| SuperFlow | 0.8045 | 0.8413 | 0.8685 |
SuperFlow 在 OCR(图像中的文字渲染)上提升最为显著——相比 SD3.5-M 提升 47.2%,相比 Flow-GRPO 提升 16.0%。训练效率方面,比 Flow-GRPO 减少了 5.4%-56.3% 的训练步数。
消融实验显示,步级优势重估计对 OCR 贡献最大(移除后下降 16.4%),动态采样对训练稳定性贡献最大(移除后后期出现性能崩溃)。
2026 年图像/视频生成 RL 的统一框架
SuperFlow 之外,两个开源框架正在将图像/视频生成的 RL 训练推向工程化:
Flow-Factory:模块化统一框架,支持 Flux/Qwen-Image/WAN Video 等模型,FlowGRPO/MixGRPO/CPS/AWM 等算法,覆盖 T2I、T2V、I2V 三种模态。核心设计是解耦算法、模型和奖励。
GenRL:覆盖 T2I/T2V/I2V 三种模态,支持 diffusion 和 rectified flow 两种范式,提供约 20 万条 RL 训练 Prompt 和多节点 FSDP 分布式训练支持。
TRL v1.0(Hugging Face, 2026.03):将 TRL 升级为生产级框架,三阶段流水线(SFT → Reward Modeling → Alignment)支持 DPO、GRPO、KTO 等主流算法。但注意 TRL v1.0 主要面向 LLM/VLM,对 Flow Matching 图像/视频生成 RL,Flow-Factory 和 GenRL 才是专用框架。
至此,从 REINFORCE 到 SuperFlow 的图像/视频生成技术旅程暂告一段落。
参考资料: